原文链接 小样本学习与智能前沿 。 在这个公众号后台回复“DKNN”,即可获得课件电子资源。


文章已经表明,对于将知识从整体模型或高度正则化的大型模型转换为较小的蒸馏模型,蒸馏非常有效。在MNIST上,即使用于训练蒸馏模型的迁移集缺少一个或多个类别的任何示例,蒸馏也能很好地工作。对于Android语音搜索所用模型的一种深层声学模型,我们已经表明,通过训练一组深层神经网络实现的几乎所有改进都可以提炼成相同大小的单个神经网络,部署起来容易得多。
对于非常大的神经网络,甚至训练一个完整的集成也是不可行的,但是我们已经表明,通过学习大量的专家网络,可以对经过长时间训练的单个非常大的网络的性能进行显着改善。每个网络都学会在高度易混淆的群集中区分类别。我们尚未表明我们可以将专家网络的知识提炼回单个大型网络中。
@
论文: https://arxiv.org/pdf/1503.02531.pdf
Bibtex: @misc{hinton2015distilling,
title={Distilling the Knowledge in a Neural Network},
author={Geoffrey Hinton and Oriol Vinyals and Jeff Dean},
year={2015},
eprint={1503.02531},
archivePrefix={arXiv},
primaryClass={stat.ML}
}

Abstract
We achieve some surprising results on MNIST and we show that we can significantly improve the acoustic model of a heavily used commercial system by distilling the knowledge in an ensemble of models into a single model.
We also introduce a new type of ensemble composed of one or more full models and many specialist models which learn to distinguish fine-grained classes that the full models confuse. Unlike a mixture of experts, these specialist models can be trained rapidly and in parallel.
1 Introduction
In large-scale machine learning, we typically use very similar models for the training stage and the deployment stage despite their very different requirements。
Once the cumbersome model has been trained, we can then use a different kind of training, which we call “distillation” to transfer the knowledge from the cumbersome model to a small model that is more suitable for deployment.
we tend to identify the knowledge in a trained model with the learned parameter values and this makes it hard to see how we can change the form of the model but keep the same knowledge.
A more abstract view of the knowledge, that frees it from any particular instantiation, is that it is a learned mapping from input vectors to output vectors.
When we are distilling the knowledge from a large model into a small one, however, we can train the small model to generalize in the same way as the large model.
An obvious way to transfer the generalization ability of the cumbersome model to a small model is to use the class probabilities produced by the cumbersome model as “soft targets” for training the
small model.
When the cumbersome model is a large ensemble of simpler models, we can use an arithmetic or geometric mean of their individual predictive distributions as the soft targets
When the soft targets have high entropy, they provide much more information per training case than hard targets and much less variance in the gradient between training cases, so the small model can often be trained on much less data than the original cumbersome model and using a much higher learning rate.
This is valuable information that defines a rich similarity structure over the data (i. e. it says which 2’s look like 3’s and which look like 7’s) but it has very little influence on the cross-entropy cost function during the transfer stage because the probabilities are so close to zero.
Caruana and his collaborators circumvent this problem by using the logits (the inputs to the final softmax) rather than the probabilities produced by the softmax as the targets for learning the small model and they minimize the squared difference between the logits produced by the cumbersome model and the logits produced by the small model.
Our more general solution, called “distillation”, is to raise the temperature of the final softmax until the cumbersome model produces a suitably soft set of targets. We then use the same high temperature when training the small model to match these soft targets. We show later that matching the logits of the cumbersome model is actually a special\ case of distillation.
The transfer set that is used to train the small model could consist entirely of unlabeled data [1] or we could use the original training set.
2 Distillation
Neural networks typically produce class probabilities by using a “softmax” output layer that converts the logit, \(z_i\) , computed for each class into a probability,\(q_i\), by comparing \(z_i\) with the other logits.
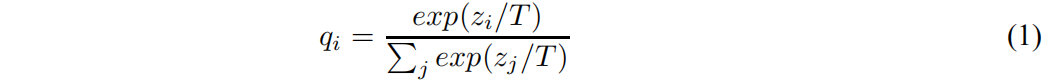
where \(T\) is a temperature that is normally set to 1. Using a higher value for \(T\) produces a softer
probability distribution over classes.
!!!! In the simplest form of distillation, knowledge is transferred to the distilled model by training it on
a transfer set and using a soft target distribution for each case in the transfer set that is produced by
using the cumbersome model with a high temperature in its softmax. The same high temperature is used when training the distilled model, but after it has been trained it uses a temperature of 1.
When the correct labels are known for all or some of the transfer set, this method can be significantly improved by also training the distilled model to produce the correct labels.
也就是半监督情况
One way to do this is to use the correct labels to modify the soft targets, but we found that a better way is to simply use a weighted average of two different objective functions.
- The first objective function is the cross entropy with the soft targets and this cross entropy is computed using the same high temperature in the softmax of the distilled model as was used for generating the soft targets from the cumbersome model.
- The second objective function is the cross entropy with the correct labels.
We found that the best results were generally obtained by using a condiderably lower weight on the second objective function.
2.1 Matching logits is a special case of distillation
The softmax of this type of specialist can be made much smaller by combining all of the classes it does not care about into a single dustbin class.
After training, we can correct for the biased training set by incrementing the logit of the dustbin class by the log of the proportion by which the specialist class is oversampled.
3 Preliminary experiments on MNIST
4 Experiments on speech recognition
4.1 Results
5 Training ensembles of specialists on very big datasets
5.1 The JFT dataset
5.2 Specialist Models
5.3 Assigning classes to specialists
5.4 Performing inference with ensembles of specialists
5.5 Results
6 Soft Targets as Regularizers
6.1 Using soft targets to prevent specialists from overfitting
7 Relationship to Mixtures of Experts
8 Discussion
We have shown that distilling works very well for transferring knowledge from an ensemble or from a large highly regularized model into a smaller, distilled model. On MNIST distillation works remarkably well even when the transfer set that is used to train the distilled model lacks any examples of one or more of the classes. For a deep acoustic model that is version of the one used by Android voice search, we have shown that nearly all of the improvement that is achieved by training an ensemble of deep neural nets can be distilled into a single neural net of the same size which is far easier to deploy.
For really big neural networks, it can be infeasible even to train a full ensemble, but we have shown that the performance of a single really big net that has been trained for a very long time can be significantly improved by learning a large number of specialist nets, each of which learns to discriminate between the classes in a highly confusable cluster. We have not yet shown that we can distill the knowledge in the specialists back into the single large net.