机器学习、数据科学与金融行业
系列十二 机器学习平台 下
…继续
二. 机器学习平台 — 构建方法论
1)机器学习系统的主要流程
在讨论机器学习平台的构建方法论之前,我们需要先回顾一下一个机器学习系统的主要流程。
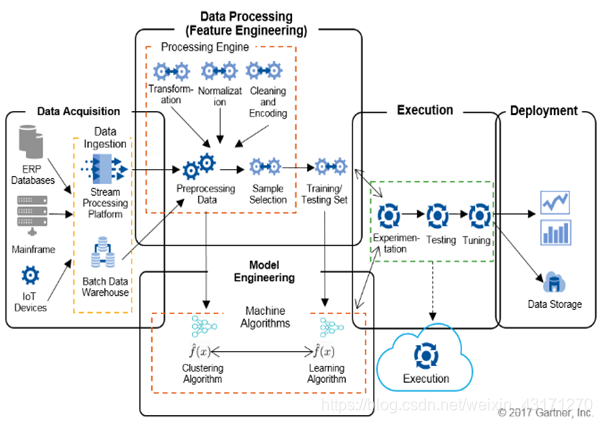
上图表示了一个机器学习系统的主要步骤,其中的细节我们就不赘述,相信读者都有了解,后面我们把这一流程称为ML Workflow。
相信大家都能意识到,管理ML Workflow是机器学习平台的一个基本功能。其他功能我们暂不探讨,可把上一小节所总结的所属平台的核心功能作为其功能需求。
2)平台架构的思考
当我们在做一个数据驱动技术架构设计时,一般来说我们要思考四个问题:
业务问题
数据问题
安全性问题
技术问题
我们需要最大限度减小项目失败的风险。请先看下图展示的参考架构设计流程:
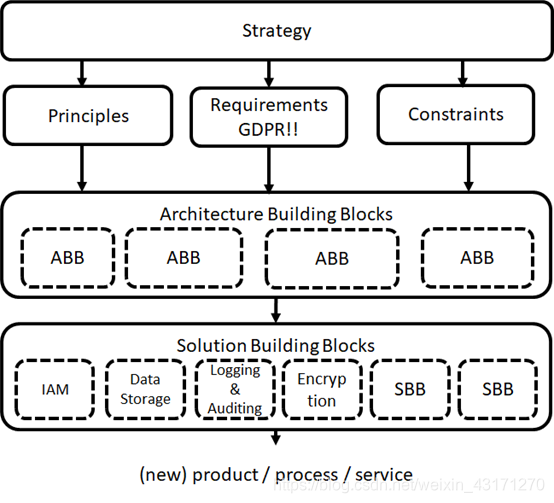
图中,GDPR代表General Data Protection Regulation
IAM代表Identity and Access Management
任何架构设计都必须遵循一个战略性指导,对于一个机器学习平台架构来说,我们必须明确使用机器学习技术和平台想解决什么问题,具体化为原则、需求和约束条件。接下来需要思考组成该产品的架构构造基本单元,最后再将其对应为相应的解决方案构造基本单元。
上面所提到的需求和约束条件相对容易定义,我们着重探讨一下架构设计的原则。架构设计原则是管控选择和实现的方向性陈述,换句话说,原则为决策提供了基础。
机器学习平台的设计最基本的原则可以简单总结如下:
a) ML workflow的管控。
b) 安全性原则
c) 为了简单可行,从ABB到SBB采用FOSS,即Free Open Source Solution。
结合其他需要考虑的问题,我们可以得到如下参考架构的概念视图:
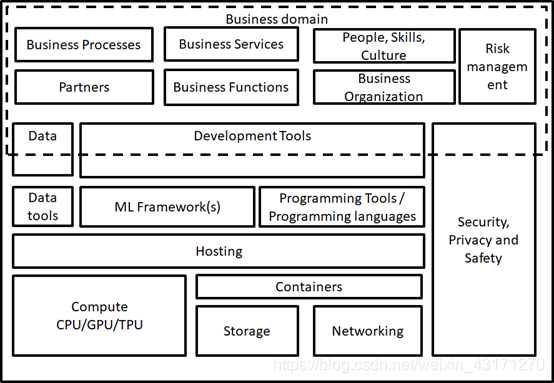
首先,构建或者购买机器学习平台是否能够成功很大部分取决于该组织的核心业务流程是如何会被机器学习部分影响的。多数情况下,次级业务流程会比主要业务更加受益于机器学习技术,因为主营业务受市场、销售和质量的影响更大一些。类似的情况同样发生在业务服务和业务功能方面。
另外一个关键问题是组织中的人、技能和企业文化也对机器学习平台建设的方向和决策起着至关重要的影响。个人认为使用机器学习平台的企业必须具备灵活的组织结构,创新的思维和包容性的文化。
还需要考虑诸如合作伙伴、风险管理等因素。
最后,我们归纳构建机器学习平台的四个核心技术能力:
数据管理能力、数据科学能力、云计算/容器技术能力、编程能力。
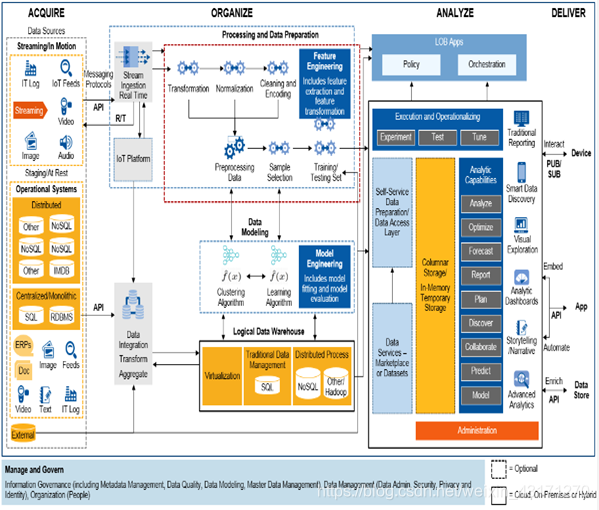
下图为Gartner的端到端机器学习平台的参考逻辑架构图:
- 构建机器学习平台
进行了这么多铺垫,我们终于开始自己构建一个机器学习平台了。遵循上节所讨论的方法论,首先我们讨论一下原则、需求和约束。
原则:
使用FOSS(Free Open Source Solution)进行构建
支持扩展性,模型重用
自动化,易用性
需求:
提供金融行业数据应用服务
可视化管理和监督
用户认证服务
约束:
开发力量相对薄弱
数据科学能力薄弱
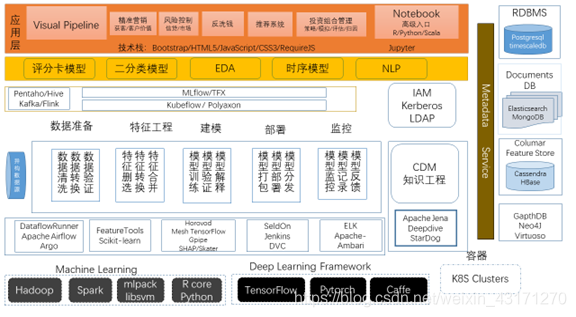
上图展示了笔者所构思的金融行业的机器学习平台的系统参考架构图。
我们来简单说明一下:
从应用上说,平台内置提供精准营销、风控、反洗钱、推荐系统和量化投资五个应用,并同时提供数据处理管道可视化接口和供高级人员使用的Notebook接口。
接下来,提供金融行业以及数据科学常用模型服务,例如评分卡模型,二分类模型、探索性数据分析,时序数据分析和自然语言处理。
自动化工作流可以采用MLflow或者Kubeflow,ELT部分使用Pentaho,数据注入使用Kafka/Flink或者logstash/sqoop等。
用户认证可使用kerberos或者LDAP,前者比较重一些,后者更加轻量级。
知识工程或者知识图谱部分是一个可选项,CDM(Common Data Model)笔者在前面系列文章种曾详细讨论,它与知识图谱是紧耦合的。
平台监控部分可以采用Apache Ambari或者ELK来进行定制化开发。
在部署和资源管理部分采用k8s支持弹性扩展。
为了提供数据存储、模型重用、状态和元数据管理,图中右侧给出了数据层的基础设施。
实际上,这只是一个参考架构,离一个企业级平台还相去甚远,有些重要的功能还未能实现。谈几个突出问题- 回想我们搭建机器学习平台的目的之一是希望可以让领域专家或数据科学技能不足且几乎没有编程能力的人也能够通过平台来构建模型,从而帮助解决其面临的业务问题。所有平台应该具备非常简单的接口和操作方法来构建模型。为了解决这个问题,或许我们需要增加拖拉拽的功能,Fabrik可能能够帮助我们。
- 此架构没有充分解决协作问题。
- 模型调优和超参数调优问题。(HyperOpt/TPOT)
- GPU资源管理和调度问题。
- 模型持续跟踪和退化问题。
还有……
三.金融行业中机器学习平台的怪相
在本文的最后,我们不妨轻松一下,聊一聊金融行业里机器学习以及平台化的一些令人困惑的现象。
在Fintech的热潮下同时受到互联网金融的冲击下,金融行业尤其是银行似乎开始主动拥抱科技,发展大数据技术、人工智能、区块链技术等等。在这个背景下,机器学习平台走入金融行业好像是顺理成章的。笔者有幸听过多个金融科技公司在银行宣讲其平台化产品,也有很多企业提供其他诸如风控、知识图谱、精准营销、反洗钱,智能投顾方面的和AI结合的技术解决方案。
最具代表性的就是第四范式,在短短3~5年之内,其平台产品占据了金融界(主要是银行)的半壁江山。该产品主推两个应用:营销和风控,其最具特色的点是有一个高维列式数据引擎,支持快速的高维检索;模型上似乎是采用特征交叉的方法,把低维度特征映射到高维而后寻找线性分类边界,有点类似于svm中所采用的核方法。由于其准确的应用定位和产品特色,再加上其成功的市场和营销策略,很快打开了市场。但就笔者所知,第四范式整体盈利能力是不足的,目前已出售的平台的使用率是很低的。
大家可能会感到有些奇怪了,在这种情况下,为什么还不能很好地盈利呢? 怪相1
笔者认为直接原因无非就是售价低、成本高而已。深层原因我们稍后再讨论。
银行系统在购买这种新科技产品时是非常谨慎地,它的想法多数是先尝试一下,看看是否有效。同时,第四范式作为一个创业独角兽,它的第一目的是快速打开市场,提高市场占有率。所以,在这两个主要因素驱动下,售价不可能高。
笔者听闻第四范式的产品中的高维列式数据引擎和模型实际上是某大型互联网公司广告点击预测架构的原型,它从该公司挖了几个核心人员,相信代价绝不会低。另外研发平台型产品本身成本也是很高的。还有,银行一定会要求平台提供方派工程师入厂帮助平台部署和模型搭建,这在一定程度上也会增加成本。第四范式的大规模市场造势和营销策略,请行业大咖为其站台。种种原因使得其成本居高不下。
如果第四范式不能盈利,其他提供类似产品和服务的金融科技服务企业也就更加很难盈利了。
具笔者所知,有些银行竟然选择自研机器学习平台? 怪相2
在分析这个问题之前,我们先看一下到底是什么样的企业和组织在研发机器学习平台。大体可以分成三类,第一类是大型公有云服务提供商,例如AWS,Google, 阿里巴巴,微软,IBM等;第二类是其核心业务与机器学习密切相关的企业,诸如Uber,Facebook,Airbnb。第三类是对企业级用户提供AI技术产品和服务的公司,好像Kensho,C3IoT,Palantir。
公有云提供商研发机器学习平台产品实际上是为了销售其云服务而已,况且只要一家有了这种产品,其他家都会立即推出类似产品以维持自己在该领域的竞争地位。上面所例举的企业本身拥有强大的数据科学能力和研发能力;同时第二类和第三类企业也同样具备这两种能力。而银行业本身的业务特点使其并非是强技术绑定的,整体的人才积累和文化都不具备能够研发平台型产品的能力。
回想前面我们所提到的构建方法论的内容,我们说平台型产品的构建一定要考虑企业的核心业务受到该产品影响的程度。那么AI或机器学习会对银行的核心业务产生较为重大的影响吗?答案是否定的,原因我们也会稍后解释。既然业务上也不是太需要,技术上能力也不足,为甚么会选择自研呢(甚至花50M购买GPU)?难道这些决策人如此愚蠢吗?当然不是,他们不但不愚蠢,反而非常聪明!
其实,在当前的投资创业环境下,第四范式的商业策略方向也没有问题;先占据市场,然后通过后续服务和产品来盈利,但是为什么平台的使用率这么低,且后续营利性的服务几乎没有呢? 怪相3
怪相不怪
笔者就自己的理解和感受来分析一下这三个怪相的深层次原因。
首先,我们回想前面笔者所设计的机器学习平台架构,当时也谈到了有些问题在那个架构中未能得到解决。但如果读者足够细心的化,会发现前面没有提及的两个关键问题:一个入,一个出。数据如何导入平台?发布的模型如何融入其现有的生产系统?事实告诉我们,这两点都非常困难,前者耗时长,后者几乎无法解决。
目前银行业的数据业务和分析的支撑系统主要是Teradata和SAS,这两个商业系统的能力本身非常强,SAS更是内置了很多商业模板和金融模型,它可以以SQL语句结合Teradata做逻辑回归。也就是说,它们的操作都是本地化的。如果数据需要从Teradata导入到机器学习平台,这种推送大量数据的代价是非常高的;另外已做出来的模型无法和其现有生产系统相结合,除非开辟独立的通道。
新的机器学习平台由于未能解决这两个关键问题,致使其模型迭代速度反而更低,也无法发挥其作用。
其次,机器学习技术真的能够对银行业务起到重要的吗?回想架构中笔者所提到的预置应用,也几乎包括了所有金融科技公司所能提供的应用。例如精准营销,传统的做法一般采用逻辑回归,整个过程类似于评分卡模型;而采用新的机器学习算法例如提升树之类的似乎是因为逻辑回归只能捕获单调关系;复杂模型则能找到交织特征或者非线性关系。但问题是这种关系真的存在吗?或者确实需要吗?精准营销一般来说就是个二分类模型,判断是否去营销某个人,深一步讲就是营销某个人会成功的概率。这个情况到底需要什么样的复杂特征呢?具体一点说,笔者认为就需要评价其购买某种产品的能力和意愿。银行系统所拥有的数据特征,诸如支付、转账、风险评估等并不能全面反映其能力和意愿。无论什么特征交叉或者非线性映射特征都没有太大作用。这里非单调关系确实存在,但可以采用类似评分卡模型中的客户分块(Customer Segmentation)来解决。
所以复杂模型在这些问题上能起到的作用有限,即便模型指标能够提高,也难逃过拟合的嫌疑,模型会退化的很快。类似现象同样发生在其他应用。
即便我们假设其真的有2%左右的提高,这对银行的核心业务确实起不了什么影响。大家可能会认为获客、风控等业务是银行的核心业务。就拿获客来说,无非是为了提高存款,但实际上银行谈一个企业用户所带来的存款比零售营销所带来的存款多太多了。银行目前主要盈利点也并非信贷利差,诸如长短期票据、MBS、外汇市场做市、理财产品才是最重要的盈利点。因此我们说机器学习并不能对银行核心业务产生重要影响,银行技术人员也没有足够的动机去学习和演练机器学习平台。这些就是已部署的平台使用率低的原因,说白了就是没有足够的需求。
到这里我们已经解释了怪相1和怪相3的深层次原因。那么既然银行业的需求不足,技术能力又不够,为什么银行还会购买该平台,还有银行选择自研,甚至花大笔的钱买硬件呢?
笔者认为银行之所以会购买机器学习平台是由于银行长期依赖的核心IT系统被IBM、Teradata、SAS所捆绑,每年的成本都很高,所以在人工智能时代来临之时,Fintech火热之际,银行的高层也希望做一些尝试,看是否可以为他们节约成本或带来新的业务和解决方案。至于购买硬件的原因说白了也很简单:在政府大力推动科技创新的时候,银行业大佬们也需要做点事情来响应号召,这也是自研机器学习平台的动机,正因为如此,银行的中级领导层才会来争抢这些相关项目来提升自己的重要性,做不好没有什么关系,因为大佬们会为他站台的,大不了就外包。硬件投资在公司财务报表中是可以资本化的,并不费用化,所以不影响其财报上所展现的盈利能力,也不会影响其股价。
换一个角度来思考这个问题的话,也就是使用逆向思维;如果银行在科技创新上一定要做点事情、且容易包装、不太好确定其价值又可以说的很大,那么他们会选择做什么呢?答案呼之欲出,当然是机器学习平台(有现成的机器学习框架和丰富的工具支撑)。
深入分析后,我们会发现所谈的这些怪相真的不怪,而是非常顺理成章的。请记住,在很多时候我们不是在和技术打交道,而是在和人或者群体在博弈。
总结一下:
在连续这三个系列文章中,我们简单介绍了机器学习平台产品的现状和发展,也总结了一些顶级机器学习平台的特点和构建思路。笔者分享了关于架构的构建方法论,且介绍了一个机器学习参考架构。文章最后我们也聊了金融行业关于机器学习平台的一些怪相,并分析了其形成的深层原因,仅属个人观点,也未必正确,请大家指正。
最后两句话和大家分享,
万物皆有迹可循;
科技应以人为本。
