会议:2019 interspeech
单位:清华-CUHK联合实验室
abstract
受GST的启发,想到用global speaker embedding表示说话人的身份特征控制vc向目标说话人的转换,可以仅用一句话,不需要自适应就可以完成向新的说话人转换。PPGs作为local condition input送入condition wavenet 合成器用于生成波形;谱特征送入到reference encoder提取出reference embedding,然后作为query送入到GSEs生成speaker embedding,speaker embedding是控制波形的说话人特性的global condition input。
introduction
one-shot vc就是指仅用一句话完成到目标说话人的语音转换,是vc的极限目标。
之前的方法:
- VCC 2018用多说话人数据集训练了wavenet vocoder,然后用新的说话人数据对base 模型进行finetune。缺点:finetune需要时间,而且需要防止过拟合。
- IVC & SEVC的方法,用一个额外的speaker embedding extractor控制向目标说话人的转换。
- VAE的方法: 把speech分类成文本相关的信息,说话人相关的信息,但是需要一个设计好的分类损失函数做模型训练加以指导。
本文受启发于GST,采用一个conditional wavenet的模型,vc系统和speaker embedding的部分联合训练,网络中所有的参数都在波形产生的过程中被更新,不要单独的判别函数。因此,在向任何人转换时,不需要finetune。
model architecture
做了对比实验
adapt-VC system
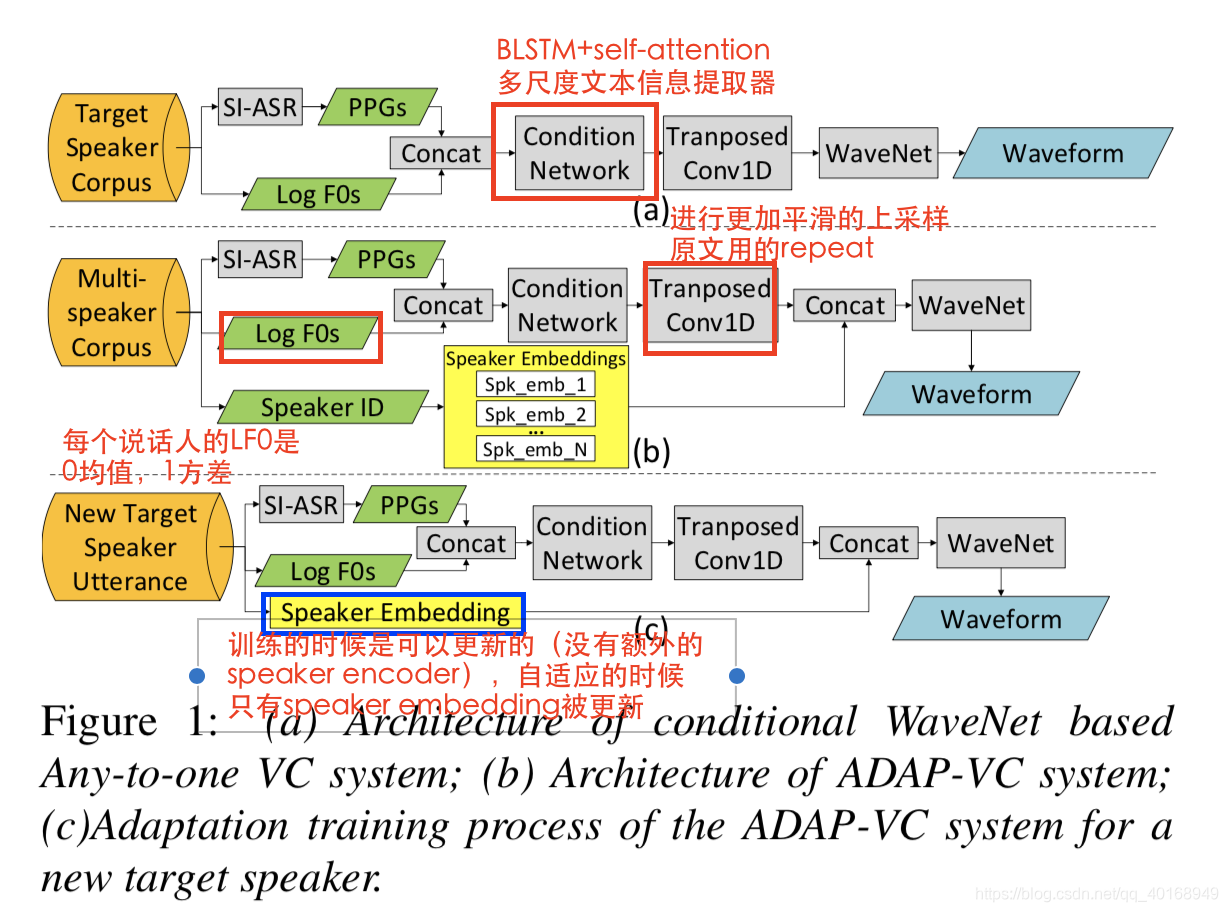
实现的细节可以看图,网络和我之前做的不太一样。
训练的时候对说话人的LF0全部进行归一化处理,消除speaker-dependent 特性,因此只是由speaker embedding控制。
自适应的时候只更新speaker embedding的部分。
GSE-VC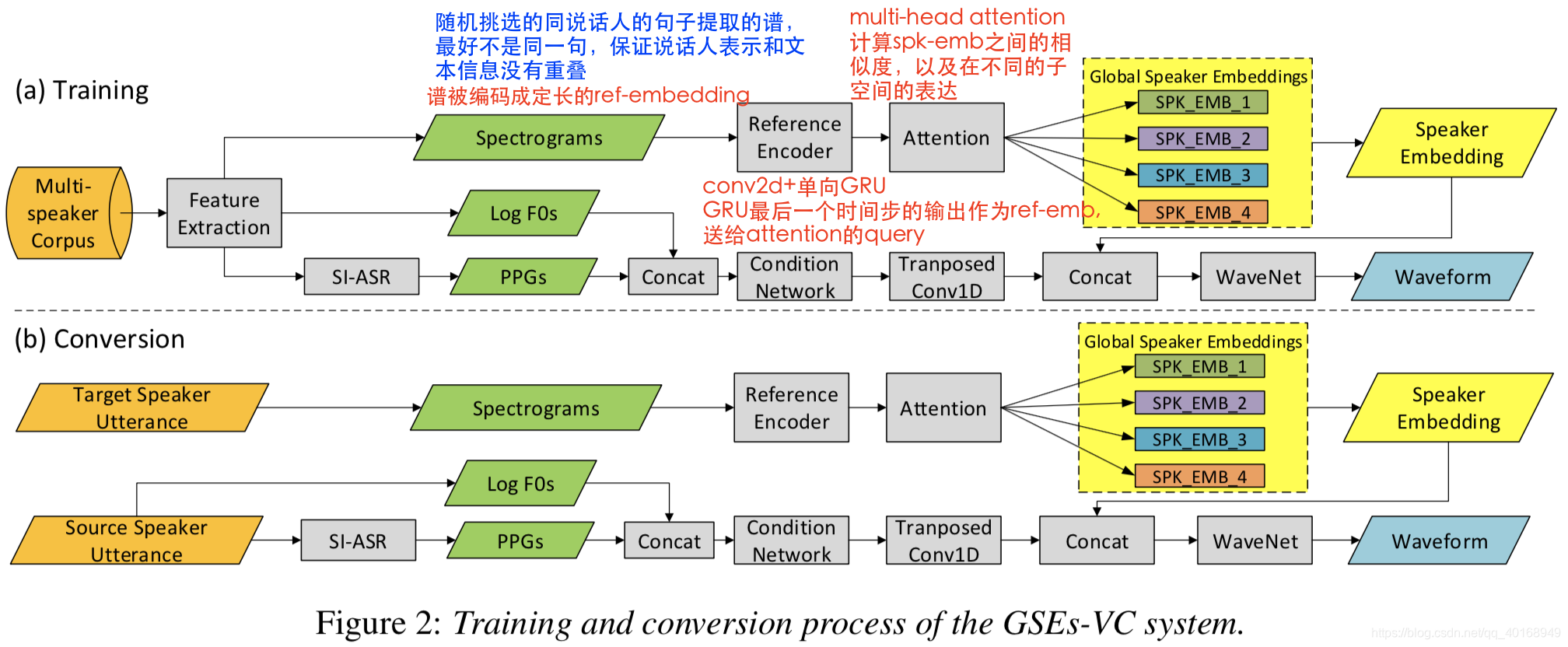
网络的详细可以看图。
解释GSE的原理:提供一个表示说话人身份特征的多维度base vector的空间,attention的操作就是在空间中用这些base vector把ref-emb编码成一个说话人表示,attention的权重可以认为是说话人身份在空间的坐标表示。
experiments
准备
训练数据集:VCTK-102 speaker
验证数据集:VCTK-102 speaker,每人10句
测试数据集:VCTK-4 unseen speaker(2 male, 2 female), 2个source,2个target, 组成f2f, f2m, m2f, m2m的转换。每个测试5个句子,15个受测者。
speaker embedding: 128-d
GSE中multi-head attention : 10个
结果
MOS评测的时候,在within-gender的差别不大, cross-gender的时候GSE-VC更好一些。
并且计算了GSE的10个向量之间的的cos-similarity,表明各个特征表达的内容不相交。
解释MOS值更好的原因:
GSE相当于有一块专门存储说话人身份相关的各个特征,当有一个新的说话人时,GSE-VC检查存储的区间,模仿这个新的说话人。
而ADAP-VC没有存储的模块,只能通过自适应的方法学习说话人特性。
ps.看到这里就会想,有时候一个人的一句话可变性比较大,并不一定让GSE-VC足够捕捉性能。是否可以提供继续训练的方法,一句提一个,多句提的更准确。
