根据使用场景,网络爬虫可分为 通用爬虫 和 聚焦爬虫 两种
通用网络爬虫,是捜索引擎抓取系统(Baidu、Google、Yahoo等)的重要组成部分。主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。
聚焦爬虫,是"面向特定主题需求"的一种网络爬虫程序,它与通用搜索引擎爬虫的区别在于: 聚焦爬虫在实施网页抓取时会对内容进行处理筛选,尽量保证只抓取与需求相关的网页信息。
我们一般使用的都是聚集爬虫,该文就是使用聚集爬虫将智联上的数据爬下来。
前置知识简述:
- 当用户在浏览器的地址栏中输入一个URL,浏览器会向HTTP服务器发送HTTP请求。HTTP请求方法主要分为“Get”和“Post”两种方法。
- 当我们向浏览器发送一个Request请求去获取 http://www.baidu.com 的html文件,服务器把Response文件对象发送回给浏览器。浏览器分析Response中的 HTML,发现其中引用了很多其他文件,比如Images文件,CSS文件,JS文件。 浏览器会自动再次发送Request去获取图片,CSS文件,或者JS文件。
- 所有的文件都下载成功后,网页会根据HTML语法结构,完整的显示出来我们平时通过浏览器访问的页面。
所以现在我们必须对request与response比较熟悉,尤其是格式的头、行、体,读者可以自行补充http相关知识,下图就是我访问智联的请求头信息的部分截图

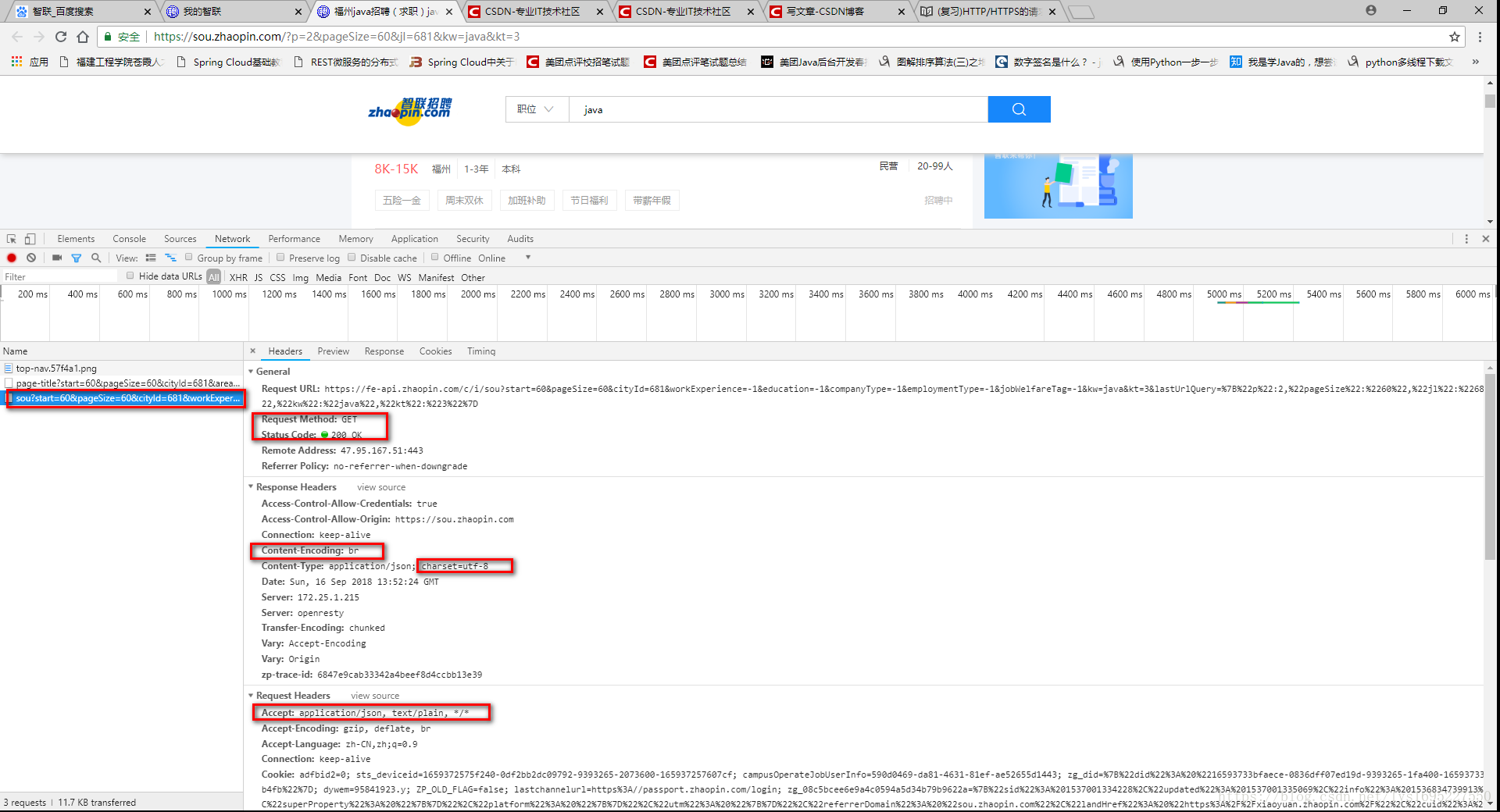


抓住上图的几个重点,基本上就能够实践一次访问了。
- 这边对部分参数做下解释,其中cityId是城市编号,图中681对应福州,如果你需要设置为自己需要的程序,通过F12如上图查看即可,kw为搜索框输入值,start是起始记录,第一页为0,第n页为60*(n-1),其中60为pageSize,还有就是lastUrlQuery参数,值为map类型(python中的字典、js中的json),你懂得,就是包装键值对。
- 查看响应response发现,我们获取的不是html字符串,而是一个json格式的数据。这个不奇怪,如今使用Ajax异步加载服务端数据并渲染数据到页面上已经是很普遍了,这样获取需求数据更加方便,省去了parse HTML页面的步骤。
搞清楚以上这些注意事项,就可以使用python来实现http请求,
Python3处理HTTP请求的包:http.client,urllib,urllib3,requests。其中http通俗来说低级一些,一般不直接使用,urllib更高级一点,是属于标准库,无需pip。urllib3跟urllib类似,拥有一些重要特性而且易于使用,但是属于扩展库,需要pip安装,requests 基于urllib3 ,也不是标准库,但是使用非常方便,通用需要pip。
这里我需要重点提一个坑,就是智联的招聘数据使用Accept-Encoding:br 压缩(注:boss直聘是accept-encoding: gzip, deflate, br)。br 指的是 Brotli,是一种全新的数据格式,无损压缩,压缩比极高(比gzip高的)。
第一种:将‘Accept-Encoding’中的:br 去除。这样接受的网页页面就是没有压缩的或者是默认可解析的了。
第二种:将使用br压缩的页面解析。python3 中要导入 brotli 包,自行pip安装,如果遇到microsoft visual c++ 14.0 is required坑了,请转去https://blog.csdn.net/amoscn/article/details/78215641,可以参考。
PS:cookie我是使用了自己的,未测试不带cookie是否能够正常访问,你也可以改为自己的cookie。值得注意的是智联没有boss直聘那样,使用爬虫导致403,提示:由于您当前网络访问页面过于频繁,可能存在安全风险,我们暂时阻止了您的本次访问,24小时将自动解除限制。所以也就无需带上ip代理了。
这样我们就可以将开心地开始编写我们的python程序了。
项目结构:

为了读者阅读方便在此附上其中爬虫相关的代码,保留注释与多出print,方便阅读并调试,数据清洗与数据可视化自行下载源码。
# -*- coding: utf-8 -*-
import requests
# 使用urlencode将key-value这样的键值对转换成我们想要的格式,返回的是a=1&b=2这样的字符串。
from urllib.parse import urlencode
from requests.exceptions import RequestException
# reponce使用Content-Encoding=br压缩,所以需要brotli模块用于解压
import brotli
# 将json文件保存到本地XXX.json,再次读取将json字符串转换为对应的python数据类型(load 方法),主要是{}对象转dict,[]数组转list
import json
import sqlite3
# sqllite3的数据库位置
conn = sqlite3.connect('D:\\Program Files\\sqlite\\data\\智联招聘福州(java_python)\\jobData.db')
# get方式提交的参数字典
param={
'start':180,
'pageSize':60,
'cityId':681,
'workExperience':-1,
'education':-1,
'companyType': -1,
'employmentType': -1,
'jobWelfareTag': -1,
'kw': 'python',
'kt': 3,
'lastUrlQuery': {"p":4,"pageSize":"60","jl":"681","kw":"python","kt":"3"}
}
# http协议中request请求的请求头信息,数值可以使用本地浏览器开发者工具(F12)查看并修改
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
'Host': 'fe-api.zhaopin.com',
'Referer': 'https://sou.zhaopin.com/?p=4&pageSize=60&jl=681&kw=python&kt=3',
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Origin': 'https://sou.zhaopin.com',
# cookie 修改为(本地的cookie)
'Cookie':''
#cookie 读者在本地浏览器的开发者工具中复制即可
}
def getPage(city='',keyword='',pageNo=4):
param['start']=60*(pageNo-1)
param['kw']=keyword
tempDict={"p":4,"pageSize":"60","jl":"681","kw":"python","kt":"3"}
tempDict['p']=pageNo
tempDict['kw']=keyword
# print(tempDict)
param['lastUrlQuery']=tempDict
# print(str(tempDict))
# print(param)
# print(urlencode(param))
url = 'https://fe-api.zhaopin.com/c/i/sou?' + urlencode(param)
try:
# 获取网页内容,返回html数据
response = requests.get(url, headers=headers)
# 通过状态码判断是否获取成功
# print(response.encoding)
# print(response.headers)
# print(response.headers['Content-Encoding']) Content-Encoding=br
# 此处必须使用brotli进行解压,否者为乱码,其中brotli模块安装可能失败,提示microsoft visual c++ 14.0 is required,可以通过安装解决
tempData = brotli.decompress(response.content)
data = tempData.decode('utf-8')
filename='智联_'+city+'_'+keyword+'_第'+str(pageNo)+'頁_数据.json'
with open(filename,'w',encoding='utf-8')as f:
f.write(data)
# print(data)
if response.status_code == 200:
return data
return None
except RequestException as e:
return None
def savToSqlite(keyword,pageNo):
for i in range(1,pageNo+1):
filename='智联_福州_'+keyword+'_第'+str(i)+'頁_数据.json'
with open(filename,'r',encoding='utf-8') as f:
data=f.read()
dataJson = json.loads(data)
dataList=dataJson['data']['results']
print(dataList)
dataListLength = len(dataJson['data']['results'])
for record in dataList:
number=keyword+'_'+record['number']
jobType = record['jobType']['display']
companyName=record['company']['name']
company_size=record['company']['size']['name']
company_type=record['company']['type']['name']
workingExp=record['workingExp']['name']
eduLevel = record['eduLevel']['name']
salary=record['salary']
emplType= record['emplType']
jobName=record['jobName']
city=record['city']['display']
welfare=','.join(record['welfare']) #列表字符串
timeState=record['timeState']
# print(number,jobType,companyName,company_size,company_type,workingExp,eduLevel,salary,emplType,jobName,city,welfare,timeState,keyword)
insertSql='insert into recruitment(number,jobType,companyName,company_size,company_type,workingExp,' \
'eduLevel,salary,emplType,jobName,city,welfare,timeState,keyword) values(?,?,?,?,?,?,?,?,?,?,?,?,?,?)'
conn.execute(insertSql,(number,jobType,companyName,company_size,company_type,workingExp,eduLevel,salary,emplType,jobName,city,welfare,timeState,keyword))
conn.commit()
# number
# jobType
# companyName
# company_size
# company_type
# workingExp
# eduLevel
# salary
# emplType
# jobName
# city,
# welfare
# timeState
if __name__ == '__main__':
# 由于爬取数据时,发现python才7页,java远多于7页,所以为了便于处理比较,将数据爬取页数设置为7
totalPage=7
# 下载json文件
# for pageNo in range(1,totalPage+1):
# html=getPage('福州','java',pageNo)
# 保存到数据库
savToSqlite('python',totalPage)
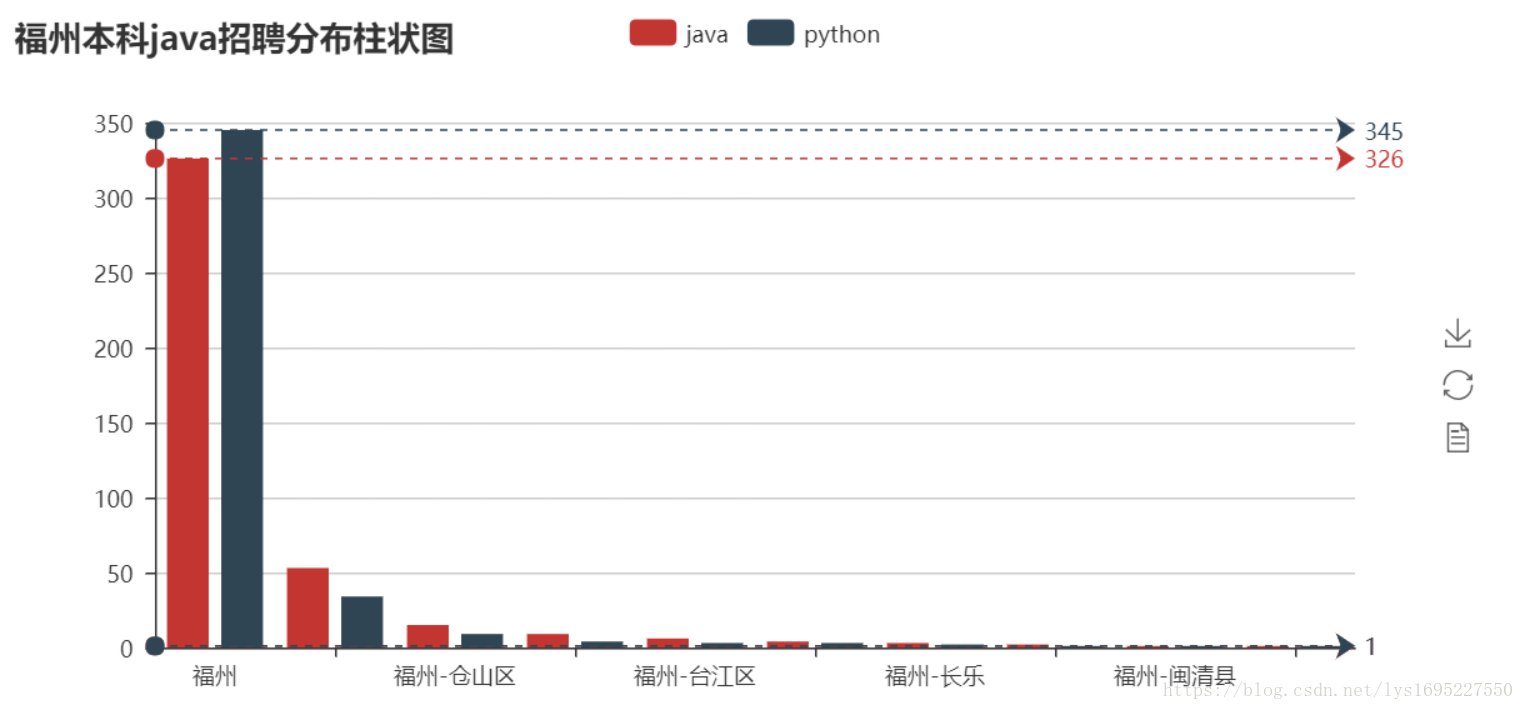
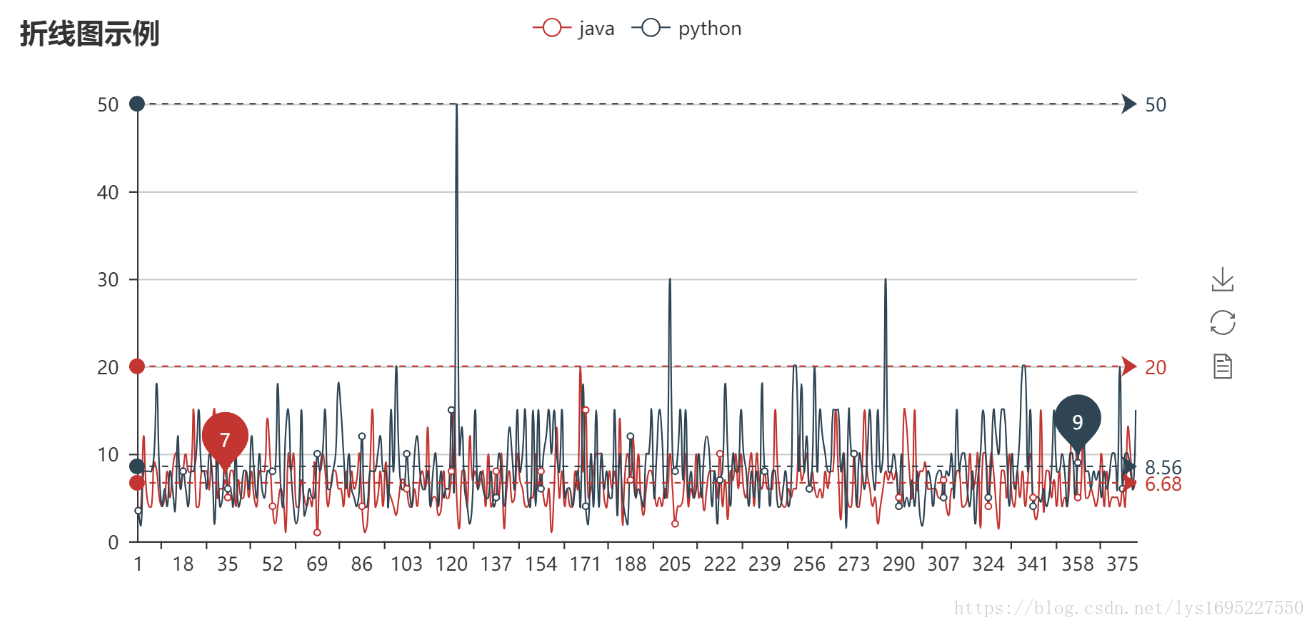
savToSqlite('java',totalPage)部分可视化图如下:
最高薪资折线图

最低薪资折线图


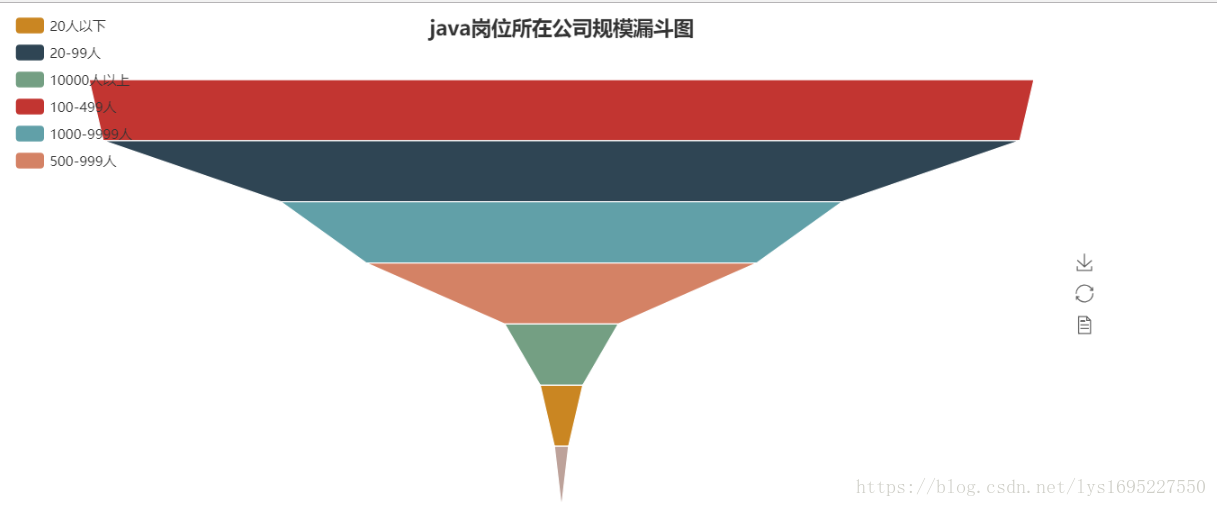
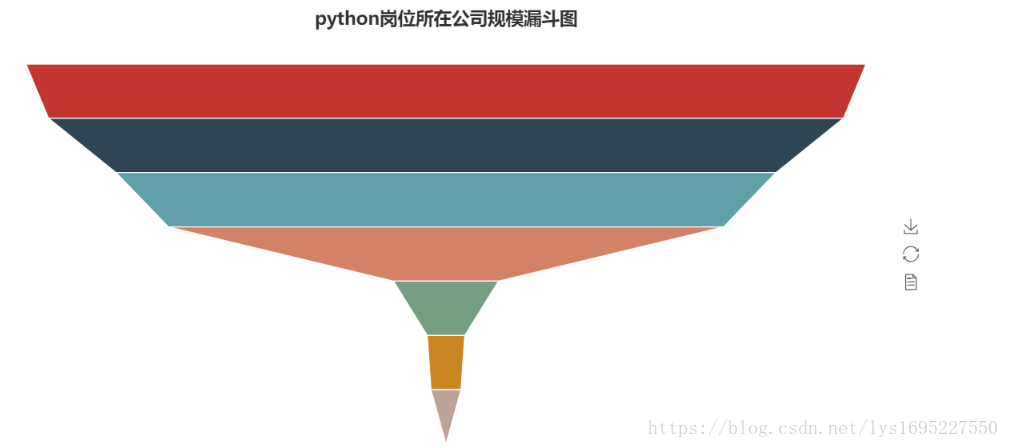
java岗位词云图

python岗位词云图

通过上图做出一些分析才是本次实践最重要,这不在本次实践范围内,读者自行分析。
giihub地址:https://github.com/cherise-lailai/pythonRepository.git
网盘地址:链接:https://pan.baidu.com/s/1HJz96jqfE5QNb_o8oLs3ug 密码:lqgi
纸上得来终觉浅,绝知此事要躬行。