……继续
三. 数据治理技术架构和工具
通过前两部分的介绍我们可以看出,数据治理是一项较为庞大的工程,且需要迭代优化的。由于数据治理所涉及的内容是非常广泛,即使读者阅读了前面的内容,可能还是会觉得较为凌乱。笔者在这里简单梳理一下:
数据治理依赖数据所有者或责任人(Data Stewards) 在组织内执行策略,以数据质量(Data Quality) 为核心目标,通常情况下,关键要素是管理核心或主要数据(Master Data)。也就是说
1) 数据治理主要定义策略、流程和方法。
2) 数据治理主要关注数据质量。
3) 数据治理主要围绕数据责任者(Data Stewards)和核心(Master Data)数据
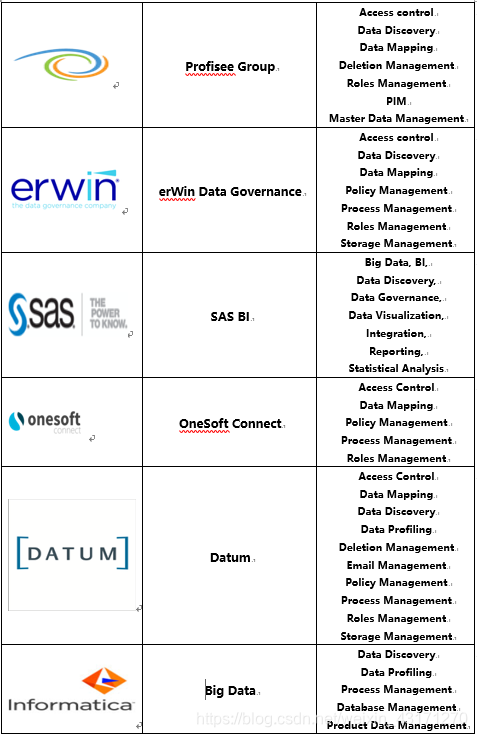
主要的商用数据治理平台和工具
数据治理相关的开源工具和平台

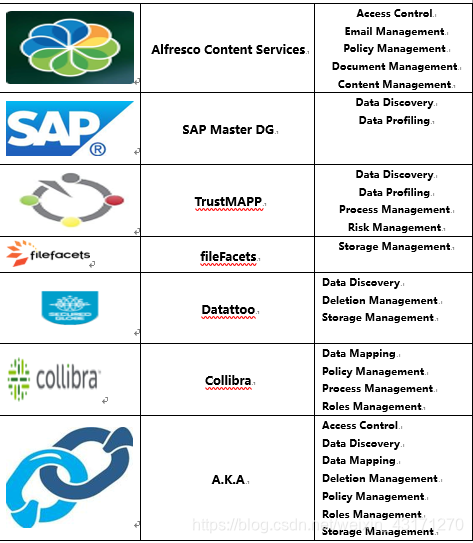
其他一些相关平台和工具(带号为开源工具)
Sentry – Central access management tool
Knox* – Central authentication APIs for Hadoop
Cloudera Navigator – Central security auditing
BlueTalon – Central access & security management tool
Centrify – Identity management
Zaloni – Data governance & data management tool
Dataguise – Auto-discovery, masking, encryption
Protegrity – Data encryption, tokenization, access control
Voltage – Data encryption, tokenization, access control
Ranger* – Similar to Sentry but provided by HortonWorks
Falcon* – Data management & pipeline orchestration
Oozie* – Data pipelines orchestration and management
金融行业数据治理的思考
谈到金融行业的数据治理,我们先抛开错综复杂的数据治理方法论,尝试先回答三个问题:
1) 金融行业有哪些核心数据?
2) 金融行业的数据系统的现状是什么?
3) 金融业数据治理的目标是什么?
这里,我们尝试回答这些问题。
金融行业有哪些核心数据?
金融的本质是解决资源流动性问题,就是如何高效合理的把资源分配给需要资源的人或者机构。围绕着这一核心,我们可以得出金融行业可分两类。第一类解决存、转、贷,例如银行,第二类解决投资,例如证券公司、基金管理机构等。无论哪一类,其核心数据就是客户数据、产品数据和客户与产品的关系数据。
金融行业的数据系统的现状是什么?
金融行业一直以来都在使用商业系统来支撑其运营体系,类似ERP、CRM、BI等系统是非常普及的。但笔者推测,尤其在国内,金融机构的各业务部门的系统相对独立,在数据整合和共享上进展缓慢。不过,金融业的高层管理者已经逐渐开始认识到这个问题,从各方面来利用和发展大数据和AI技术以求提高效率,降低成本和扩展新业务。在这个背景下,打通数据层是必须要经历的一步。笔者认为,下图揭示了目前金融行业数据系统的现状,国内大部分金融机构可能只建设了图中的左半部分。
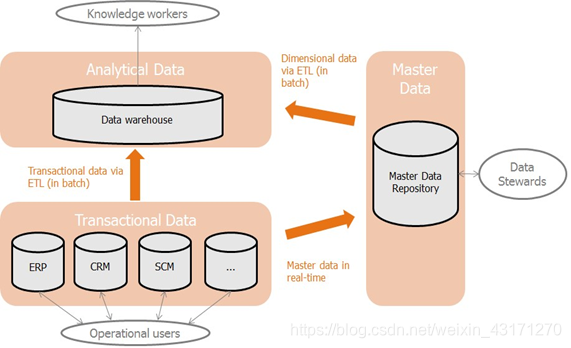
首先,数据整合。数据是一种无形资产,金融行业的数据的含金量之高是首屈一指的。但实际上,我们主要还是希望从数据中提取有价值的信息,发现潜在的模式,普遍认为AI技术可以在这方面有所作为。从数据科学理论来说,要想做好这一点,多源高维海量数据是一个基本需求。所以数据整合是第一目标,这里的整合不仅包括各业务部门数据整合,也包括和外部数据的整合。
其次,就是数据安全,因为金融数据的安全性本身就要求很高,加上金融监管的力度不断加强,所以数据的安全性也是金融行业数据治理的主要目标之一。
最后,数据理解。金融业务非常复杂且专业程度很高,我们需要一种通用的数据模型来描述金融数据。在本系列文章中的第二篇关于通用数据模型(CDM)的讨论中,笔者已经深入介绍了这个概念。CDM可以帮助各部门之间理解数据,并使数据共享更有效率。但它本身不是数据治理的范畴。元数据管理(Meta-data Management)也可以在这一点上起到一定的帮助作用。
下面,我们尝试采用开源工具和平台来搭建一个简单的数据治理参考架构。
前面已经说过,数据治理系统搭建是一个迭代优化过程。如果一开始就希望构造一个大而全的系统,成功的概率极低。所以在起步阶段,先建立一个相对较小的目标是一个比较明智的选择。
此目标主要包含前面所提及的金融行业的三个核心需求:整合、安全、元数据管理。
数据治理过程需要明确三类核心角色:Data Steward,Data Scientist, Data Engineer;明确定义核心数据(Master Data)和参考数据(Reference Data)。
需要说明的是,笔者认为整个过程需要围绕一个数据驱动型应用的业务目标,例如精准营销或者风险管理等。我们需要通过开发这个应用打通数据治理的技术栈,随着应用的逐渐增加和完善,数据治理的各个组件也会随之得以增强,从而提高其成熟度。
逻辑架构如下图:
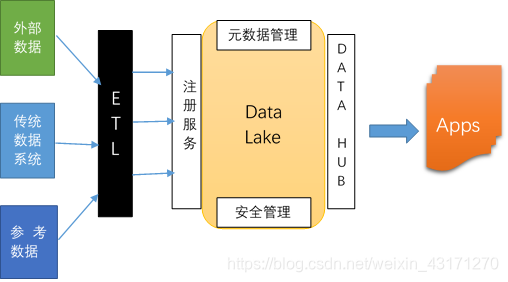
外部数据 — 爬虫数据和外部合作方数据。
传统数据系统 — Data Warehouse,ERP/CRM等。
参考数据 — 所需的其他非核心数据
ETL – Talend 或者 Pentaho
Data Lake — Hadoop/Hive/HBase 分布式批处理系统
— Storm 流计算引擎
— Spark 迭代计算引擎
— PostgreSQL 关系计算引擎
— Neo4j 图计算引擎
— TimeScaleDB 时序数据计算引擎
元数据管理 — Talend/Apache Atlas
安全管理 — Sentry/Knox
注册服务 — Kyio
Data Hub — Kyio/CKAN
在数据治理领域上,开源平台和工具生态系统并不完备。前面只是给出了一个基本的逻辑架构参考实现,其中所使用的有些开源工具的功能是有重叠的,而且离一个真正的完备的数据平台技术架构还有很大距离。
最为重要的是要以业务目标为核心,有明确的目标和计划以及原则,另外一个完备的评价体系,诸如监管方法和审计也是必不可少的。
总结:
本文简要介绍数据治理平台的基本框架和方法论,并讨论了金融行业应用数据治理的必要性和要点,且给出了一个由开源平台和工具搭建的最简单的参考架构。
数据治理并不只是技术层面的事情,更重要的是从战略和文化方面的改变。
最后,笔者提出一个问题,数据治理既然如此重要,为什么国内的金融行业并没有大规模的推进相关项目的落地和实施呢?
