东方股票网址:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
找到沪深个股 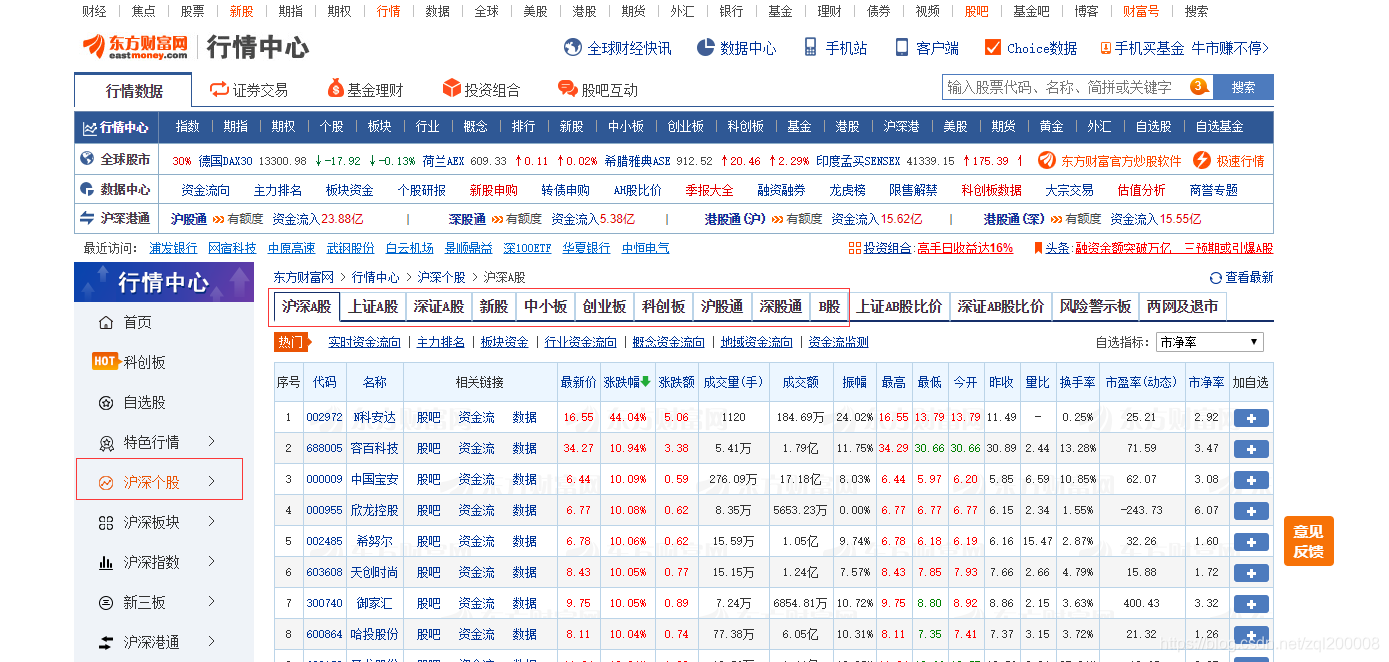
F12刷新网页留意刷新出现的内容****找到对应的文件
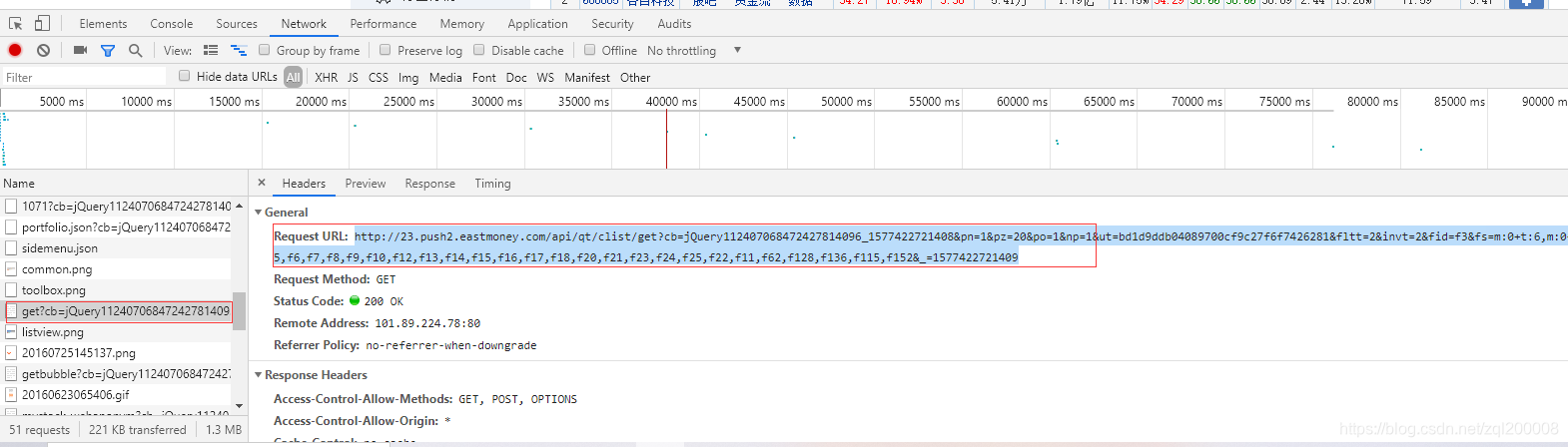
复制URL查看是不是我们想要的内容

查看网址我们发现 pn=1 是第一页page=1 所以列一个循环就可以找到其他页面所有的信息

for i in range(1,193):
url = 'http://50.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124002312725213714928_1577232380831&pn='+str(i)+'&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1577232380832'
导入相关文件包
import requests
import re
import json
import pandas as pd
import csv
当我们像平常那样调用json时发现这次无法取到内容然后查看它的text文件时发现前面多了这个

此时我们就需要将前面多余的去掉
for i in range(1,193):
url = 'http://50.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124002312725213714928_1577232380831&pn='+str(i)+'&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1577232380832'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'}
response = requests.get(url,headers=headers)
data = json.loads(response.text.lstrip('jQuery1124002312725213714928_1577232380831(').rstrip(');')) #去除头部json杂质
这样就得到了我们想要的json
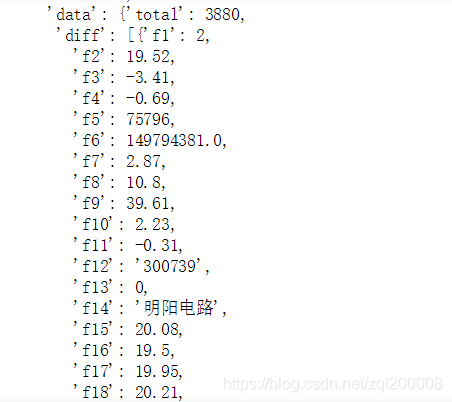
寻找到json需要的模块 [‘data’][‘diff’]列一个循环
for i in data['data']['diff']:
daima = i['f12'] #代码
name = i['f14'] #名称
new = i['f2'] #最新价
zengfu = i['f3'] #涨跌幅
e = i['f4'] #涨跌额
chengjiao = i['f5'] #成交量
jiaoe =i['f6'] #成交额
zhenfu = i['f7'] #振幅
max_top = i['f15'] #最高
min_low = i['f16'] #最低
today = i['f17'] #今开
ye = i['f18'] #作收
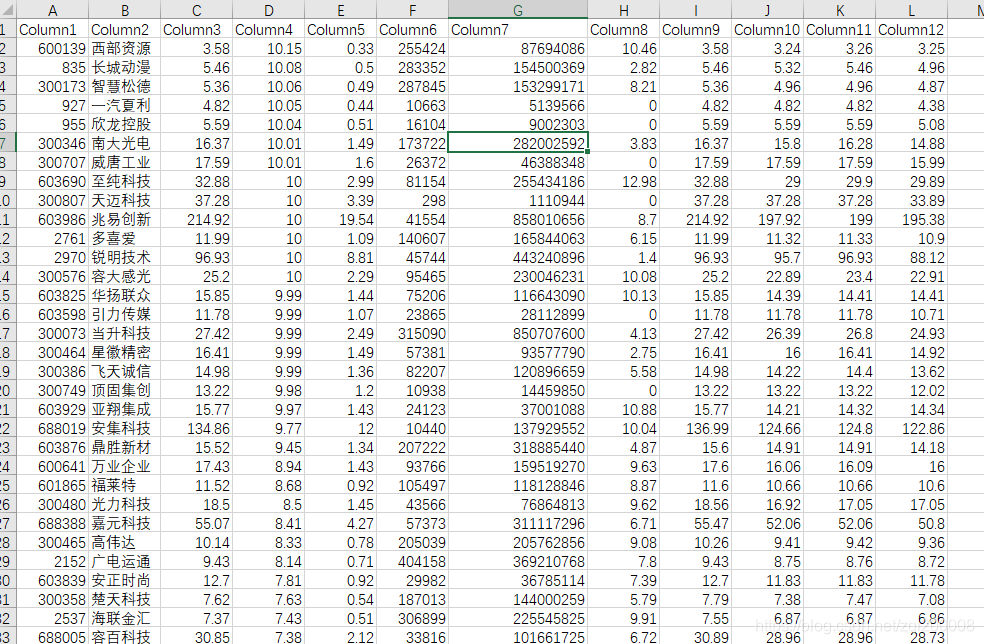
最终再将爬取到的数据存放到CSV
with open('gu.csv','a',encoding='utf-8',newline='')as file:
writer = csv.writer(file)
writer.writerow(item)
爬取的数据部分如下:
附上完整代码:
import requests
import re
import json
import pandas as pd
import csv
for i in range(1,193):
url = 'http://50.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124002312725213714928_1577232380831&pn='+str(i)+'&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1577232380832'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'}
response = requests.get(url,headers=headers)
data = json.loads(response.text.lstrip('jQuery1124002312725213714928_1577232380831(').rstrip(');'))
# print(url)
for i in data['data']['diff']:
daima = i['f12'] #代码
name = i['f14'] #名称
new = i['f2'] #最新价
zengfu = i['f3'] #涨跌幅
e = i['f4'] #涨跌额
chengjiao = i['f5'] #成交量
jiaoe =i['f6'] #成交额
zhenfu = i['f7'] #振幅
max_top = i['f15'] #最高
min_low = i['f16'] #最低
today = i['f17'] #今开
ye = i['f18'] #作收
item = [daima,name,new,zengfu,e,chengjiao,jiaoe,zhenfu,max_top,min_low,today,ye]
with open('gu.csv','a',encoding='utf-8',newline='')as file:
writer = csv.writer(file)
writer.writerow(item)
