♥,.*,.♥,.*,.♥,.*,.♥,.*♥,.*,.♥,.*,.♥,.*,.♥,.*,.♥,.*,.♥,.*,.♥,.*,.♥♥,.*,.♥,.*,.♥,.*,.♥,.*♥,.*,.♥,.*,.♥,.*,.♥,.*,.♥,.*,.♥,.*,.♥,.*,.♥
Table of Contents
卷积神经网络(Convolutional Neural Networks)
4.全连接层(Fully Connected Feedforward network)
卷积神经网络的反向传播(梯度更新)Back Propagation in Convolutional Neural Networks
1.全连接层的反向传播(Backpropagation for a fully-connected layer)
2.池化层的反向传播(Back Propagation for a Pooling Layer)
3.卷积层的反向传播(Back Propagation for a convolutional layer)
♥,.*,.♥,.*,.♥,.*,.♥,.*♥,.*,.♥,.*,.♥,.*,.♥,.*,.♥,.*,.♥,.*,.♥,.*,.♥♥,.*,.♥,.*,.♥,.*,.♥,.*♥,.*,.♥,.*,.♥,.*,.♥,.*,.♥,.*,.♥,.*,.♥,.*,.♥
卷积神经网络(Convolutional Neural Networks)
卷积神经网络是一种前馈神经网络,其由一个或者多个卷积层和全连接层组成,同时包含关联权重和池化层。
1.卷积神经网络的流程
The whole of CNN

![]() :卷积神经网络一般用于处理图形,其输入是图像的像素值数组。因此输入为矩阵。
:卷积神经网络一般用于处理图形,其输入是图像的像素值数组。因此输入为矩阵。
![]() +
+![]() :之后对矩阵做卷积运算和池化运算。这个过程可以重复很多步。
:之后对矩阵做卷积运算和池化运算。这个过程可以重复很多步。
![]() :卷积或者池化操作后的结果送入全连接层,全连接层将结果输出。
:卷积或者池化操作后的结果送入全连接层,全连接层将结果输出。
具体流程为:

2.卷积层(Convolution)

卷积层的输入(Inputs):上一层输出的矩阵
卷积核(Kernels):用于做卷积运算
卷积层的输出(Outputs):输入层与卷积核做点积运算(dot product)后的结果。
卷积运算的过程
假设输入的矩阵为:

这里的stride=1表示卷积核的移动步伐为1。
这里有两个卷积核Filter1和Filter2:

以Filter 1为例子,则第一步,应该将输入矩阵的红色方框数据与卷积核进行卷积运算:
将对应位置的数值进行点积运算,再相加。
1*1 + 0*(-1) + 0*(-1) //第一行 加粗为输入矩阵,不加粗为卷积矩阵
+ 0*(-1) + 1*1 + 0*(-1) //第二行
+ 0*(-1) + 0*(-1) + 1*1 //第三行
=3

由于stride=1,因此下一步将卷积核向右移动一步,计算方式为:

依次进行计算,则可以得到以下的结果:

3.池化层(Pooling)
池化操作就是进行数据降维,减少采样。
池化操作有两种:最大池化和平均池化。
最大池化就是在范围内取最大值,平均池化就是在范围内取平均值。
以上一步计算得到的结果为例,取 2x2 的模板进行池化操作(最大池化):

因为是 2x2 的模板,因此 4x4 的数组被分为了 4 个 2x2 的区域。之后每个区域取最大值:

对于平均池化来讲,就是取平均值。
为什么池化? Why Pooling?
(1)对数据进行降维度,减少参数,避免过拟合,
(2)用少量的参数来提取图像的特征,加速模型的训练。
4.全连接层(Fully Connected Feedforward network)
以上一层池化层的结果为例,将上一层的结果变为 一维数据。
在全连接层,上一层的每一个神经元节点都与下一层的每个神经元节点连接。

全连接层的操作就是矩阵向量的乘积。
卷积神经网络的反向传播(梯度更新)
Back Propagation in Convolutional Neural Networks
反向传播的目的是通过计算误差调整每一个权值,以训练神经网络。
1.全连接层的反向传播(Backpropagation for a fully-connected layer)
全连接的输出层
其结构为:

其中是第 l 层,第 j 个神经元结点的输入。
是第 l 层,第 j 个神经元结点的输出(激活后的输出,常用的激活函数有Relu、Sigma函数)。
是第 l-1 层的第 k 个结点指向第 l 层的第 j 个结点的权值。
则根据神经元结点的定义,有公式:

式子中的是第 l 层,第 j 个神经元结点的偏置。
就是激活函数。
而我们的目的是根据梯度从而更新。
梯度更新(梯度下降法)的关键式子:![]()
其中的α为学习率,这是编写程序的时候自己设定的一个值。
α右边的即为要计算的梯度(根据链式法则计算):

(第一个式子是以计算为例子,E为计算的偏差,即实际结果与预测结果的平方和求平均(当然计算偏差的形式可以自己定义,常用的平均误差、交叉熵等)。对
来讲,E对
的梯度就等于 E对
的梯度 乘以
对
的梯度 乘以
对
的梯度(看下图的箭头)。第二个式子即是一般的表示形式)

全连接的输出层与隐藏层

以为例子,同样根据链式法则计算E对
的梯度:

一般形式为:

在实际计算中,有一个加快计算的方法。
利用递推的关系式子,存储一部分数据,加快计算。
设:

即定义了一个,表示误差对神经元输入的偏导。
则:
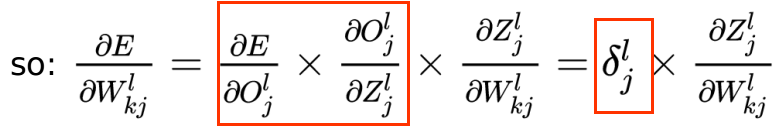
则对于隐藏层,有以下式子:

根据上式的红色方框,则可以看出递推关系。
总结全连接层的反向传播步骤

2.池化层的反向传播(Back Propagation for a Pooling Layer)
在池化操作的时候,有最大池化和平均池化。
以最大池化为例子,在池化操作的时候选取了每个区域的最大值,因此反向传播的时候,只需要将最大值的位置仍旧为最大值,而其他地方为0即可。
最大池化的正向操作为:

最大池化的反向操作为:

对于平均池化,在正向操作时取了区域的平均值,则反向操作时,将值平均分配到每个区域即可(将梯度平均)。
平均池化的正向操作为:

平均池化的反向操作为:

3.卷积层的反向传播(Back Propagation for a convolutional layer)
在卷积层,我们做了如下卷积操作:

根据下面的式子:

以此计算偏差E(下式L即表示E)对权值的偏导数(仍旧使用链式法则):

(在上式子中,计算偏差L对的偏导,正向传播中
参与了
的计算;反向传播中,也应该分别计算L对
的偏导,分别乘以其对
的偏导,然后将四个值加起来作为偏差L对
的偏导)
同理得:

可以用矩阵来表示:


将上述的输入矩阵与Filter做卷积运算,即可以得到:

再进行梯度更新:
![]()
♥,.*,.♥,.*,.♥,.*,.♥,.*♥,.*,.♥,.*,.♥,.*,.♥,.*,.♥,.*,.♥,.*,.♥,.*,.♥♥,.*,.♥,.*,.♥,.*,.♥,.*♥,.*,.♥,.*,.♥,.*,.♥,.*,.♥,.*,.♥,.*,.♥,.*,.♥
广告时间:
本宝宝开通了一个公众号,记录日常的深度学习和强化学习笔记。
希望大家可以共同进步,嘻嘻嘻!求关注,爱你呦!

