作者: Helen Meng
单位:港中文
abstract
非平行训练数据进行voice conversion
- 首先用一个SI-ASR(speaker-independent 语音识别系统)提取PPGs(Phonetic PosteriorGrams),这个PPGs可以对应于说话者的发音,并且对应于独立说话者的 说话内容。
- 然后用DBLSTM(deep bi-LSTM)建模PPGs和target speech声学特征之间的关系
ps.用相同 的SI-ASR模型将source speech转换出PPGs
1.introduction
非平行数据的实验结果不太好,也是可以理解的,因为想要将不平行的对齐和平行的对齐做的一样好比较难。【10】提出由EMA估计发声行为,认为不同说话者在说相同内容时有相同的发声行为 。建模target speaker的EMA和声学特征之间的映射,就可以通过source speaker的 EMA特征完成voice conversion。
但是EMA不容易获得,我们用PPGs作替代。PPG是一句话中特定时间帧的某个音素类后验概率time-verus-class matrix。
- 首先用一个SI-ASR(speaker-independent 语音识别系统)提取多说话者的PPGs(Phonetic PosteriorGrams),同一个SI-ASR可以均衡不同说话者的区别。SI-ASR使用kaldi speech recognition toolkit在timit数据集完成的(sec4),分成131个senone。
- 然后用DBLSTM(deep bi-LSTM)建模PPGs和target speech声学特征之间的映射关系,生成模型参数
- 送入source speech的PPGs,用训练好的DBLSTM作voice conversion。
ps.在转换过程中没有用到PPGs背后的任何语音信息。
优点:1⃣️不需要平行数据;2⃣️不需要对齐;3⃣️many-to-one的转换
2. beseline: DBLSTM-based with parallel training data
3.overview

3.2. PhoneticPosteriorGrams(PPGs)
PPG是 time-verus-class matrix,这个音素类可能是character、senone、phone,本文选用senone作为音素类。是和说话内容有关与说话者独立的特征。

3.3. Training Stages 1 and 2
stage1:DBLSTM的输入是SI-ASR提取的PPGs,输出是MCEPs序列(不是target speech的MCEPs)
stage2: YR是target的MCEPs,YT是直接得到的MCEPs
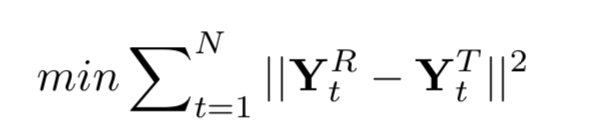
FBLSTM的训练仅用到了target speech的MCEPs特征和speaker-independent的PPGs特征。
3.4. ConversionStage
转换过程DBLSTM得到的MCEPs会和转换的F0、AP一起送入声码器用于语音合成。
F0、AP的转换和baseline一样。
4.experiments
CBHG

首先是conv1d_banks
- 模型先使用一系列的一维卷积网络,有一系列的filter,filter_size从1到K,形成一个Conv1D Bank。这样的作用相当于使用了一系列的unigrams, bigrams直到K-grams,尽可能多的拿到输入序列从local到context的完整信息。【与IDCNN类似,但IDCNN的参数量更小】
- 模型在最终的BiGRU之前加入了多层的Highway Layers,用来提取更高层次的特征。Highway Layers可以让梯度更好地向前流动;同时又加入一个类似LSTM中门的机制,自动学习这些高速公路的开关和流量。模型在最终的BiGRU之前加入了多层的Highway Layers,用来提取更高层次的特征。
- 模型中还使用了Batch Normalization(继ReLU之后大家公认的DL训练技巧),Residual Connection(减少梯度的传播距离),Stride=1的Max-pooling(保证Conv的局部不变性和时间维度的粒度)以及一个时髦的BiGRU。
- Tacotron: Towards End-to-End Speech Synthesis这篇文章发表在2017年4月,最潮的DL技术用到了很多。模型中还使用了Batch Normalization,Residual Connection,Stride=1的Max-pooling(保证Conv的局部不变性和时间维度的粒度)以及一个时髦的BiGRU。
CBHG参考:基于深度学习的中文语音识别系统框架