机器学习、数据科学与金融行业

系列十:机器学习平台(上)
前言
亚马逊拥有全球最大的网购平台
谷歌代表着世界顶级的搜索引擎平台
Facebook运营着最大的社交网络平台
平台化,是目前非常流行的一种主流商业模式。上面所提及的伟大的企业都属于互联网行业,其实平台化思维很早就诞生了,例如,举一个大家都熟悉的企业:麦当劳,其实它可以被认为是帮助其他人提供饮食服务的平台。
回到技术领域,平台型产品更是五花八门;例如,大数据处理平台Hadoop,流计算平台Flink,企业资源管理平台,云计算平台等等。讲到这里,我们需要思考:平台型产品本质上可以为我们提供什么?
笔者认为平台型产品可以为用户提供解决某一领域问题组中的相关的一系列问题的完整解决方案。随着人工智能技术逐渐深入各个行业,而传统行业缺乏人工智能技术积累和人才,机器学习平台似乎开始流行起来。大家对该平台的预期是希望领域专家在缺乏数据科学专业知识且不具备较强编程能力的情况下有能力构建机器学习模型,从而帮助他们解决其面对的方方面面的业务问题。
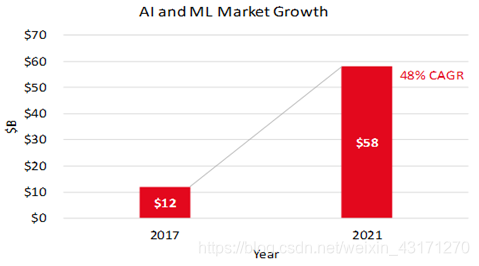
下图给出了IDC预测的人工智能和机器学习市场增长情况
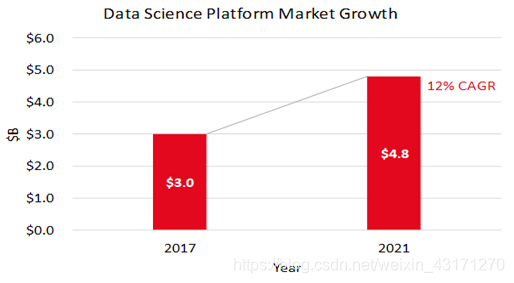
下图为IDC预测数据科学平台市场增长情况
本文主要在以下两个方面深入探讨机器学习平台:
• 机器学习平台
核心架构和功能
构建方法论
• 金融行业中机器学习平台的怪象
一. 机器学习平台 — 核心架构和功能
1)机器学习平台所涉及的问题域的主要成分及其工作流
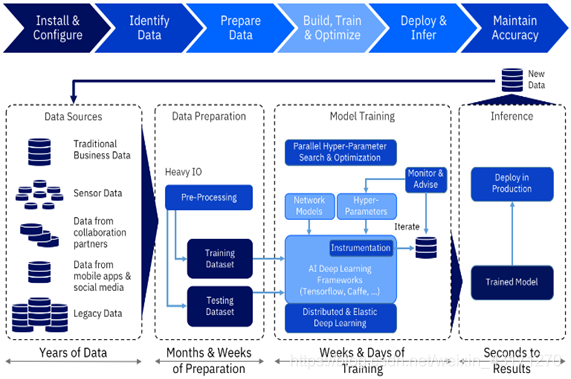
两个特点:计算密集型,闭环性
三个要求:多用户,资源共享,快速部署
四个关键词:数据、服务化、训练、管理
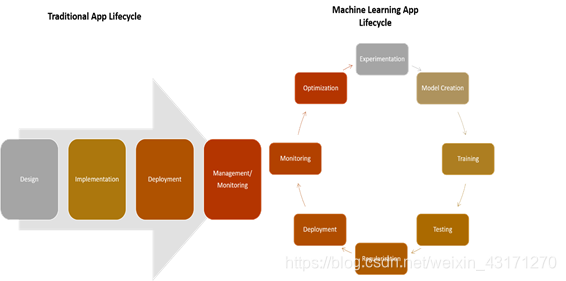
下图给出了传统应用生命周期和机器学习应用生命周期的比较:
2)五个值得一提的平台架构
Stanford’s DAWN
Uber’s Michelangelo
DataBricks’ MLflow
Facebook’s FBLearner Flow
Google’s TFX
下面我们将分别介绍:
Stanford’s DAWN
DAWN(Data Analytics for What’s Next)是由斯坦福大学创建的,并且被很多大厂支持,例如Intel,微软和谷歌。它包括一系列的工具和框架,采用流式的机器学习工作流,其技术栈的子项目解决了机器学习方案生命周期的各个方面。例如,训练(Snorkel)、持续分析(MacroBase)、数据计算(Weld).
DAWN的核心目标为:
端到端的机器学习工作流
赋予领域专家构建机器学习模型的能力
端到端的优化过程
其研究方向为:
为机器学习系统定义新的接口
通过可观测的机器学习简化模型定义(数据准备,特征工程)
解释结果(特征工程,产品化)
调试和观测(特征工程,产品化)
评估和增强数据质量(数据准备,特征工程)
端到端机器学习系统
流式数据分类
个性化推荐
联合推理和驱动
统一SQL,图计算和线性代数
机器学习的新底层结构
开发端到端优化的编译器
Delite:开发领域独有语言的框架
Splinter:私密保护的数据分析平台
精确度缩减和弱化处理,从而提高产出
为内核重新配置硬件资源(FPGA)
运行时分布式计算
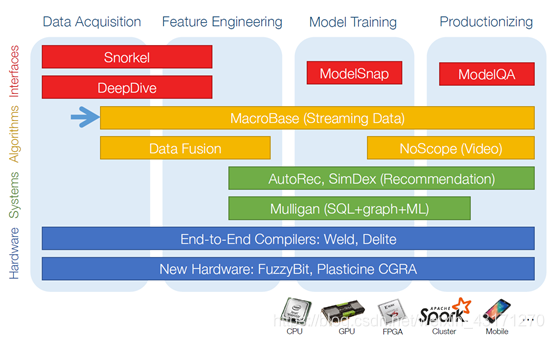
Uber’s Michelangelo
Michelangelo作为提供ML-as-a-service的平台满足Uber内部的各种业务的AI需求。它支持传统机器学习模型、时序预测和深度学习,覆盖了数据管理、训练、评估、推理、模型部署、监控等一系列机器学习工作流,同时支持Online和Offline学习。
为了更好的支持特征工程,Michelangelo使用Scala语言的子集开发了DSL(Domain Specific Language)。这是一个完全的函数语言,它的主要作用是帮助特征选择、转换和合并,以解决从数据管道中传来的数据存在缺失值或格式不统一,各个应用所需特征不同所带来的问题。
在模型部署方面,离线部署是作为一个Spark任务部署到一个容器内;在线部署是部署到一个在线服务集群,通过RPC调用。
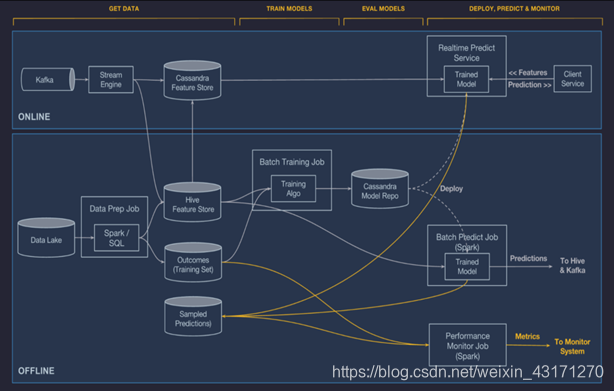
DataBrick’s MLflow
MLflow是自动化机器学习解决方案的一个开源平台,聚焦于机器学习流程的三个关键部分:训练、项目打包和模型服务。其三个主要成分为:Tracking,Projects,Models。
MLflow Tracking是一个API和UI,用来记录参数、代码版本、评价指标和输出文件,可在任何环境下使用。
MLflow Projects是一个数据科学代码打包的标准化格式。每一个项目就是一个目录包含代码或者git仓储,使用一个描述文件或者简单转换定义其依赖和如何运行代码。
MLflow Models提供了以多种偏好来打包机器学习模型的规则和可帮助部署模型的工具。每个模型被保存为一个目录,可包含任意文件和一个描述文件列出多个使用偏好(模型如何使用)。例如,一个TensorFlow模型可以被装载为TensorFlow DAG或者一个Python函数。MLflow提供工具来部署模型在多种平台;举例来说,一个支持Python函数的模型能够部署到一个基于Docker的REST Server,或者诸如Azure ML和AWS SageMaker的云平台,或者在Apache Spark上作为一个用户定义函数进行批和流推理。

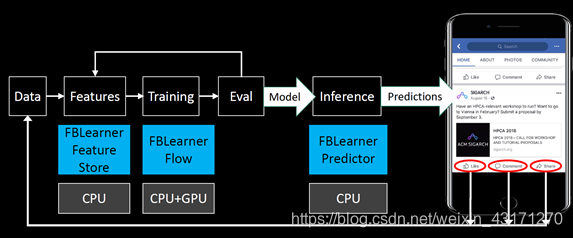
Facebook’s FBLearner Flow
Facebook’s FBLearner Flow在Facebook中为机器学习应用提供一个骨干框架,它自动化机器学习工作流的不同部分,包括特征抽取、训练、模型评估和推断。FBLearner Flow可与多个机器学习框架和工具进行整合,例如Caffe2、PyTorch和ONNX。
FBLearner Flow 的设计遵从四个核心目标:
每一个机器学习算法应该被实现为一个可重用的模式
工程师应该能够写一个训练管道在多台机器上并行,且可以被其他工程师使用
训练一个模型应该非常简单,且几乎每一个步骤都可以自动化
每个人都可以搜索过去的实现和经验,浏览结果,和他人共享
三个核心概念:
工作流(Workflow):支持所有机器学习任务的管道。
操作符(Operators):代表一个可执行的最小单元函数。
通道(Channels):代表输入和输出,可以对接定制化的系统。
三个核心组件:
作者和定制化分布式工作流的执行环境
经验管理UI
若干个训练常用机器学习的预定义管道
Google’s TFX
TFX, TensorFlow-Based Production-Scale Machine Learning Platform。TFX(TensorFlow Extended)是可以管道化操作TensorFlow程序,包含TensorFlow架构的若干个核心组件,诸如生成模型、分析和验证数据与模型的模块和在生产环境中使用模型提供服务的基础架构。
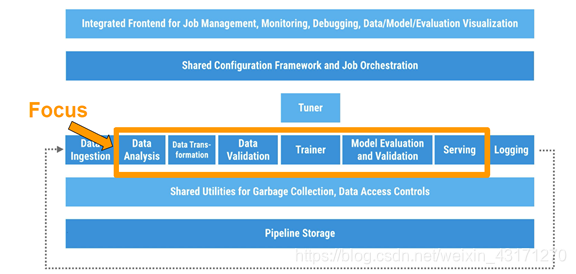
两个值得注意的点:
TFX支持Warm-Starting,背后的原理就是迁移学习。
在提供模型服务时,TFX主要依靠TensorFlow Serving,但是它支持多租户,也就是说多个模型可以在一个服务器上同时运行,为了解决交叉问题,需要很好的控制模型隔离。
未完,待续…
