论文:G. Hinton, O. Vinyals, and J. Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015.
hinton大神2015年发表的蒸馏法,可以说掀起了一阵风潮啊~~本人很喜欢hinton大神的文章,当年SDAE看完也是这个感觉,simple is best!
这个方法主要目的是解决这样的问题,试想这样几个场景:1,为了提高模型的效果,往往会在尝试很多种算法模型,结果可能各个算法各有优劣,怎么将这些模型有效的融合起来,发挥他们的优势? 2,为了追求效果好和模型的泛化能力,用了很深很大的神经网络,结果在真实的工程应用中这个网络太大了,速度太慢怎么办?3,以前项目有一个很好的模型,现在新来了一批数据集需要训练一个新的模型,希望新学习的模型依然能继承以前的优点,怎么办?
MODEL COMPRESSION模型压缩从一定程度上解决了一些这样的问题,模型压缩核心思想是用一个快速的紧凑的模型来近似一个慢的、大的、性能好的网络(The main idea behind model compression is to use a fast and compact model to approximate the function learned by a slower, larger, but better performing model.“Model Compression”),后面大家提出了很多的方法来达到模型压缩的问题。蒸馏法算是一种新的“压缩”方法。
设想现在已有一个训练好的较大的网络,我们怎么去更好的学习这个网络的“知识”?
思想跟当年hard classification到soft classification很像,传统基于神经网络的分类任务是hard label,比如一张猫的照片,分类的标签会给0或者1,这个信息量是很小的,那如果我们多告诉网络一些信息,这张照片0.9的概率是猫,0.6的概率是老虎,0.1的概率是狗,这样同样的一张猫照片训练样本,信息量要多多了。蒸馏法学习的就是这样的一个目标函数:概率! 我们在回想下一般情况下小网络训练效果不及大网络的原因往往是大网络(更深的网络),有更好的泛化能力。(泛化能力是什么意思呢?就是在已有知识学习后能有更强且准确的推理能力)现在设想有一个泛化能力差的小网络,还有一个训练的不错泛化能力强的大网络,我们把除训练集以外的,大网络拥有的“泛化知识”这部分告诉小网络,是不是目标就达到了? 基于此, 有一个很巧妙的方法就是不用真实的0,1这种hard label,而用概率?概率的信息量丰富多了,比如刚才的例子,还是一张猫的图片,通过用蒸馏法去学习大网络,我们不仅可以告诉小网络这张图是猫(因为猫的概率最大0.9),而且这张照片也比较像老虎0.6,跟狗确实不大像0.1。基于此,相同的训练集,小网络就可以学习更多的大网络的“泛化知识”,比直接用训练集训练小网络效果要好得多。
Distilling the knowledge in a neural network.论文的蒸馏法训练学生网络时考虑了两方面信息。一是教师网络的soften输出
T作为教师网络,对应的softmax输出概率为:
![]()
某些情形,教师网络是一个网络时,aT表示的是输出层的权重和(即softmax输出,softmax(w*x));当教师网络是多个时,对应多个神经网络的输出层的平均。
类似的,学生网络输出概率为
![]()
所以我们的目标是希望学生网络学习的这个概率和教师网络的这个概率尽可能接近。
由于教师模型一般训练的较好,所以PT非常接近于真实的标签,所以我们加个大于1的松弛项,使得教师网络的概率更有区分度,同样的松弛项也加入到学生网络中。
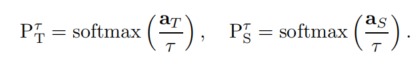
之后学生网络训练的目标函数就如下所示:
![]()
其中前一项为传统的label的损失函数,学习的是数据集的0,1标签,这一项也是原始最直接的目标,告诉网络猫就是猫,狗就是狗;第二项为从教师网络学习的损失函数,学习教师网络的“泛化知识”。