多元线性回归方程
多元线性方程
当我们要预测的Y值受到多个变量的影响时,即有多个特征量,需要建立多变量的方程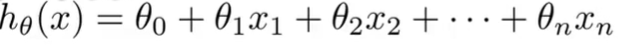
以吴恩达老师课上用到的房价预测为例,
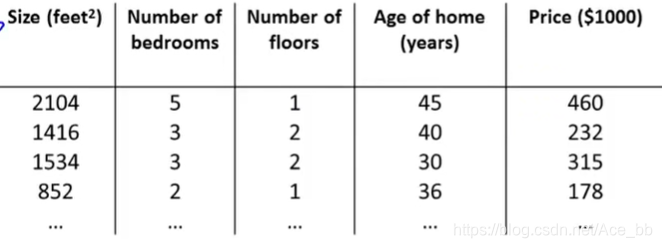
房价受到面积,房间数量,楼层数,房子年龄因素影响。
每一组数据和假设θ值看作一个一维(n+1)*1的向量。

θ的转置矩阵乘以x的向量就是对于的Y值。如下:

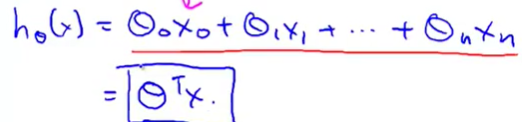
梯度下降法解多特征的线性回归方程
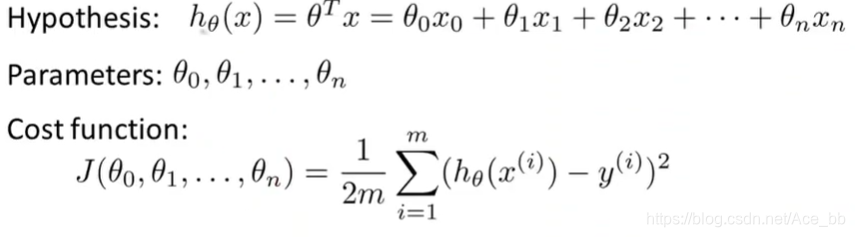
在求线性方程时假设θ值,来求代价函数的值,通过不断假设θ来找到使代价函数取最小值的θ值。
注意在计算时可以将每一组x的数据看作一维向量,θ的取值也看作向量。
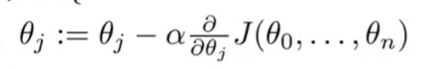
不断的用θj减去α倍的导数项来替代θj
α后面的为代价函数对参数θj的偏导数。
用以下公式来迭代向量θ的值。
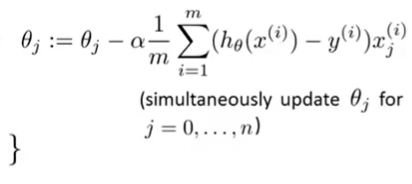
以上是通用公式。x的上标i表示的是第i组数据,下标j表示的是第i组数据中的第i个数据。当j=0时,x=1;
下面是几个举例。
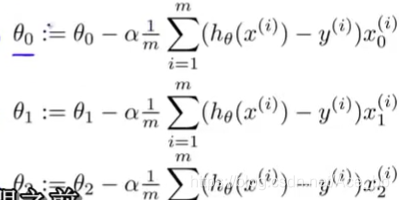
梯度下降运算中的使用技巧
特征缩放
在机器学习问题中有多个特征,若能确保这些特征都处在一个相近的范围内, 意思就是不同的特征取值,在相近的范围内,这样梯度下降法就能更快地收敛。
比如在房价预测问题中,如果有两个特征变量,x1和x2。 如果x2和x1的取值范围相差非常大,假设x1的取值范围在(0—2000),而x2的取值范围在(1—5)画出来的代价函数图像回非常的扁长。如图:
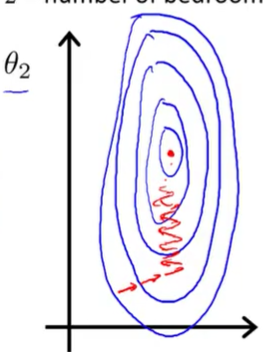
如此在对代价函数用梯度下降法时回花费非常多的事件,效率很低。解决这个问题的一个方法就是特征放缩。
方法就是把x1和x2的取值范围都化为-1~1。除以一个范围内最大的数即可,如下:

如此一来可以使代价函数的图像更加接近圆,用梯度下降法也能更快找到最低点。
总而言之,在进行特征放缩时就是将特征量的取值范围放缩到-1~1的范围
但并不是一定要化到-1~1,如果一个特征量的范围是0-3也可。只要范围较小,上下限相差较近,并且特征量之间差别不大即可。也不用小到0.00001的程度。
均值归一化
用xi-ui来代替xi,使得特征值的取值范围具有为0的平均值。如图:

归一化公式如图:
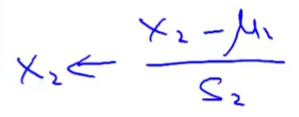
ui 为xi取值范围最大值和最小值的平均值。Si为最大值减去最小值。
学习率α
即梯度下降算法的更新规则 解决如何选择α的值
总体而言,如果α太小,会导致收敛速度慢,如果α太大,可能导致梯度算法迭代不会减小,而离散,不收敛。
α的取值可以考虑按照
… 0.001 0.01 0.1 1 … 来计算代价函数j(Θ)的最小值。每次改变10倍。
如何判断代价函数是否已经收敛,吴恩达老师的视频课中讲解如下图:
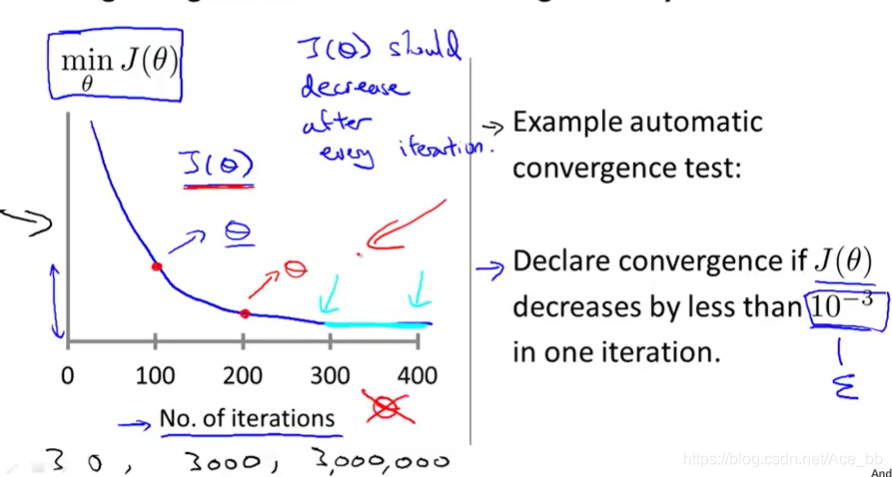
此图同时也可以检测代价函数是否正常工作。
横坐标为迭代步数,纵坐标为代价函数J(θ)的值。 当两次迭代 J(θ)的差值小于0.001时,则认为代价函数J(θ)收敛。
如果出现下面几种情况则说明梯度下降算法没有正常工作。
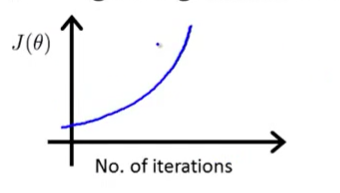
这样的曲线通常意味着使用的学习率α较小。
如果代价函数没有下降,相应变化波动较大,则通常是α过大。
选择特征的方法和如何得到不同的学习算法
有的适合,通过定义新的特征,可以得到一个更好的模型
多项式回归
以一个住房价格的预测为例,数据集如图:
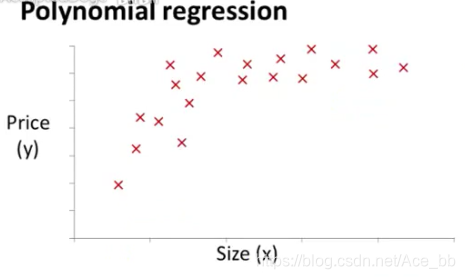
为了拟合这个数据集,可以选择一个这样的二次模型
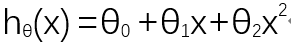
显然,二次回归方程能比线性回归方程更好的拟合这个数据集。但由于二次函数的对称性,存在递增的过程,也存在递减的过程,而递减过程在房价预测中是不太可能的。所以三次回归方程可能比二次更适合拟合这个数据集。如下:
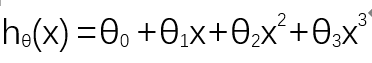
为了运用我们之前学的梯度下降法拟合数据集,可以对三次回归方程做一些修改变成以下形式。
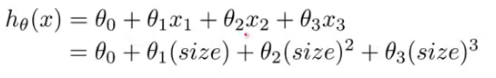

这个方法的关键在于特征的归一化,因为经过次方计算后的范围将会变得非常巨大,会严重影响代价函数的图像,梯度下降法的工作效率。
也就是说多元回归方程可以通过修改来变成线性回归方程,以便于我们拟合数据集。关键在于归一化
标准方程法
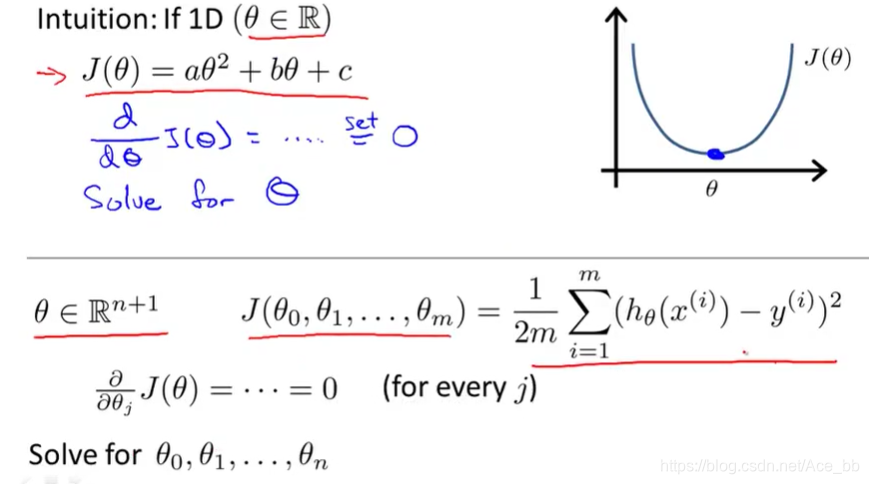
标准方程法提供了一种求线性回归方程中θ值的解析解法,与梯度下降算法的多次迭代求最优值的方法相比,我们可以直接一次性求解θ的最优值。 一步得到最优值
由微积分可知,求一元方程的最值可以通过令导数等于0来求解最值点。多元方程也可通过求解偏导数,并且偏导数全部等于0,也可以求出最值。但当特征量非常多时,求解过程依旧很麻烦,并且微分方程可能非常复杂,不适用于求代价函数。
这里假设一个有4组数据的数据集,如下图:
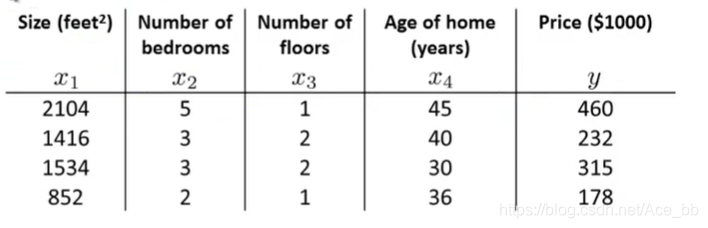
构建一个m*(n+1)维矩阵X,包含了训练样本的所有特征变量。这个矩阵也被称为设计矩阵。同时也将结果y值构成m*1维向量。θ值可以由图中的公式求出。这样就求出了能够使代价函数最小化的θ值。代价函数J(θ)。如下图:
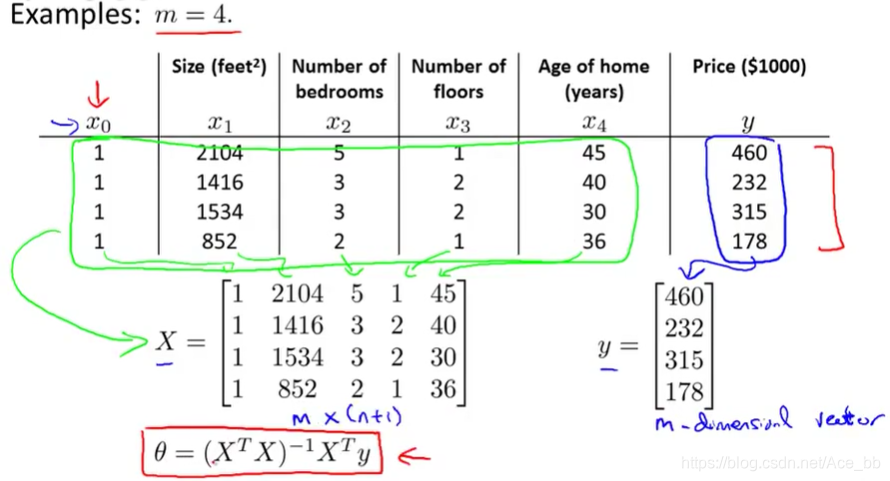 一般情况下的设计矩阵及向量如下图所示。几乎对所有的数据集都可以进行这样的处理,并运用公式求出θ值。
一般情况下的设计矩阵及向量如下图所示。几乎对所有的数据集都可以进行这样的处理,并运用公式求出θ值。
梯度下降法和标准方程法 如何选择?优缺点?
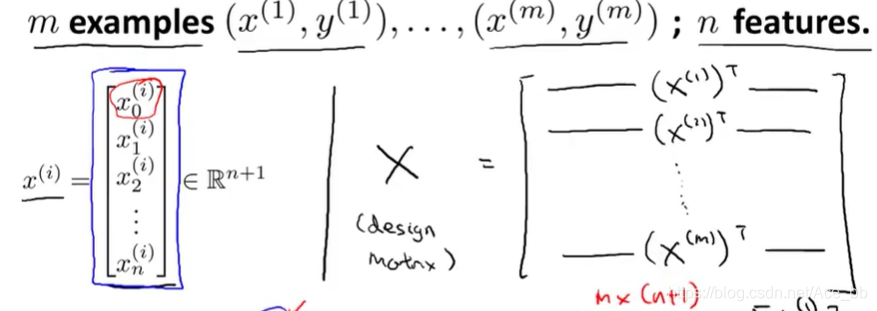
假设有m个训练样本的数据集和n个特征变量。
梯度下降法的缺点之一就是:
- 需要选择学习效率α,这就意味着需要尝试多次才能找到合适的学习效率α。
- 需要更多次的迭代
标准方程法的优点之一就是不用选择学习效率α也不用迭代多次。不用画代价函数图像,也不用判断代价函数是否收敛
标准方程法的缺点:
- 在特征量的数量非常庞大的适合,标准方程法为了求转置和逆会花费大量时间,效率降低,而梯度下降法依旧可以运行得很好。标准方程法大概会花n的三次方时间。
吴恩达老师的建议: 当特征量小于1万时选择标准方程法,大于1万时选择梯度下降法
