1.1 计算机视觉(Computer vision)
- 略
1.2 边缘检测示例(Edge detection example)
-卷积运算是卷积神经网络最基本的组成部分,使用边缘检测作为入门样例。以下图作为示例: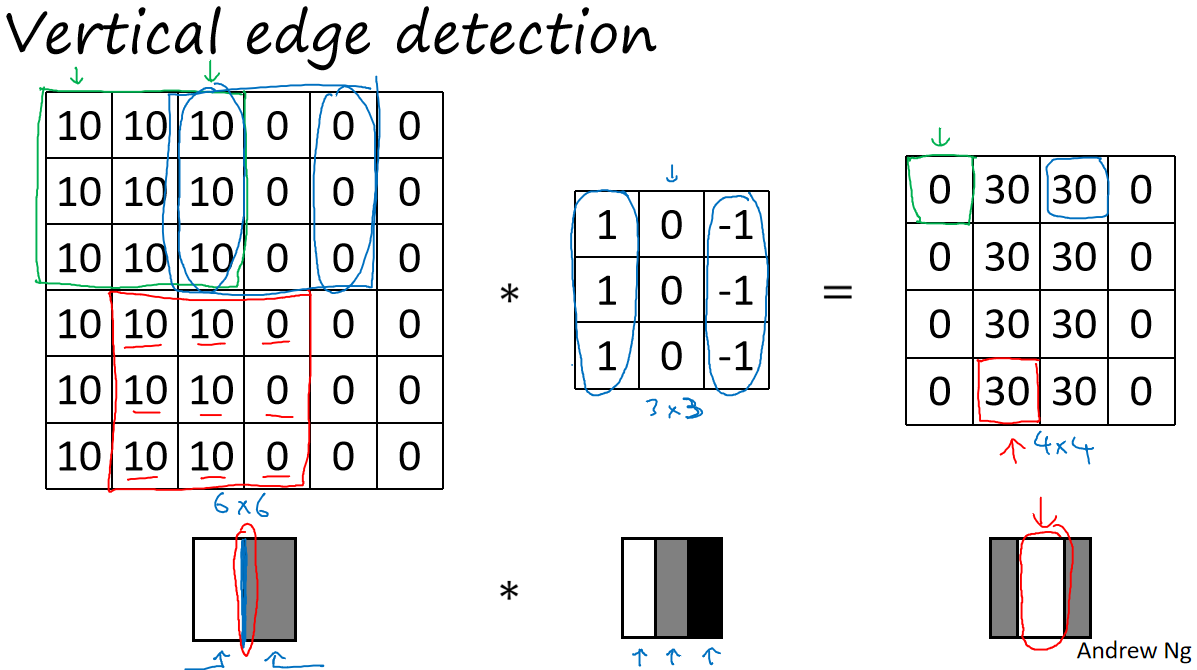
- 在这个例子中,图片太小了。如果你用一个1000×1000的图像,而不是6×6的图片,你会发现其会很好地检测出图像中的垂直边缘。在这个例子中,在输出图像中间的亮处,表示在图像中间有一个特别明显的垂直边缘。从垂直边缘检测中可以得到的启发是,因为我们使用3×3的矩阵(过滤器),所以垂直边缘是一个3×3的区域,左边是明亮的像素,中间的并不需要考虑,右边是深色像素。在这个6×6图像的中间部分,明亮的像素在左边,深色的像素在右边,就被视为一个垂直边缘,卷积运算提供了一个方便的方法来发现图像中的垂直边缘。
1.3 更多边缘检测内容(More edge detection)
-
再来看看更多的边缘检测的例子:

-
总而言之,通过使用不同的过滤器,你可以找出垂直的或是水平的边缘。但事实上,对于这个3×3的过滤器来说,我们使用了其中的一种数字组合。
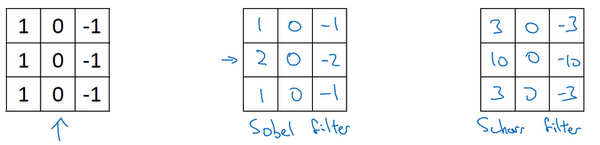
中间的叫做Sobel的过滤器,它的优点在于增加了中间一行元素的权重,这使得结果的鲁棒性会更高一些。但计算机视觉的研究者们也会经常使用其他的数字组合,比如右侧的叫做Scharr过滤器,它有着和之前完全不同的特性,实际上也是一种垂直边缘检测,如果你将其翻转90度,你就能得到对应水平边缘检测。 -
随着深度学习的发展,我们学习的其中一件事就是当你真正想去检测出复杂图像的边缘,你不一定要去使用那些研究者们所选择的这九个数字,但你可以从中获益匪浅。把这矩阵中的9个数字当成9个参数,并且在之后你可以学习使用反向传播算法,其目标就是去理解这9个参数。所以这种将这9个数字当成参数的思想,已经成为计算机视觉中最为有效的思想之一。
1.4 Padding
- Padding有两种方式,一种是valid,这种方式p=0。还有一种是same,如果是这种方式,输入与输出的尺寸是一样大的,我门可以计算出p=(f-1)/2,习惯上,计算机视觉中,f通常是奇数,甚至可能都是这样。

1.5 卷积步长(Strided convolutions)
- 此时有了padding和stride,计算输出尺寸的公式就变成了:如果商不是一个整数怎么办?在这种情况下,我们向下取整。

1.6 三维卷积(Convolutions over volumes)
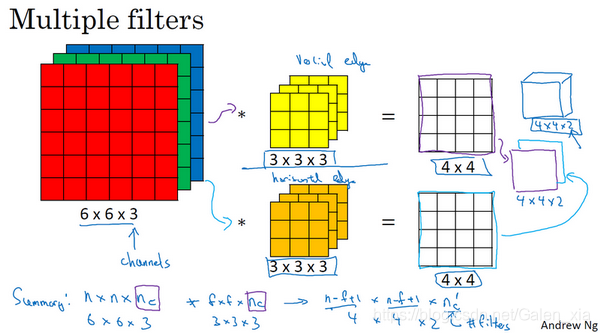
- 以下图说明:
1.7 单层卷积网络(One layer of a convolutional network)
- 看下图:
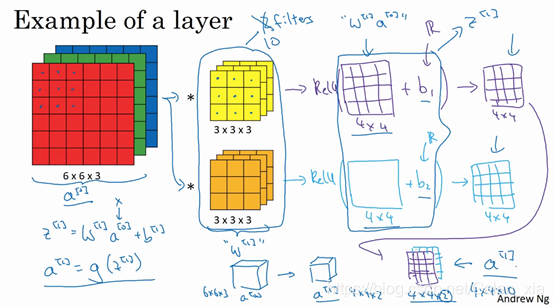
- 为了加深理解,我们来做一个练习。假设你有10个过滤器,而不是2个,神经网络的一层是3×3×3,那么,这一层有多少个参数呢?我们来计算一下,每一层都是一个3×3×3的矩阵,因此每个过滤器有27个参数,也就是27个数。然后加上一个偏差,用参数表示,现在参数增加到28个。上图是2个过滤器,而现在我们有10个,加在一起是28×10,也就是280个参数。请注意一点,不论输入图片有多大,1000×1000也好,5000×5000也好,参数始终都是280个。用这10个过滤器来提取特征,如垂直边缘,水平边缘和其它特征。即使这些图片很大,参数却很少,这就是卷积神经网络的一个特征,叫作“避免过拟合”。你已经知道到如何提取10个特征,可以应用到大图片中,而参数数量固定不变,此例中只有28个,相对较少。
- 输入与输出的关系:

1.8 简单卷积网络示例(A simple convolution network example)
- 示例:

1.9 池化层(Pooling layers)
-
除了卷积层,卷积网络也经常使用池化层来缩减模型的大小,提高计算速度,同时提高所提取特征的鲁棒性。
-
最大池化(max pooling):这是对最大池化功能的直观理解,你可以把这个4×4输入看作是某些特征的集合,也许不是。你可以把这个4×4区域看作是某些特征的集合,也就是神经网络中某一层的非激活值集合。数字大意味着可能探测到了某些特定的特征,左上象限具有的特征可能是一个垂直边缘,一只眼睛,或是大家害怕遇到的CAP特征。显然左上象限中存在这个特征,这个特征可能是一只猫眼探测器。然而,右上象限并不存在这个特征。最大化操作的功能就是只要在任何一个象限内提取到某个特征,它都会保留在最大化的池化输出里。所以最大化运算的实际作用就是,如果在过滤器中提取到某个特征,那么保留其最大值。如果没有提取到这个特征,可能在右上象限中不存在这个特征,那么其中的最大值也还是很小,这就是最大池化的直观理解。
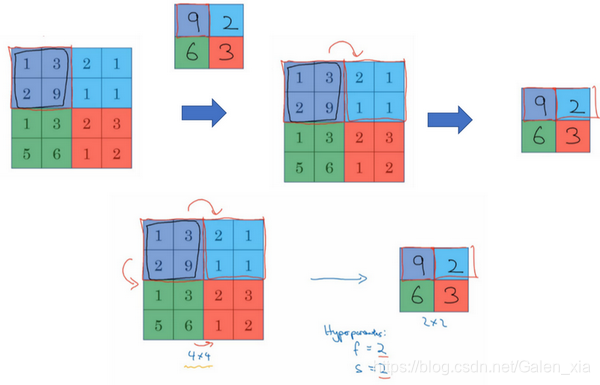
必须承认,人们使用最大池化的主要原因是此方法在很多实验中效果都很好。尽管刚刚描述的直观理解经常被引用,不知大家是否完全理解它的真正原因,不知大家是否理解最大池化效率很高的真正原因。其中一个有意思的特点就是,它有一组超参数,但并没有参数需要学习。实际上,梯度下降没有什么可学的,一旦确定了f和s,它就是一个固定运算,梯度下降无需改变任何值。 -
平均池化(average pooling):

总结一下,池化的超级参数包括过滤器大小和步幅,常用的参数值为,,应用频率非常高,其效果相当于高度和宽度缩减一半。需要注意的一点是,池化过程中没有需要学习的参数。执行反向传播时,反向传播没有参数适用于最大池化。只有这些设置过的超参数,可能是手动设置的,也可能是通过交叉验证设置的。
1.10 卷积神经网络示例(Convolutional neural network example)
- 示例:
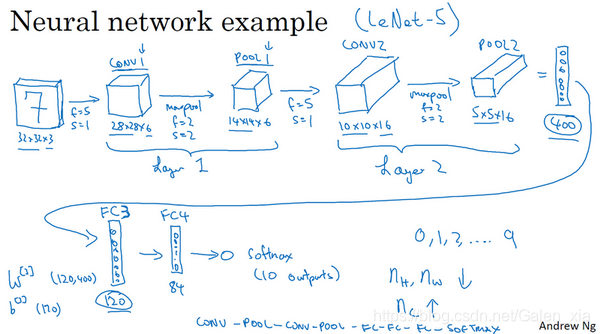
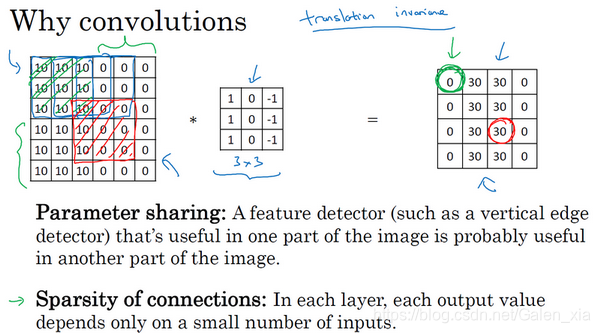
随着神经网络深度的加深,高度nh和nw宽度通常都会减少,而通道数量会增加。
1.11 为什么使用卷积?(Why convolutions?)
- 和只用全连接层相比,卷积层的两个主要优势在于参数共享和稀疏连接,这也是为什么卷积映射参数少的原因,看下图:
神经网络可以通过这两种机制减少参数,以便我们用更小的训练集来训练它,从而预防过度拟合。你们也可能听过,卷积神经网络善于捕捉平移不变。通过观察可以发现,向右移动两个像素,图片中的猫依然清晰可见,因为神经网络的卷积结构使得即使移动几个像素,这张图片依然具有非常相似的特征,应该属于同样的输出标记。实际上,我们用同一个过滤器生成各层中,图片的所有像素值,希望网络通过自动学习变得更加健壮,以便更好地取得所期望的平移不变属性。
