版权声明:原创内容,禁止用于商业用途 https://blog.csdn.net/starkbling/article/details/82151729
网贷之家中的p2p平台数据比较容易获取,重要的就是如何分析网页的源代码然后从里面提取自己需要的信息,也不需要用户登录,该网站的爬虫比较简单,主要用了urllib包来获取网页信息,用BeautifulSoup来解析网页,最后用正则表达式提取数据。这里就直接上源码了:
# -*- coding: utf-8 -*-
"""
Created on Wed Aug 8 18:22:26 2018
@author: 95647
"""
import urllib
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
import pandas as pd
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'}
lists =[]
domains = "https://www.wdzj.com"
def get_platform_site(url,lists):
"""获取所有的平台网址"""
# global lists
req = urllib.request.Request(url, headers=headers)
html = urlopen(req)
bsObj = BeautifulSoup(html,'lxml')
title = bsObj.findAll("div",{'class':'itemTitle'})
for titles in title:
links = titles.findAll("a",{'target':'_blank'})
for link in links:
if 'href' in link.attrs:
lists.append(link.attrs['href'])
# print(link.attrs['href'])
return lists #用utf-8进行解码
def pages_num(url):
"""获取各类平台的页面总数"""
req = urllib.request.Request(url, headers=headers)
html = urlopen(req)
bsObj = BeautifulSoup(html,'lxml')
pages= bsObj.findAll("a",text = '尾页')
for page in pages:
if "currentnum" in page.attrs:
pages_num = page.attrs["currentnum"]
else:
return None
return pages_num
def conditions(i):
"""获取各个平台的运营状态,生成包含各类平台的列表"""
# global lists
lists =[]
url_ = r"""https://www.wdzj.com/dangan/search?filter=e%s"""%str(i)
all_pages_num = int(pages_num(url_))
for num in range(1, all_pages_num +1):
url = url_ + "¤tPage=%s"%str(num)
lists = get_platform_site(url,lists)
return lists
operations = conditions(1) #正常运营平台
#close_transitions = conditions(2) #停业或转型平台
#in_problems= conditions(3) #问题平台
def plat_profile(lists):
"""抓取平台的数据"""
global domains
plat_profile=[]
for site in lists:
plat_info =[]
url = domains + site
req = urllib.request.Request(url, headers=headers)
html = urlopen(req)
bsObj = BeautifulSoup(html,'lxml')
plat_name = bsObj.findAll('h1')[0].attrs["alt"] #平台名称
t_l = bsObj.findAll("div",{"class":"pt-info"})[0].get_text()
time_s=""
location =""
if len(t_l)>0:
t_l = re.split("上线",t_l)
time_s = t_l[0].strip() #上线时间
location= t_l[1].strip() #平台所属地域
common_data = bsObj.findAll("b",{"class":"tab_common_data"})
yield0 ="" #给出变量值
duration = "" #给出变量值
for data in common_data:
text = data.parent.get_text()
if len(re.findall(".*月.*",text)) > 0:
duration = re.findall(".*月.*",text)[0]
duration = text.strip() #平均期限
if len(re.findall(".*%.*",text)) > 0:
yield0 = re.findall(".*%.*",text)[0]
yield0 = text.strip() #平均收益率
rates_ = bsObj.find("div",{"class":"dpxximg"})
if "data-pl" in rates_.attrs:
rates = bsObj.find("div",{"class":"dpxximg"}).attrs["data-pl"] #获取评分
plat_pro = bsObj.findAll("div",{"class":"bgbox-bt zzfwbox"})
plat_pro = BeautifulSoup(str(plat_pro),"lxml")
L1 =[]
L2 =[]
zzzj = ""
gqss = ""
yhtg = ""
rzjl = ""
jgxh = ""
ICP = ""
zdtb = ""
zqzr = ""
tbbz = ""
bzms = ""
for div in plat_pro.findAll("div",{"class":"l"}):
L1.append(div.get_text().strip())
for div in plat_pro.findAll("div",{"class":"r"}):
L2.append(div.get_text().strip())
for slzz in L1: #获取平台的备案信息
if slzz =="注册资金":
zzzj = L2[L1.index(slzz)]
if slzz =="股权上市":
gqss = L2[L1.index(slzz)].replace(" ","")
if slzz =="银行存管":
yhtg = L2[L1.index(slzz)]
if slzz =="融资记录":
rzjl = L2[L1.index(slzz)].replace(" ","")
if slzz =="监管协会":
jgxh = L2[L1.index(slzz)].replace(" ","")
if slzz =="ICP号":
ICP = L2[L1.index(slzz)]
if slzz =="自动投标":
zdtb = L2[L1.index(slzz)]
if slzz =="债券转让":
zqzr = L2[L1.index(slzz)]
if slzz =="投标保障":
tbbz = L2[L1.index(slzz)]
if slzz =="保障模式":
bzms = L2[L1.index(slzz)]
plat_info.append(plat_name) #这个地放用了很笨的方法,一个个的添加元素到列表中,存在优化空间
plat_info.append(time_s)
plat_info.append(location)
plat_info.append(duration)
plat_info.append(yield0)
plat_info.append(rates)
plat_info.append(zzzj)
plat_info.append(gqss)
plat_info.append(yhtg)
plat_info.append(rzjl)
plat_info.append(jgxh)
plat_info.append(ICP)
plat_info.append(zdtb)
plat_info.append(zqzr)
plat_info.append(tbbz)
plat_info.append(bzms)
plat_profile.append(plat_info)
print("------------->"+plat_name+str(lists.index(site))) #打印爬取的平台信息
return plat_profile
plat_profile = plat_profile(conditions(1)) #conditions根据平台类型的不同来设置,为1则表示正常运营平台
name = ['平台名称','上线时间','区域','投资期限','平均收益率','评分',
'注册资金', '股权上市', '银行存管', '融资记录', '监管协会',
'ICP号', '自动投标', '债权转让', '投标保障', '保障模式']
operating = pd.DataFrame(columns=name,data= plat_profile)
operating.to_csv(r"""C:\Users\95647\Desktop\operating.csv""") #path to save csvfile
写该代码之前,还没有学习panda的用法,所以简单粗暴的用列表和字典来解决问题,会使用pandas的朋友可以用pandas来进行优化。爬虫运行过程如下:

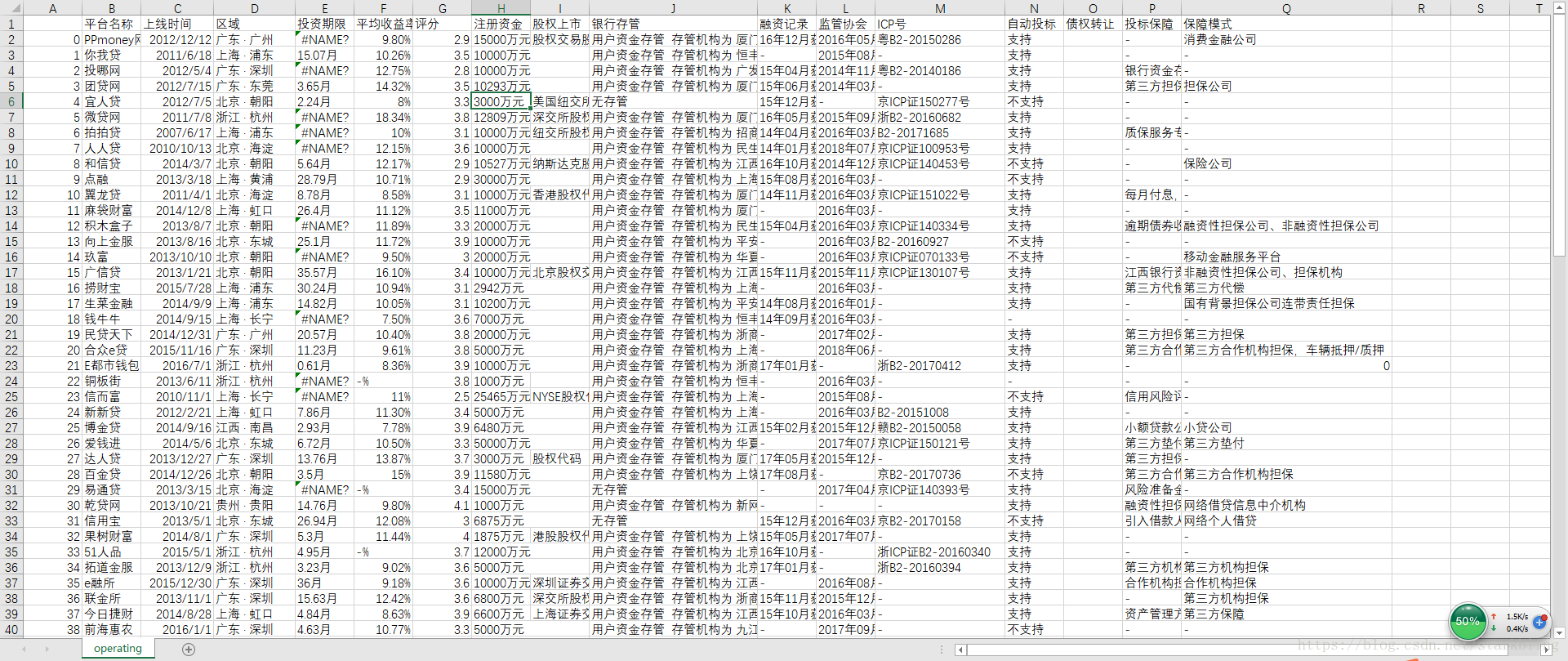
该爬虫运行速度很快,我爬取了100个正常运营平台的信息,才用了5分钟左右,部分爬虫结果如下:
有问题的和其他想法的朋友,欢迎加QQ:956471511交流,这里还有一篇关于如何爬取人人贷网站数据的博文,有兴趣的朋友可以看一下。手把手教你用python爬取人人贷借款人数据