VQVC+: One-Shot Voice Conversion by Vector Quantization and U-Net architecture
Abstract
Voice conversion 是要转换说话人的音色,口音,音调的同时保留内容。在one-shot的场景下是一个比较有挑战性的问题。基于Auto-encoder的VC不需要speaker identity就能够将speaker与内容解耦,因此对于没见过的speaker有泛化作用。常用的解耦方法有vector quantization (VQ), adversarial training, or instance normalization (IN). 但是解耦可能会损害音质。在本文工作中,在Auto-encoder架构的VC中应用了U-Net结构。为了应用U-Net结构,需要一个strong information的bottleneck,VQ-based方法能够实现这个目标。主观评测和客观评测表明音频自然度和说话人相似度perform well.
Introduction
传统方法,VC集中于one-one或者many-one的问题,应用parallel数据,parallel data收集起来比较困难。最近,many-many unparallel VC被研究(cycleGAN, starGAN, BLOW), 这些模型不需要解耦直接转换,实现了令人满意的音质。另一些工作通过替换speaker embedding实现转换。另外也有一些工作是通过layer dimension, IN , VQ来解耦内容。为了解耦需要一个很强的latent bottleneck, 音质被牺牲了。为了解决这个问题,本文提出了IN和VQ结合的解耦,并应用了U-Net的方法。与AutoVC和One-Shot Voice Conversion by Separating Speaker and Content Representations with Instance Normalization中的方法对比,VQVC+在主观和客观评测中表现更好。
Method
VQVC
VQVC是一个one-shot VC系统,通过重构loss得到的。核心的想法是,内容信息可以被表示为离散的codes,speaker信息被视为连续的representation和离散的code的差异。
VQVC架构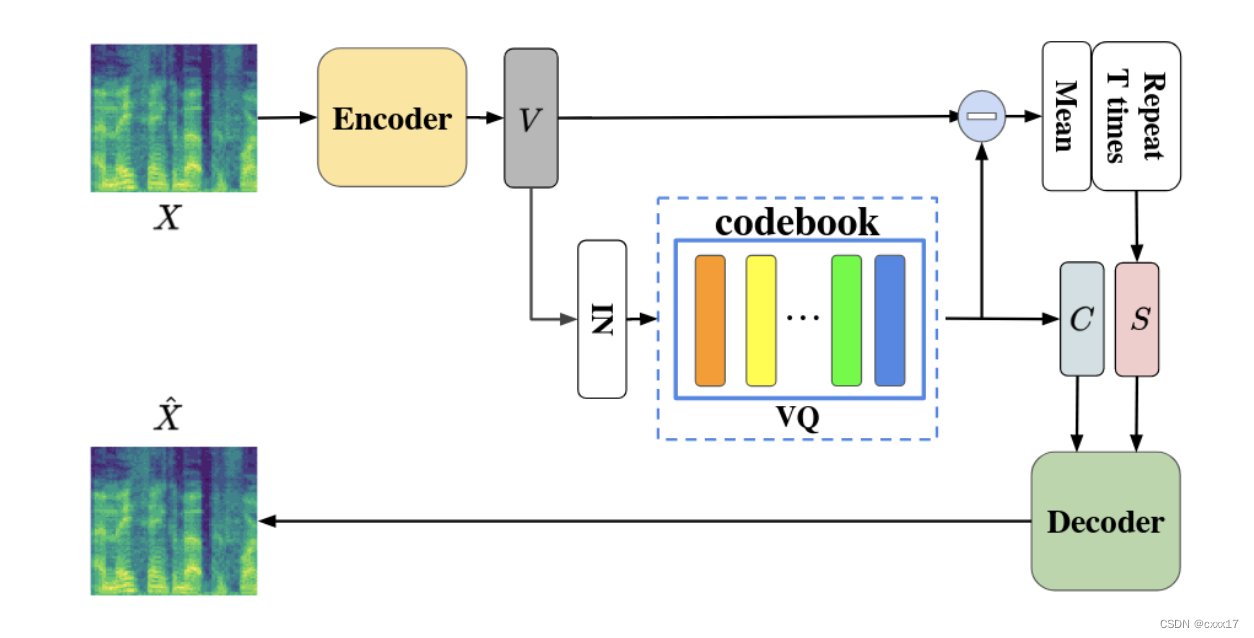
L r e c ( Q , θ e n c , θ dec ) = E X ∈ X [ ∥ X ^ − X ∥ 1 1 ] L_{r e c}\left(\mathcal{Q}, \theta_{e n c}, \theta_{\text {dec }}\right)=\mathbb{E}_{\boldsymbol{X} \in \mathcal{X}}\left[\|\hat{\boldsymbol{X}}-\boldsymbol{X}\|_1^1\right] Lrec(Q,θenc,θdec )=EX∈X[∥X^−X∥11]
L latent ( θ e n c ) = E t [ ∥ I N ( V ) − C ∥ 2 2 ] L_{\text {latent }}\left(\theta_{e n c}\right)=\mathbb{E}_t\left[\|I N(\boldsymbol{V})-\boldsymbol{C}\|_2^2\right] Llatent (θenc)=Et[∥IN(V)−C∥22]
L = L r e c + λ L latent L=L_{r e c}+\lambda L_{\text {latent }} L=Lrec+λLlatent
VQVC+
VQVC的音质受损,本文讲音质受损的原因归结为VQ导致了information loss,因此decoder在重构音频时不能够将内容正确重建。VQVC+应用了U-Net的结构帮助提升音质,结构如下。
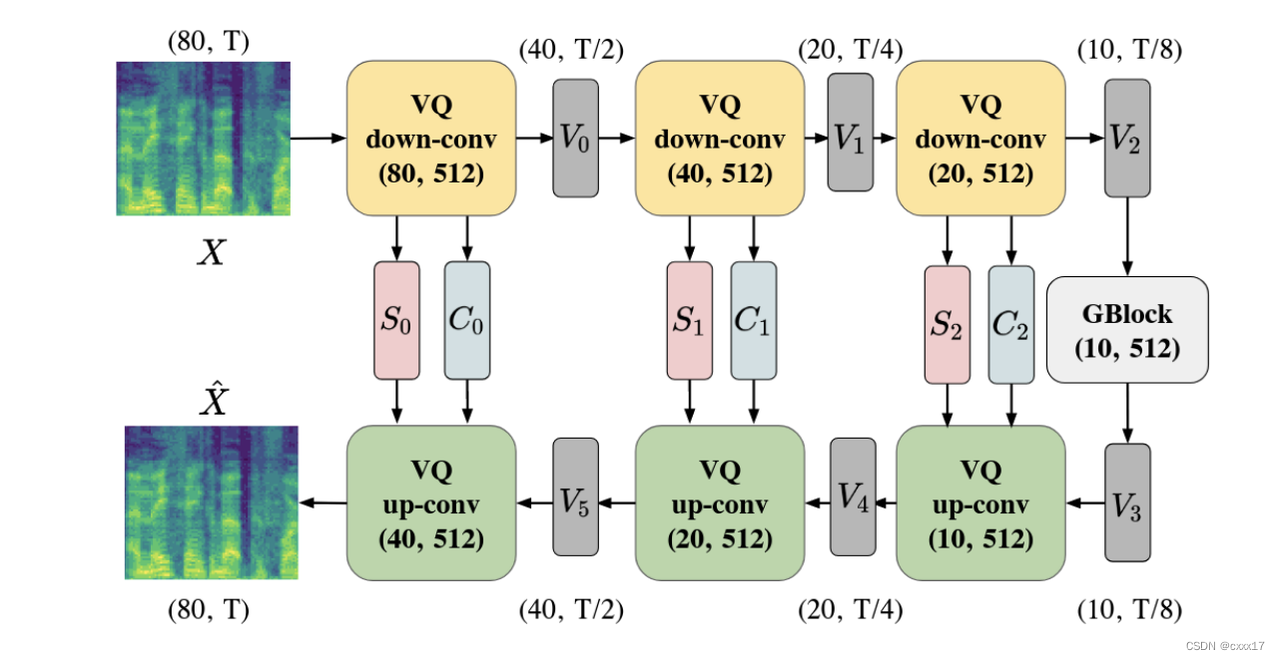
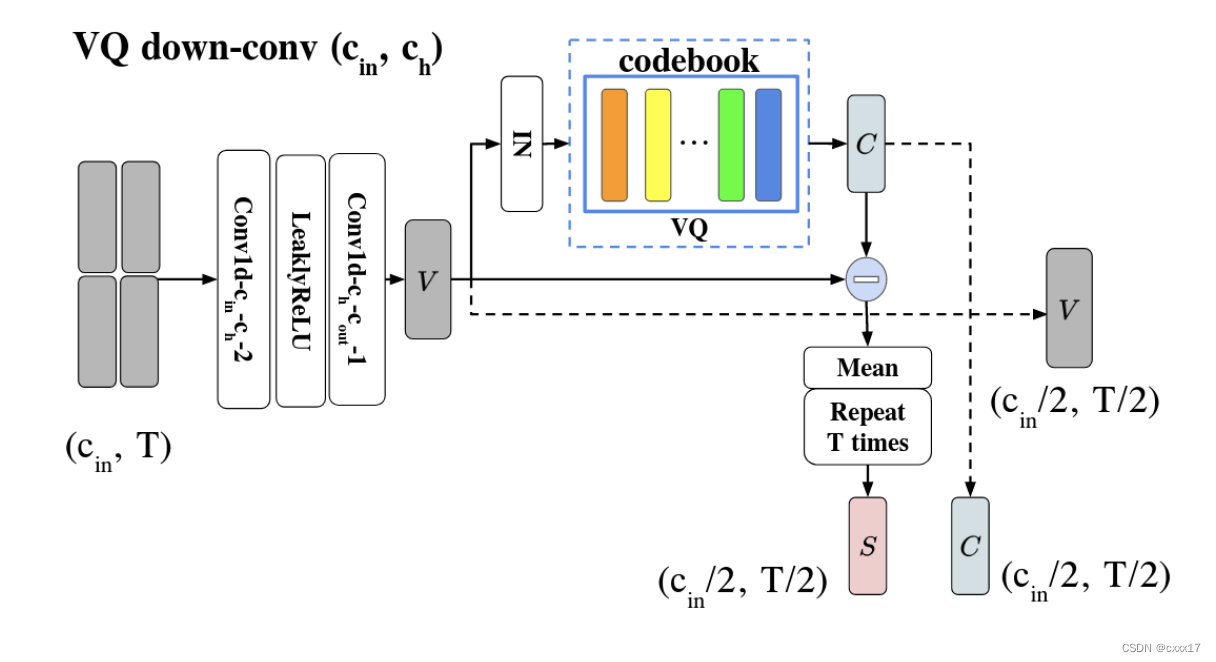
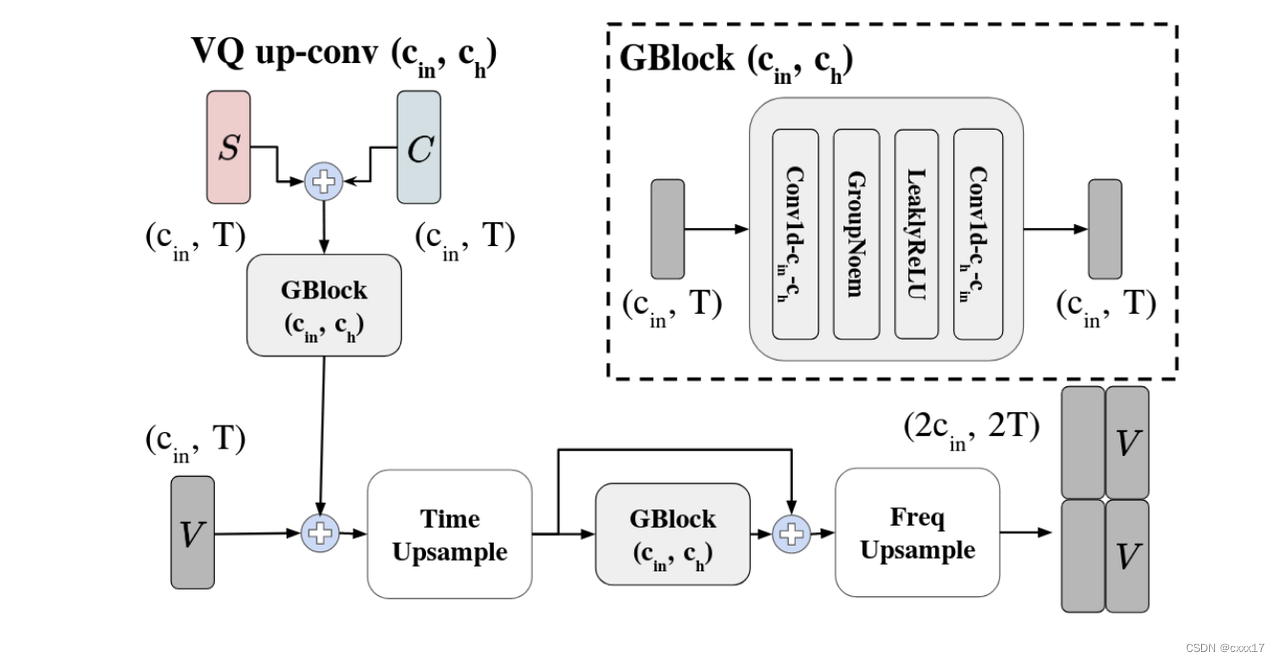
Experimental Setup
Datasets
VCTK
Training details
https://github.com/ericwudayi/SkipVQVC
Experiment
Content embedding
不同speaker的V_0和C_0
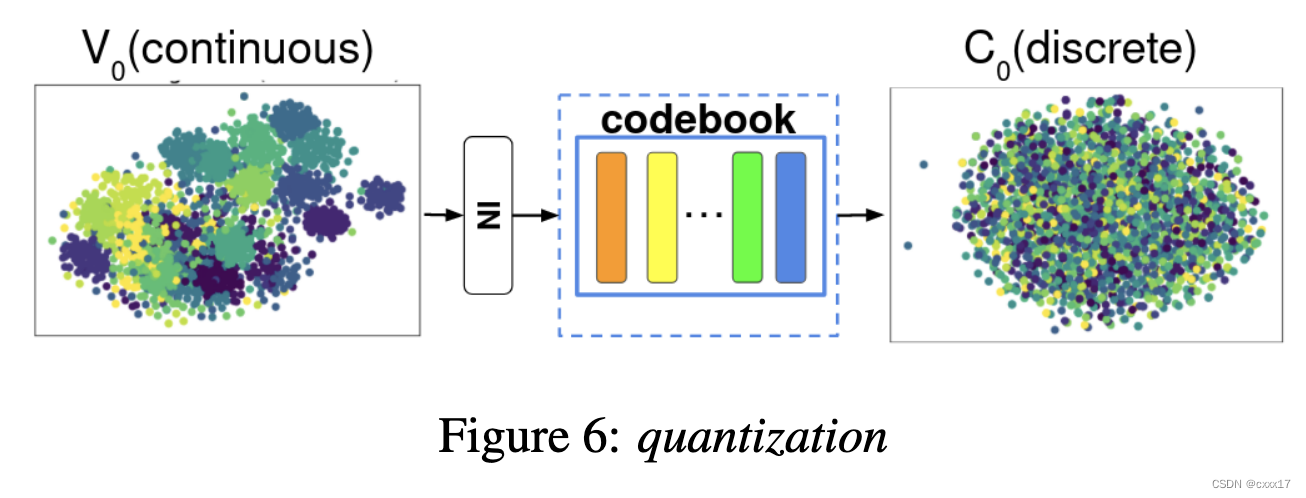
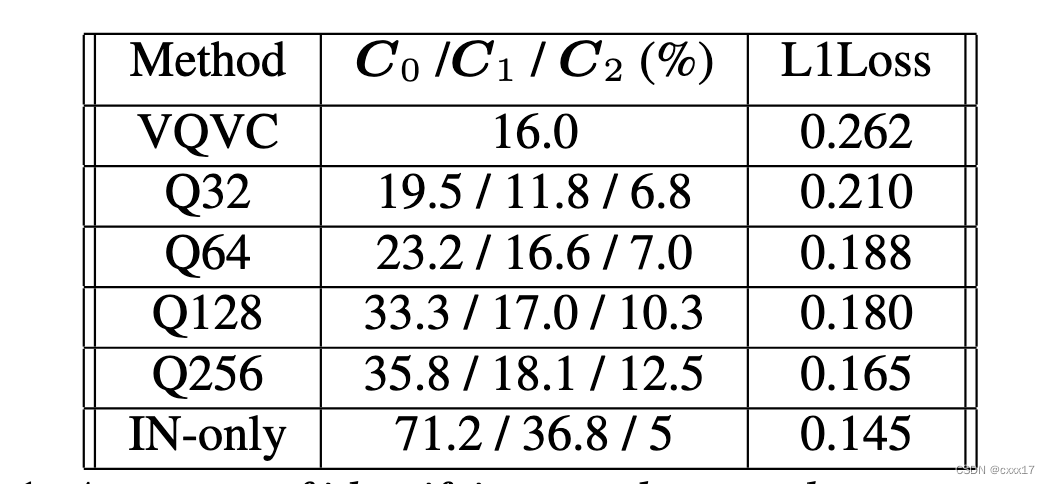
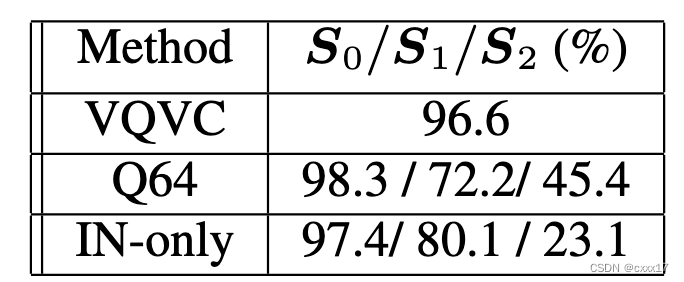
Speaker embedding
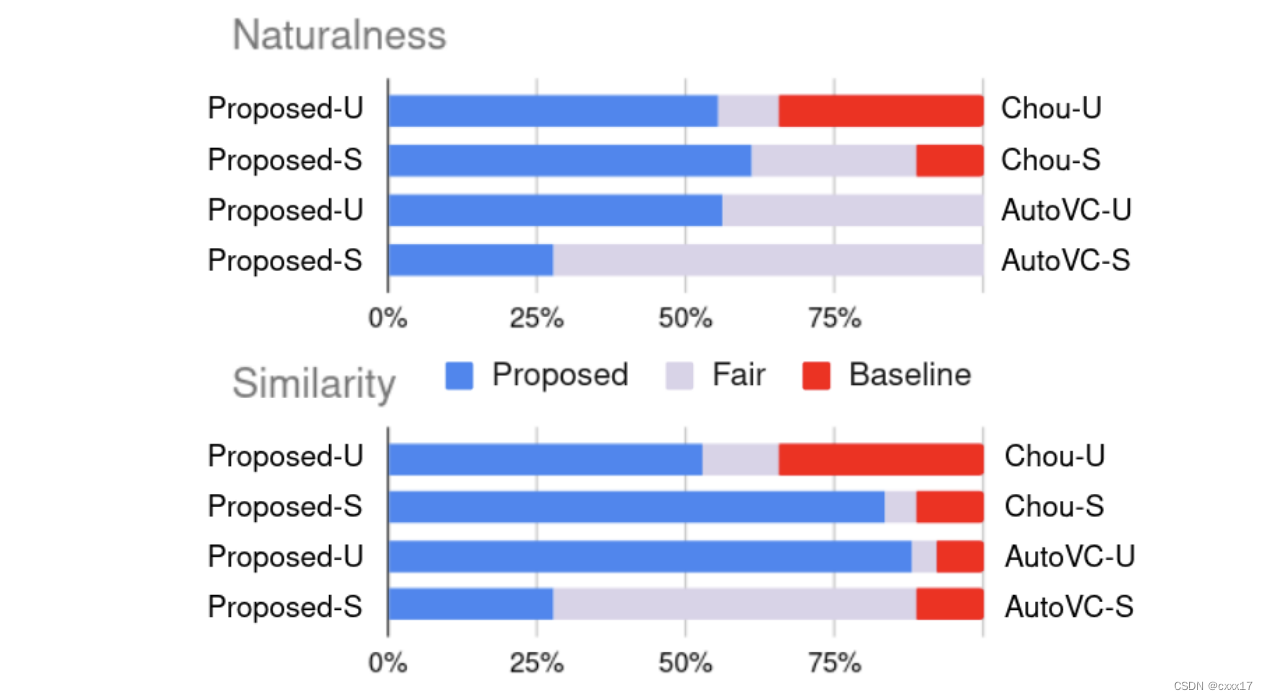
Subjective evaluations
![[图片]
[图片]](https://img-blog.csdnimg.cn/948d0a5d126c4be49999271de10cb4d1.png)