链接 代码地址入口文件是TaskSchedule.py
最近在练习写爬虫的时候,正巧同学的女朋友有需求,大概是爬取知网内的几千个主题的数据,每一个主题的条数记录有几条的到几千条的不等,总来的来说也算是个上万数量级的爬虫了,分析了下知网,发现使用专业检索,可以完成我的目标,然后通过chrome的developer tools大概分析了下了请求数据包,发现知网的查询是分成两步的,第一步是一个总的请求(查询的条件基本上都在第一步里面了),会返回一个串

然后才能做第二步的数据请求(下方的截图对应网页上的不同区域的请求报文头和返回数据)
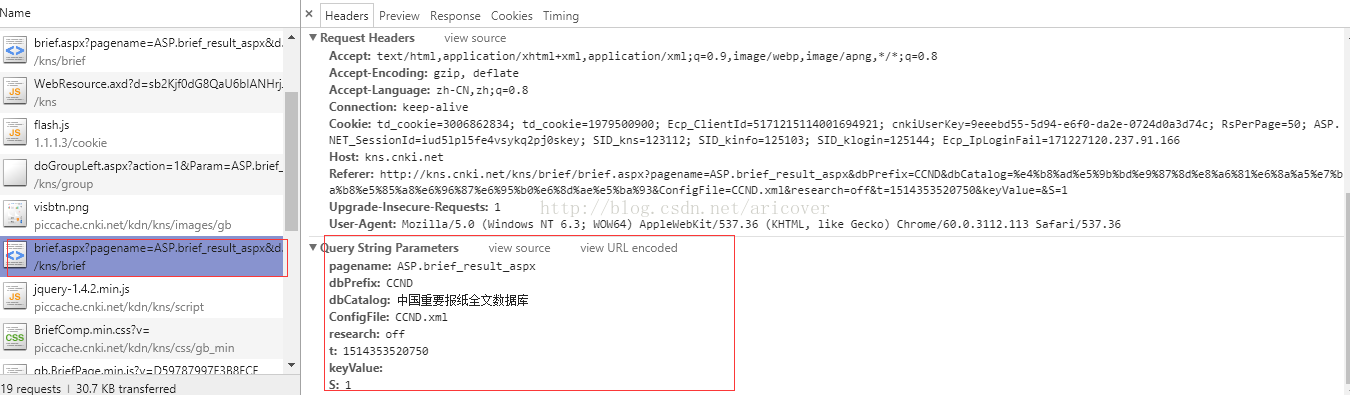
图一.查询记录请求报文头

图二. 对应不同年份的记录条数返回结果
至于为什么要分成两步,每一个区域对应一个不同的请求,这些都是网站本身的设计,我也没做过web开发,这么做有哪些优点我确实不清楚/擦汗,我的重点就是模拟它在网页上的请求,实现批量化的数据获取。
然后,大概就摸清楚了这一个数据获取的过程,我的思路是先完成一个数量级的数据获取,也就是爬取一条,然后再去扩展,加线程,加ip代理,加user_agent等等。
在这个阶段,重要的思路就是基本上要和在网页上的访问保持一致,保证自己拼的url和在网页上访问的时候是一致的,当然是在保证能访问的前提下,能略去的就略去。
分析它原本的请求url的时候,使用url转码工具可以将转码以后的url还原,更直白地分析。
然后提几个细节吧,知网的请求url上,有一些数据段一开始是不明白它的意义的,但是自己去拼接访问的时候发现,缺了网站就会报错,这时候就可以多尝试几个不同的访问,去拿它的请求heads,然后互相对比,就会发现有的字段是固定不变的,这种就可以直接照搬,有的呢,是变化的,这种就需要仔细去分析到底是什么数据,有什么意义,知网的就包括一个毫秒数,这个我一开始就没懂具体意义,后来分析了下感觉像时间,然后去取了下当前的毫秒时间,一对比发现大概是差不多,就当前的毫秒时间拼在了url串上面。
def getMilliTim():
t = time.time()
nowTime = t*1000
return int(nowTime)总而言之,就是对于像我这种不怎么懂web的爬虫小白,最好就是还原网站原本的请求,这样基本上请求数据就不会有太大问题了。
在完成了数量级为一的级别后,就开始准备大范围地获取数据了,这时候就要思考效率以及防止网站踢人了。
在遭遇了各种socket 10054 10061等错误,通过百度各种技巧,加上了ip代理等一些措施,最终我还是完成本次任务,当然最后还是加上了文件读取,任务队列等模块,大概就是一个线程专门负责输出文件,其它四个线程去任务池里面取任务爬数据,详细略过,见代码。有纰漏之处,还请斧正。