every blog every motto: You can do more than you think.
https://blog.csdn.net/weixin_39190382?type=blog
0. 前言
Kmeans梗概
1. 正文
1.1 简介
简单来说,对于一堆数据,先选出k个样本作为簇中心,并所有样本到他们的距离,根据距离远近,划分到其中最近的一个簇中心;对于得到的各个簇,计算他们各自的平均值作为新的簇中心,重复上面过程,直到簇中心变化趋于稳定。即完成了对数据的聚类。
整体过程也比较好理解。
1.2 步骤
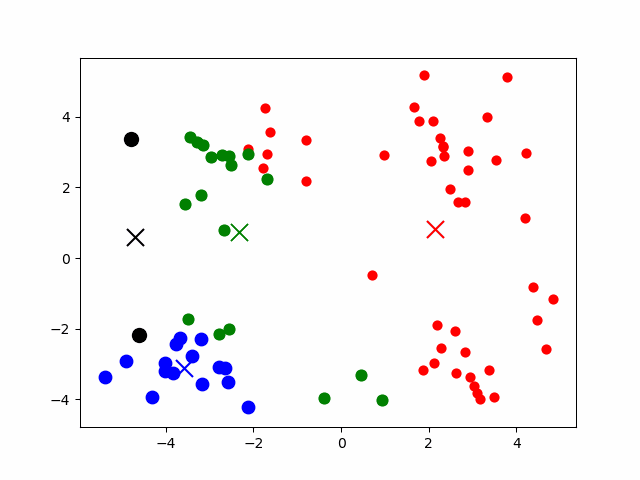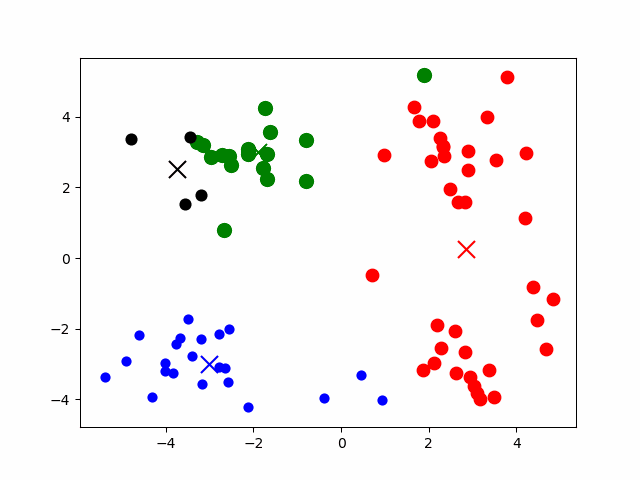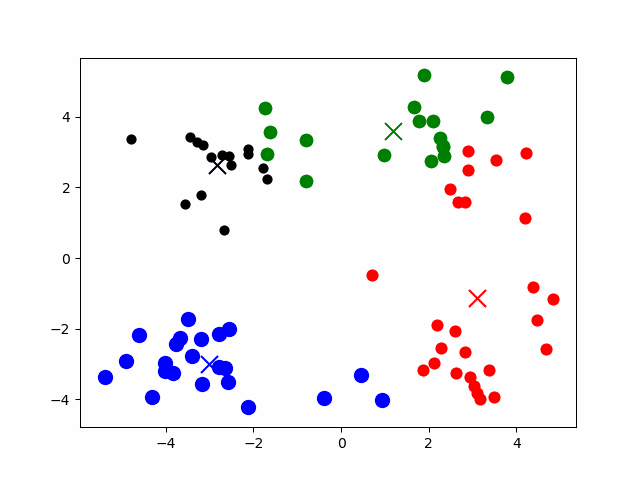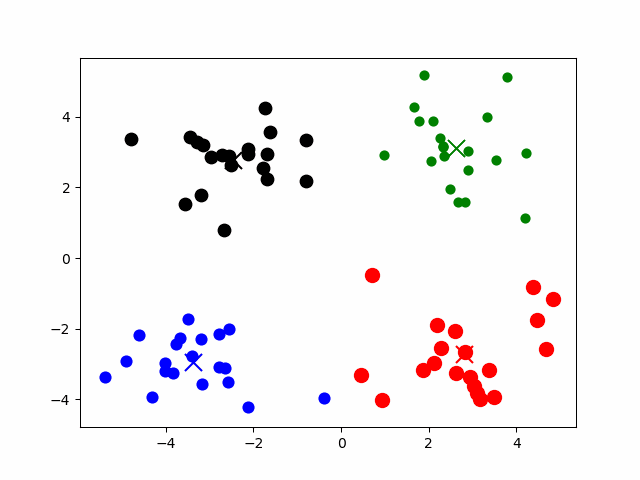
- 数据预处理,主要为:数据标准化和异常点过滤。
- 随机选取k个中心
- 计算样本到k个中心的距离,将其分配到最近的某个中心
- 对于上面划分出的的若干个类,重新计算各类的中心
- 重复上面3、4步,直到最后中心稳定。
1.3 k的选择
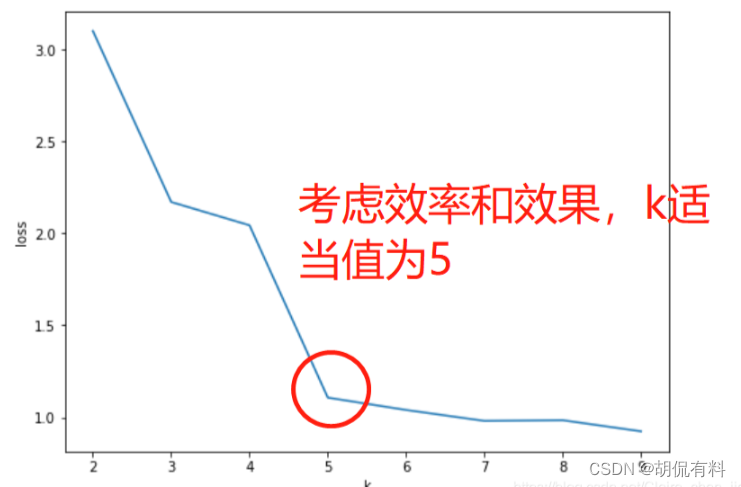
1.3.1 拐点法(手肘法)
计算不同k值下,距离平方和,随着k值的增加,距离会逐渐变小。当斜率突然由大变小时,且之后变化缓慢,则认为k值为合适的kz值。
1.3.2 轮廓系数
每个样本都有对应的轮廓系数,其有两部分组成:
- 样本与同一簇类(类内)中其他样本点的平均距离(量化凝聚度)
- 样本与距离最近的簇类(类间)中所有的样本平均聚类(量化分类度)
S = b − a m a x ( a , b ) S = {b-a \over max(a,b)} S=max(a,b)b−a
S取值为[-1,1]
一组数据集中轮廓系数:等于该数据集中每个样本的轮廓系数的平均值
1.4 优缺点
(1).优点
- 属于无监督学习,不需要标签
- 原理简单,实现容易
- 结果可解释性好
(2).缺点
- 聚类数据k的选取,选择不当可能得到不理想的结果
- 可能收敛到局部最优,在大规模数据上收敛较慢
- 对噪声、异常点比较敏感
1.5 算法改进
主要有以下方法(暂时不展开)
- kmeans++
- 二分kmeans
- minbatchKmeans
参考
[1] https://blog.csdn.net/Claire_chen_jia/article/details/111060253#t2
[2] https://blog.csdn.net/weixin_45788069/article/details/108853816#t3
[3] https://blog.csdn.net/qq_43741312/article/details/97128745#t11
[4] https://zhuanlan.zhihu.com/p/432230028
[5] https://www.zhihu.com/tardis/zm/art/158776162?source_id=1005
[6] https://zhuanlan.zhihu.com/p/184686598