前言
由于毕设是要对股票的新闻报道进行情感分析,所以爬取所有股票的个股资是必要的前提工作了。一开始准备直接在[东方财富网]( http://quote.eastmoney.com/stocklist.html)上爬取所有的个股资讯,但是在获得个股资讯列表的时候要模拟事件。
前提工作
1. 安装python3
([下载地址](https://www.python.org/downloads/)),在安装的时候选择添加到环境变量,如果没有选择,可以通过【右键我的电脑】->【属性】->【高级系统设置】->【环境变量】->【path】将安装的Python3的路径添加到path中。
2. 通过命令行安装requests库:
>pip install requests
3.安装 lxml
>pip install lxml
4.安装pyquery
>pip install pyquery使用详情见[静觅](https://cuiqingcai.com/) » [Python爬虫利器六之PyQuery的用法]( https://cuiqingcai.com/2636.html)
5.安装pymysql
前提是先安装好mysql,然后同样采用>pip install pymysql
爬取数据
1. 爬取所有股票代码
url为东方财富网的股票代码查询一览表(http://quote.eastmoney.com/stocklist.html)。这是一个静态的网页,爬取比较简单.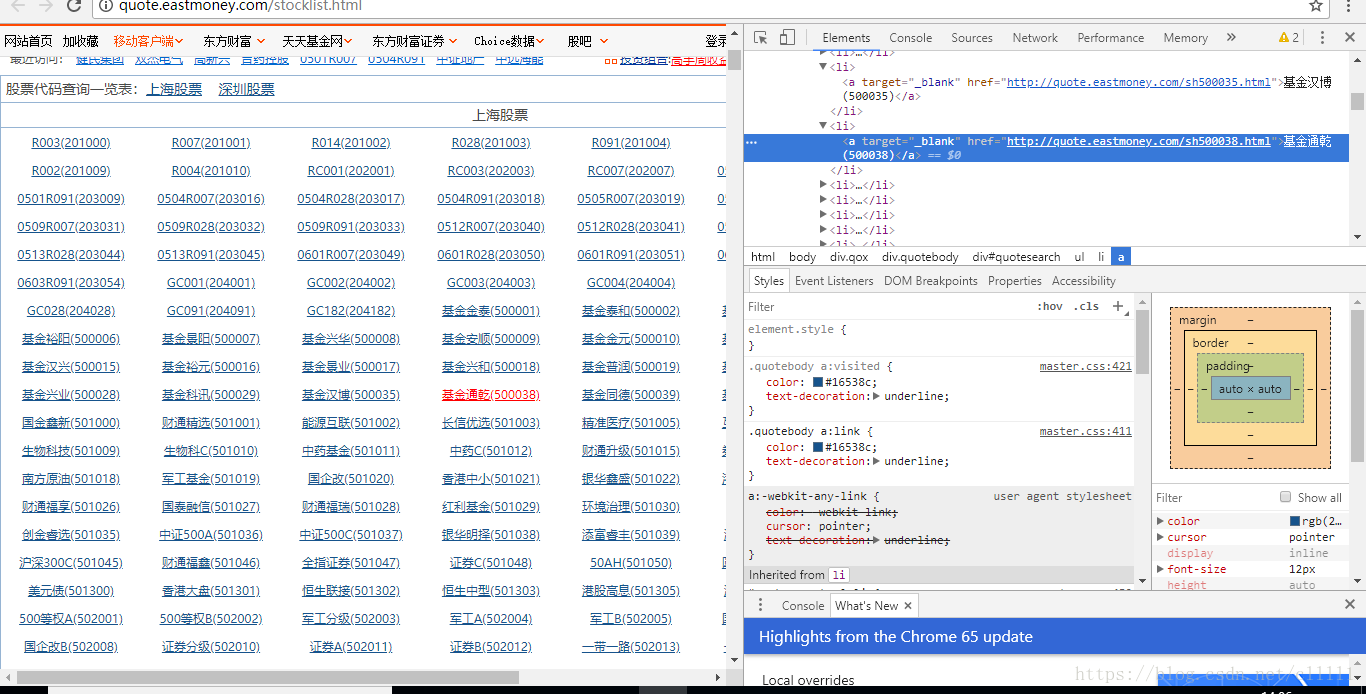
分析网页的结果,由图片可知,股票代码为target为_blank的a标签的文本括号中的文字,股票名称为括号前的文字。因此对获得的text利用split函数进行处理得到股票代码和股票名称。
def getCodes():
codes=[]
url='http://quote.eastmoney.com/stocklist.html'
req =requests.get(url,timeout=30)
reporthtml=req.text
html = pq(reporthtml)
#print(html)
stock_a_list = html("#quotesearch ul li a[target='_blank']").items()
for stock_a in stock_a_list:
num = stock_a.text().split('(')[1].strip(')')
if (num.startswith('1') or num.startswith('5')or num.startswith('2')): continue # 只需要6*/0*/3*/2*开头的股票
sname = stock_a.text().split('(')[0]
record = {}#用于存储个股的代码,和名称
#进行转码
sname = sname.encode("iso-8859-1").decode('gbk').encode('utf-8')
result = str(sname, encoding='utf-8')
print(result)
record["sname"]=result
record["num"]=num;
codes.append(record)
return codes
2. 爬取所有股票代码
得到股票代码知乎就需要获取个股的详情页,这个我们通过新浪财经获取比较简单。* 分析地址
分析多个个股的公司资讯的地址http://vip.stock.finance.sina.com.cn/corp/view/vCB_AllNewsStock.php?symbol=sz000725&Page=3
可知**http://vip.stock.finance.sina.com.cn/corp/view/vCB_AllNewsStock.php?symbol=**+(sz或sh)+代码+&Page=+页码。其中当为深圳时为sz,上证时为sz。
* 分析网页&去除退市和未上市股票
通过requests和pyquery得到html代码之后,分析网页结构。首先去除未上市的股票和已退市的股票。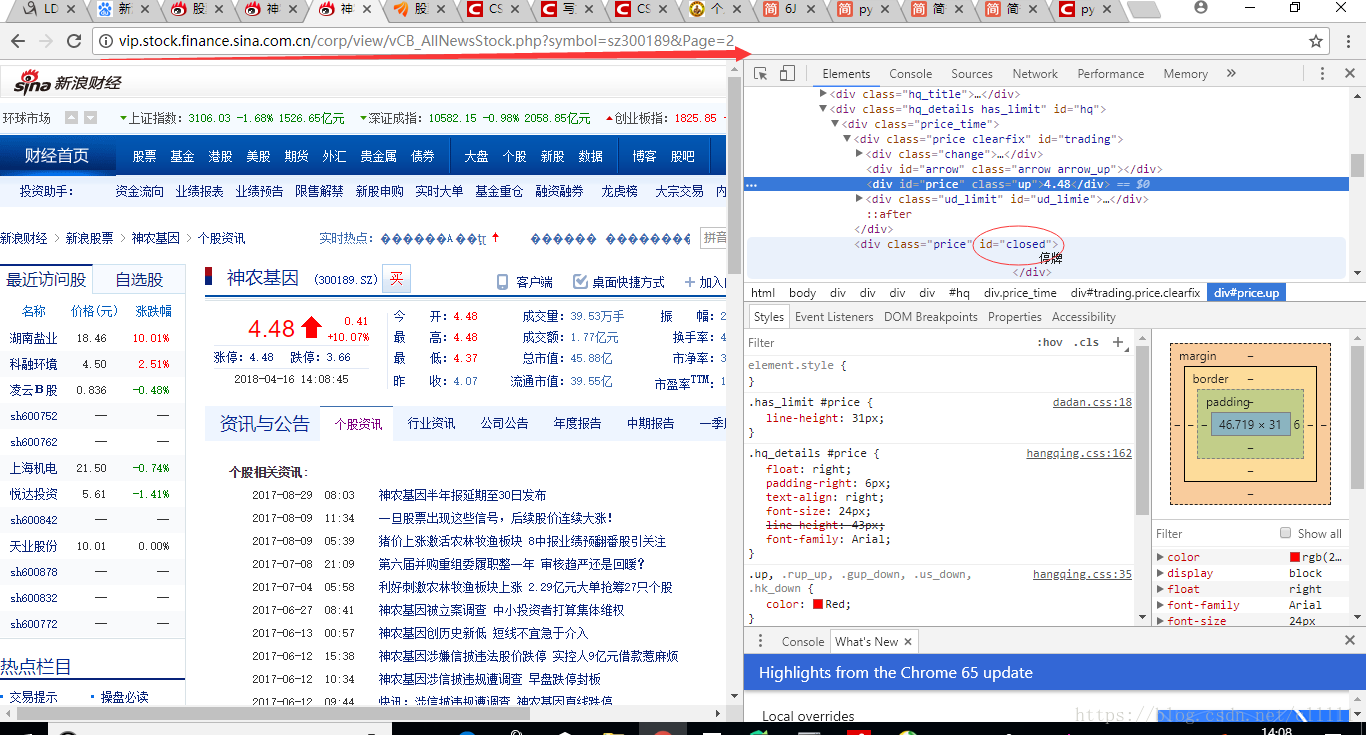
isclose = report_list_wrap("#closed")
f isclose=="已退市" or isclose=="未上市":
flag=False;
continue
*分析网页之报道结构
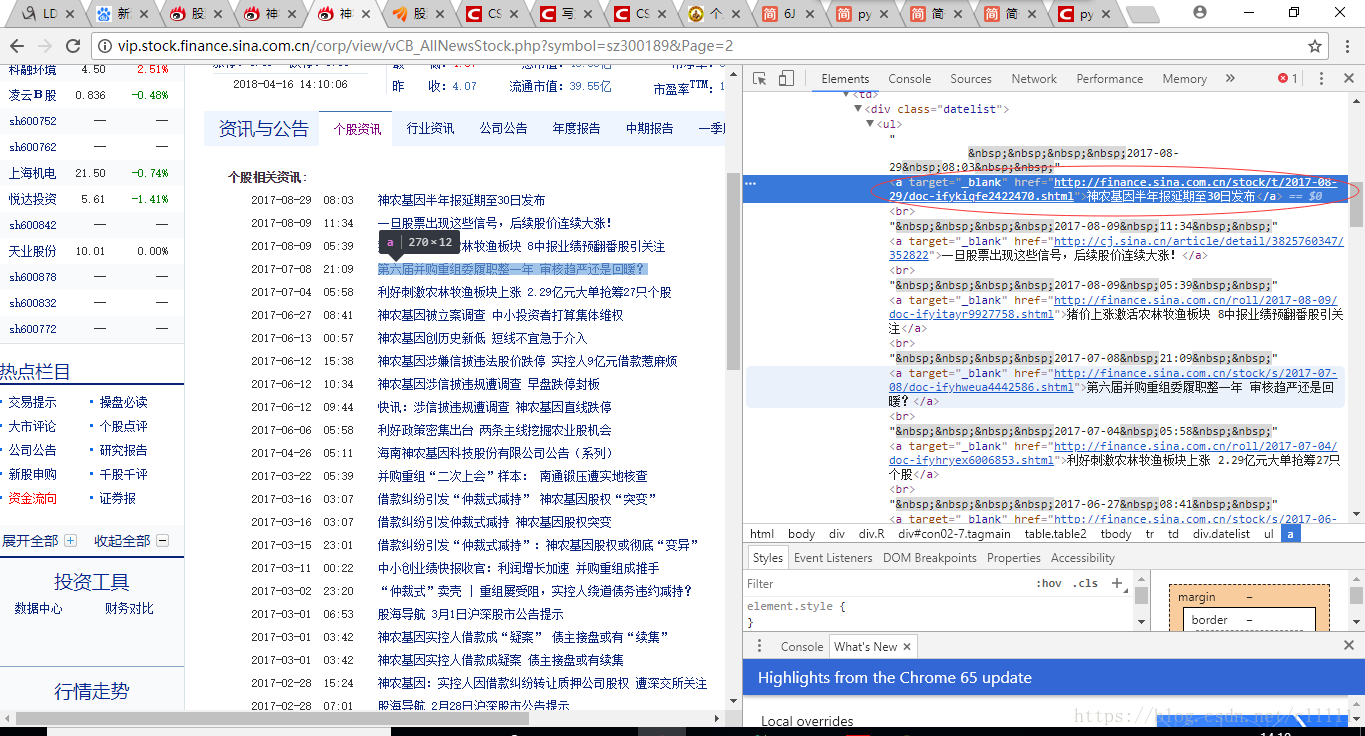
个股资讯为class=datelist的div中的所有a标签。通过获取a标签的href可以得到资讯报道链接,通过链接获取报道内容
report_list=report_list_wrap("#con02-7 .datelist ul a").items()
# **************************************遍历个股的资讯
for r in report_list:
try:
#转码
report_title= r.text().encode("iso-8859-1").decode('gbk').encode('utf-8')
report_title = str(report_title, encoding='utf-8')
print("标题:"+report_title)
#获取报道链接并得到报道
report_url = r.attr("href")
req = requests.get(report_url, timeout=30)
reporthtml = req.text
reporthtml = pq(reporthtml)
content = reporthtml("#artibody").text()
except:
flag = False
print(code['num'] + report_title + "报错了")
* 分析网页之解决编码问题:
在通过上步解析得到报道内容会发现是乱码的,这是因为本身的编码为ISO-8859-1,不是我们默认的utf8,,由此解决办法如下:##解决编码问题
#print(req.encoding)
if req.encoding == 'ISO-8859-1':
encodings = requests.utils.get_encodings_from_content(req.text)
if encodings:
encoding = encodings[0]
else:
encoding = req.apparent_encoding
reporthtml = req.content.decode(encoding, 'replace').encode('utf-8', 'replace')
小贴士:
utf8编码的文本可以用iso8859-1的编码表示,但是反过来不行。iso8859-1是单字节编码,而utf8是定长编码,从utf8转化成iso8859-1相当于是高精度转化成低精度,造成精度丢失,所以不可逆。根本原因是因为utf8中文,在iso8859-1没有匹配的位置。参考:
https://blog.csdn.net/kelindame/article/details/75014485,
https://www.cnblogs.com/GUIDAO/p/6679574.html
插入数据库
最后就是将获得数据插入数据库了。sql = ("insert into stock(rid,scode,sname,rdate,rtitle,report,emotion) VALUES (%s,%s,%s,%s,%s,%s,%s) ")
data_report = (str(id), code['num'], code['sname'],rdate,report_title, content, '-2')
id = id + 1
try:
# 执行sql语句
cursor.execute(sql,data_report)
print(code['sname']+"插入成功")
# 提交到数据库执行
db.commit()
except Exception as e:
print('perhaps timeout:', e)
db.rollback()
好嘞,这样子就完成了我们的爬虫工作了
我是c6j,一个有仪式感的程序媛