聚类算法:KMEANS原理介绍
一、 聚类介绍
聚类分析是一个无监督学习过程,一般是用来对数据对象按照其特征属性进行分组,经常被应用在客户分群、欺诈检测、图像分析等领域。K-means应该是最有名并且最经常使用的聚类算法。
二、 算法介绍
KMeans算法的基本思想是初始随机给定K个簇中心,按照最邻近原则把待分类样本点分到各个簇,然后按照平均法重新计算各个簇的质心,从而确定簇心,一直迭代,知道簇心的移动距离小于某个给定的值。
K-means 算法是一个迭代式的算法,其运算过程如下:
1、 选择k个点作为初始聚类中心。(k需要我们程序自己设置)
2、 计算其余所有点到聚类中心的距离,并把每个点划分到离它最近的聚类中心所在的聚类中。最常用的衡量距离的函数式欧几里得距离,叫做欧式距离。sqrt(x1-x2)2+(y1-y2)2)
3、 重新计算每个聚类中所有点的平均值,并将其作为新的聚类中心点。
4、 重复2,3步的过程,直至聚类中心不再发生变化,或者算法达到预定的迭代次数(程序自己设置),又或者聚类中心的改变小于预定设定的阀值。
关于一些数学公式的推荐看下面的这篇
https://blog.csdn.net/taoyanqi8932/article/details/53727841
举个例子介绍:

从上图中,我们可以看到,A,B,C,D,E是五个在图中点。而灰色的点是我们的种子点,也就是我们用来找点群的点。有两个种子点,所以K=2。
K-Means的算法如下:
1、随机在图中取K(这里K=2)个种子点。
2、然后对图中的所有点求到这K个种子点的距离,假如点Pi离种子点Si最近,那么Pi属于Si点群。(上图
中,我们可以看到A,B属于上面的种子点,C,D,E属于下面中部的种子点)
3、接下来,我们要移动种子点到属于他的“点群”的中心。(见图上的第三步)
4、然后重复第2)和第3)步,直到,种子点没有移动(我们可以看到图中的第四步上面的种子点聚合了A,
B,C,下面的种子点聚合了D,E)。
三、 KMeans两个重要问题
1、 选择K值
K 的选择是 K-means 算法的关键,Spark MLlib 在 KMeansModel 类里提供了 computeCost 方法,该方法通过计算所有数据点到其最近的中心点的平方和来评估聚类的效果。一般来说,同样的迭代次数和算法跑的次数,这个值越小代表聚类的效果越好。但是在实际情况下,我们还要考虑到聚类结果的可解释性,不能一味的选择使 computeCost 结果值最小的那个 K。
2、 初始聚类中心点的选择
对于初始化聚类中心点,我们可以在输入的数据集中随机地选择K个点作为中心点,但是随机选择初始中心点可能会造成聚类的结果和数据的实际分布相差很大。所以我们一般选择k-means++算法去初始化中心点。
k-means++算法选择初始中心点的基本思想就是:初始的聚类中心之间的相互距离要尽可能远。
1、 从输入的数据点集合中随机选择一个点作为第一个初始点。
2、 计算数据集中所有点与最新选择的中心点的距离D(x).
3、 选择下一个中心点,使得
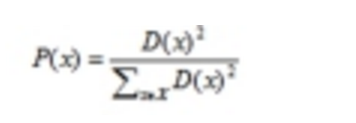
最大。
4、 重复2,3步过程,直到K个初始点选择完成。
使用sparkML实现kmeans算法
import org.apache.spark.ml.clustering.KMeans
import org.apache.spark.ml.linalg
import org.apache.spark.ml.linalg.Vectors
import org.apache.spark.sql.{DataFrame, SQLContext}
import org.apache.spark.{SparkConf, SparkContext}
/**
* @Author: zxl
* @Date: 2019/1/2 19:52
* @Version 1.0
*/
object kmeans_1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName(this.getClass.getName).setMaster("local")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
import sqlContext.implicits._
val baseData: DataFrame = sc.textFile("C:\\Users\\asus\\Desktop\\bb1\\isr.txt").map(line => {
val sp = line.split(",")
val d: linalg.Vector = Vectors.dense(sp(0).toDouble, sp(1).toDouble, sp(2).toDouble, sp(3).toDouble)
model_instance(d)
}).toDF("features")
val kmeans = new KMeans()
.setK(3)
.setFeaturesCol("features")
.setMaxIter(5)
.setPredictionCol("prediction") //设置最终的输出结果
val kmeansModel = kmeans.fit(baseData)
val kmeansData = kmeansModel.transform(baseData).cache()
// 打印每条数据 分别属于哪个类别
kmeansData.foreach(row => {
println(row(0) + " is predicted as cluster " + row(1))
})
//属性获取到模型的所有聚类中心情况:
kmeansModel.clusterCenters.foreach(center => {
println("Clustering Center:" + center)
})
//集合内误差平方和 的方法来度量聚类的有效性,在真实K值未知的情况下,该值的变化可以作为选取合适K值的一个重要参考
println( kmeansModel.computeCost(baseData))
}
}
case class model_instance(features: linalg.Vector)
结果:

聚类的中心

集合内误差平方和