会议:2019 interspeech
单位:国立台湾大学
作者:Ju-chieh Chou, Hung-yi Lee
作者开源的github
BatchNormalization、LayerNormalization、InstanceNorm、GroupNorm、SwitchableNorm总结
Instance Normalization是对每张图片做归一化,更适合于style transfer这样的场景。
保证每张图片的风格,不与其他的混淆。
abstract
motivation: one-shot vc,src&tar speaker都可以是训练集unseen的,一句话转换
idea: disentangling speaker and content representations with instance normalization (IN)
证明:模型可以无监督的情况下学到有意义的说话人表征
1. introduction
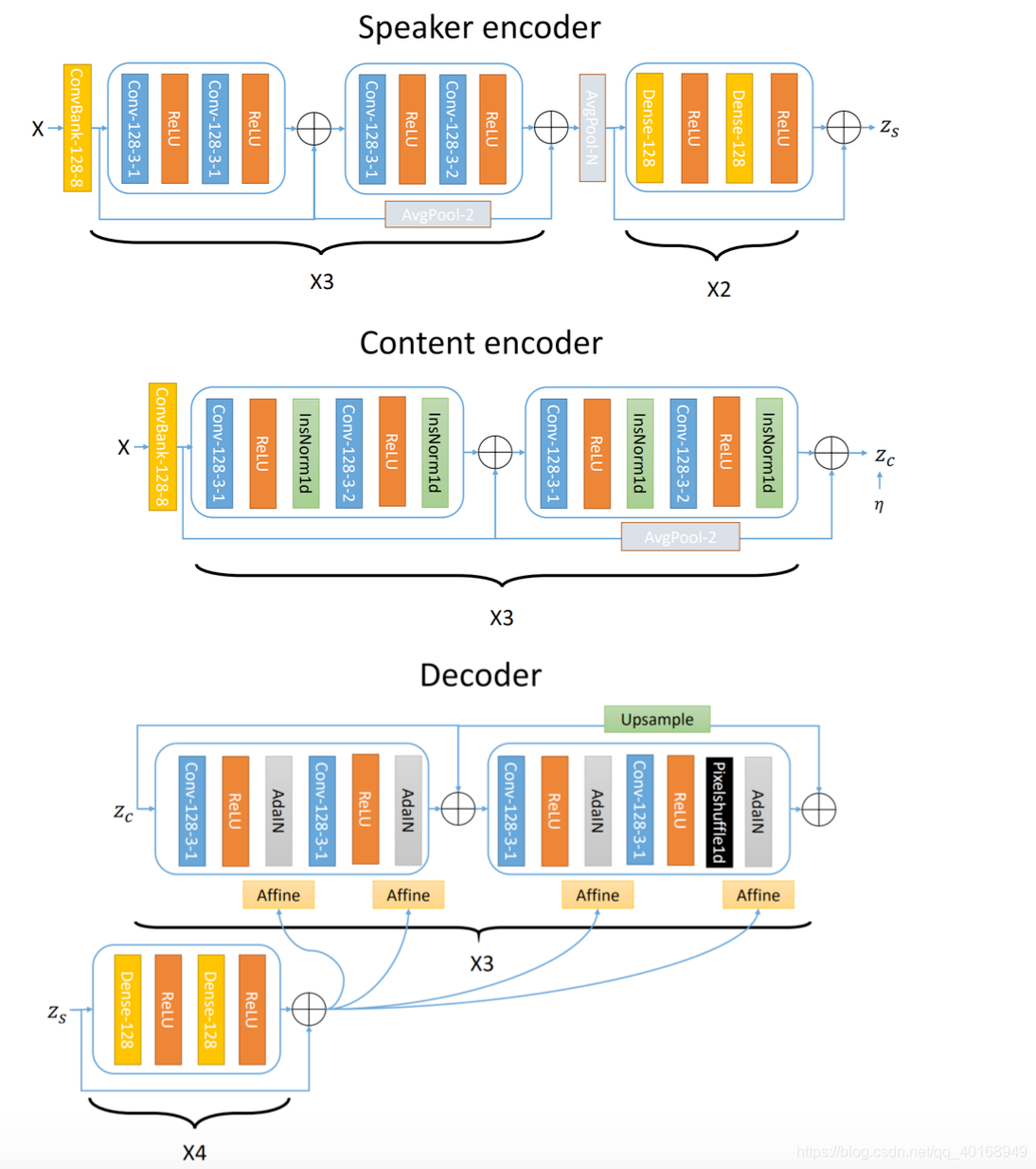
信号包含两部分信息:(1)static—说话人,声道,几乎不随句子变化;(2)文本,事件相关。本文实现:speaker encoder+content encoder(归一化通道信息,使用不带affine transformation的instance normalization,消除说话人信息)+decoder(采用adaptive instance normalization,对应的affine参数由speaker encoder提供,因此说话人信息仅由speaker encoder控制)。训练时候没有提供任何的speaker label,但是speaker encoder学到了有意义的speaker label.
factorized representations
GAN移除了句子中某些属性,但是需要额外的计算量训练判别器。而本文用instance normalization替代对抗训练。
ps. instance normalization是对单张图片做norm, batch normalization是对整体做norm
图像的风格变幻上有用到【28】
2. Proposed Approach
2.1 VAE
loss函数包含两部分,decoder重建损失
和 content encoder的损失
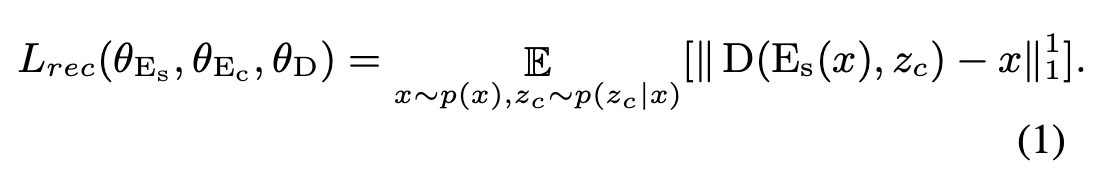
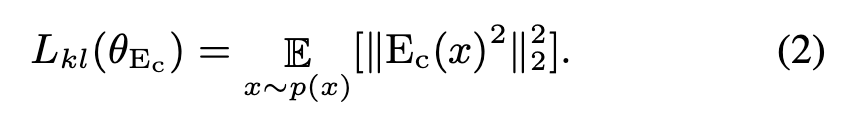
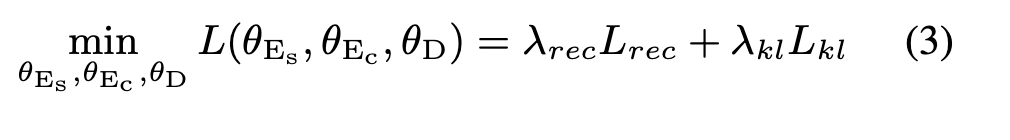
2.2 IN for feature disentanglement
Instance normalization
对content encoder卷积的每个通道求均值方差,然后作用于这个通道
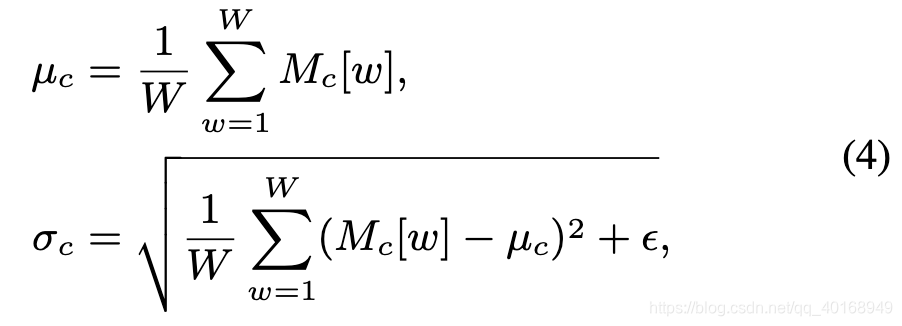
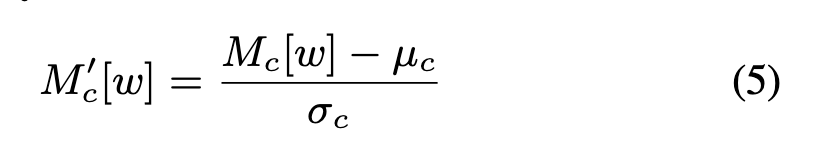
adaIN
对decoder首先做IN,然后由speaker encoder提供参数加adaIN
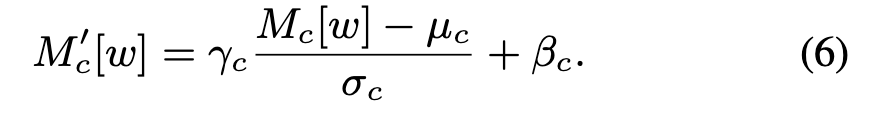
3. Implementation Details
x : 512-d mel-spec
mu, log_sigma = content_encoder(x)
ps. mu = conv1d(enc_o) log_sigma = conv1d(enc_o)因此认为这两者是一个原理实现
eps = log_sigma.new(*log_sigma.size()).normal_(0, 1)
emb = speaker_encoder(x)
dec = decoder [mu + exp(log_sigma/2)*eps, emb]
loss_rec = l1_loss(dec, x)
loss_kl = 0.5 * torch.mean(torch.exp(log_sigma) + mu ** 2 - 1 - log_sigma)
model.loss = 10 * loss_rec + 1* loss_kl
发现content_encoder提取出来的是高维向量,并不是自己最初理解的类似ppgs之类有物理含义的特征,所以这样增加了不可控性。
4. experiment
4.1 数据集
VCTK:80-train, 9-eva, 20-test,128帧以下的移除(50/12.5),train_utt_num=16000,
train的时候设置segment length=128为了卷积操作,inference的时候可以处理任何长度的语音
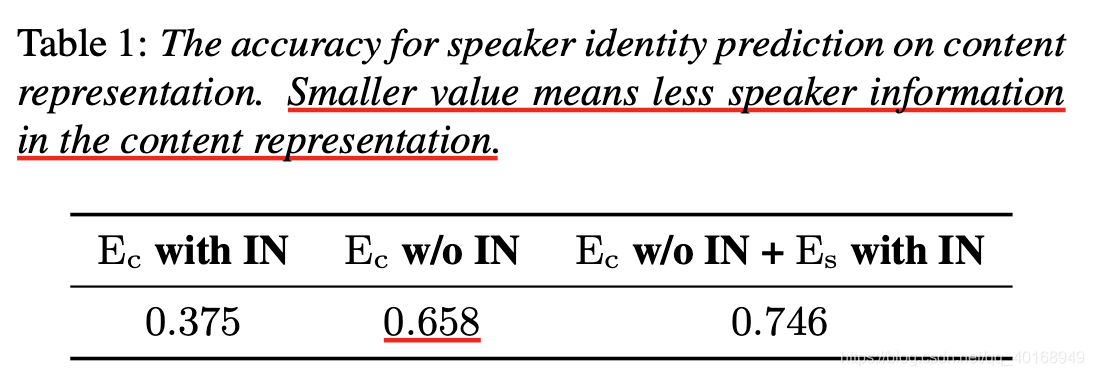
4.2 Evaluation of disentanglement
用ablation test测试content encoder中包含的说话人信息,怎么测试的???
(1)
没有预计的低—speaker encoder对decoder中通道信息的控制,因此模型更倾向通过speaker encoder学习说话人信息。
(2)为了确认这一点,把IN加载speaker encoder上,发现精确加大,说明content encoder中说话人信息更多了。因为speaker encoder中的average pooling+IN阻止s学习说话人,因此更多的说话人信息通过content encoder流过。
4.2. Speaker embedding visualization
将训练过程中seen和unseen speaker的句子分别经过speaker encoder,将输出的结果二维可视化
(1)不同的说话人分的比较开;
(2)seen和unseen都分的开
(3)同样的句子用4.1的content encoder测精度,seen speaker达到0.9973,unseen speaker达到0.9998 。
说明speaker encoder达到预期。
4.3 客观测试
-
global variance for each of the frequency index (ref【35】)用于谱分布的可视化展示,target和converted随机挑100句,结论:转换的语音不匹配target 的句子???
-
Spectrograms example:展示了source和converted基频的对比(heatmap),说明文本信息的保留。
4.4 主观MOS测试
没有baseline model,直接做了和source以及target相似度的直方图展示
