用多进程(multiprocessing)+多线程(threading)的方式并发爬取智联招聘爬虫岗位信息并存入MongoDB
本次实战目标站点:https://sou.zhaopin.com/?jl=548&kw=爬虫&kt=3 ,主要是爬取广东省内招聘爬虫岗位信息,并用并发方式来对请求的URL进行访问以爬取数据后存入MongoDB。
**1、**首先分析URL的请求规律。打开chrome的开发者工具,刷新页面后找出数据是由哪个URL请求得到的。经分析可知该URL为:https://fe-api.zhaopin.com/c/i/sou?pageSize=90&cityId=548&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=爬虫&kt=3&rt=75d6910a4cae41719447ce3f870ff7b8&_v=0.02629649&x-zp-page-request-id=1a544937d2a24498ba08563bee6e316e-1550300526019-102160 ,发送方式是一个Ajax请求,返回的数据格式是JSON。如下图所示:
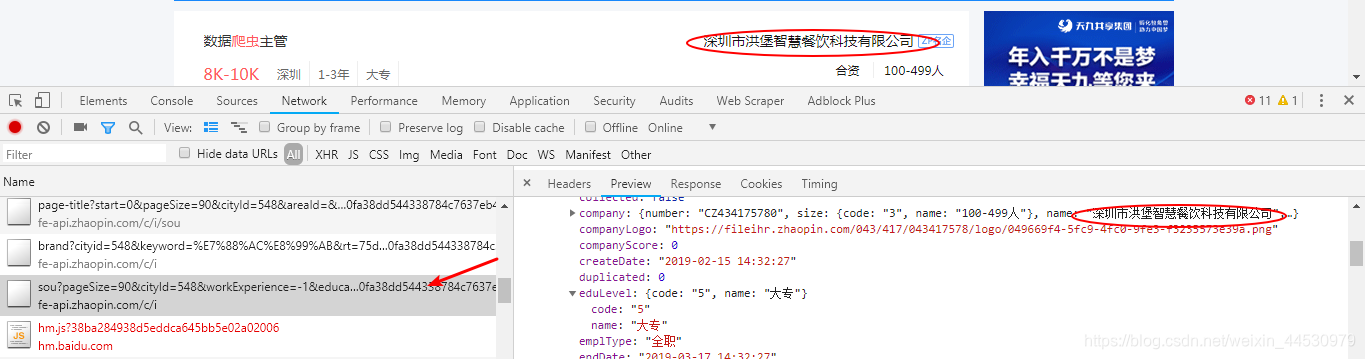
**2、**为了能得到URL的请求规律,我们在Network中选中XHR标签,然后点击下一页获取请求的URL,如下图所示:
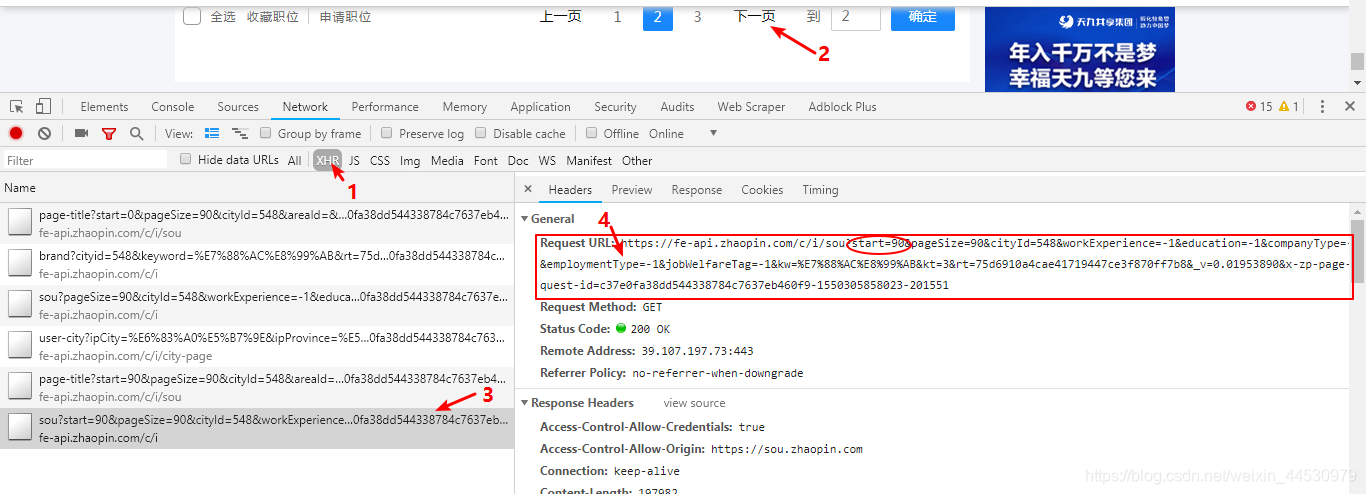
将这前后两次的Requests URL对比可以发现,其中变化的字段为start,且每次都以90个偏移度增加,因此能得到URL的变化规律为:https://fe-api.zhaopin.com/c/i/sou?start={“偏移度为90”}&pageSize=90&cityId=548&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=爬虫&kt=3&rt=75d6910a4cae41719447ce3f870ff7b8&_v=0.02629649&x-zp-page-request-id=1a544937d2a24498ba08563bee6e316e-1550300526019-102160 ,到此我们开始编写爬取程序。
主代码:zhilain.py
from config import *
import json
import pymongo
import requests
import threading
import multiprocessing
client = pymongo.MongoClient(MONGO_URL, connect=False)
class ZhilianSpider:
def __init__(self):
self.url_temp="https://fe-api.zhaopin.com/c/i/sou?start={}&pageSize=90&cityId=548&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=%E7%88%AC%E8%99%AB&kt=3&rt=75d6910a4cae41719447ce3f870ff7b8&_v=0.02629649&x-zp-page-request-id=1a544937d2a24498ba08563bee6e316e-1550300526019-102160"
self.headers = {"User-Agent": set_user_agent()}
def parse_url(self,url):
response=requests.get(url,headers=self.headers)
return response.content.decode()
def get_job_list(self,json_str):
dirt_ret=json.loads(json_str)
job_list=dirt_ret["data"]["results"]
if job_list:
for job in job_list:
job_content = {}
job_content['job_name'] = job['jobName']#工作名称
job_content['city'] = job['city']['display']#工作地点
job_content['welfare'] = job['welfare']#福利
job_content['salary'] = job['salary']#薪资
job_content['workingExp'] = job['workingExp']['name']#工作经验
job_content['eduLevel'] = job['eduLevel']['name']#学历
job_content['company_size'] = job['company']['size']['name']#公司规模
job_content['company_name'] = job['company']['name']#公司名称
job_content['company_type'] = job['company']['type']['name']#公司类型
self.save_to_mongo(job_content)
def save_to_mongo(self,job_content):
db = client[taget_DB]
if db[taget_TABLE].update_one(job_content, {'$set': job_content}, upsert=True):
print('Successfully Saved to Mongo', job_content)
def run(self,page_num):
page_size=page_num*90#每次请求是的偏移度
url = self.url_temp.format(page_size)
json_str = self.parse_url(url)
self.get_job_list(json_str)
if __name__ == '__main__':
page_num=2#总页码数
zhilian = ZhilianSpider()
# 多线程
pool = multiprocessing.Pool()
# 多进程
thread = threading.Thread(target=pool.map,args = (zhilian.run,[i for i in range(page_num)]))
thread.start()
thread.join()
辅助程序:config.py,用于连接MongoDB,及设置随机请求UA以应对反爬
import random
MONGO_URL = 'localhost'
taget_DB = "ZHILIAN"
taget_TABLE = "ZHILIAN"
def set_user_agent():
USER_AGENTS = [
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5"
]
user_agent = random.choice(USER_AGENTS)
return user_agent
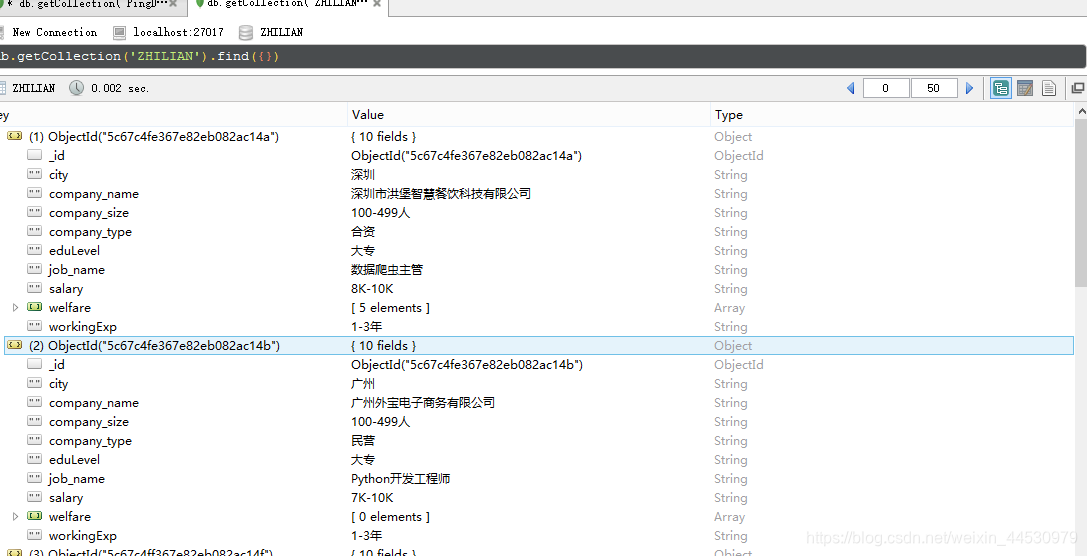
爬取结果如下图: