一,Flink介绍
1,Flink概述
分布式的计算引擎
支持批处理,即静态的数据集,历史的数据集
支持流处理,即实时的处理一些实时数据流
支持基于事件的应用
官网:https://flink.apache.org/官网介绍:Stateful Computation over Data Streams,即数据流上的有状态的计算
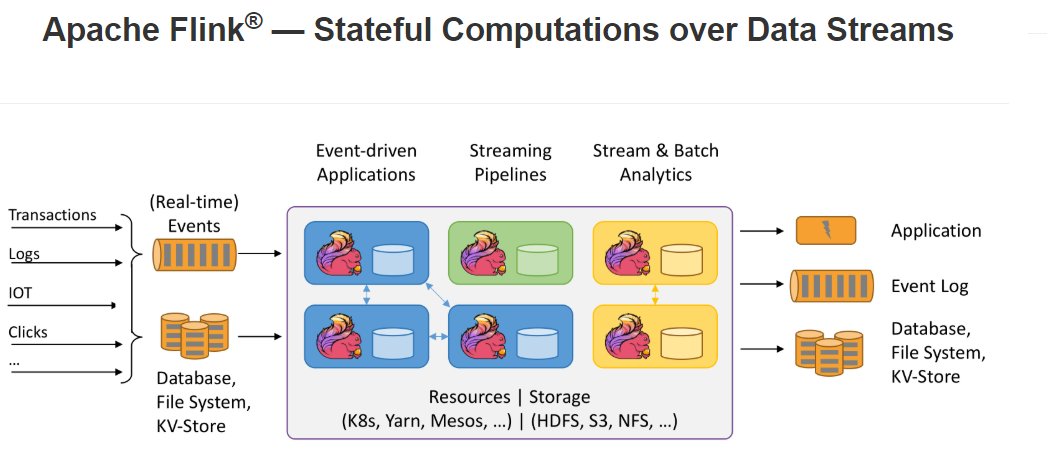
Data Streams ,Flink认为有界数据集是无界数据流的一种特例,所以说有界数据集也是一种数据流,事件流也是一种数据流。 Everything is streams,即Flink可以用来处理任何的数据,可以支持批处理、流处理、AI、MachineLearning等等。
Stateful Computations,即有状态计算。有状态计算是最近几年来越来越被用户需求的一个功能。比如说一个网站一天内访问UV数,那么这个UV数便为状态。Flink提供了内置的对状态的一致性的处理,即如果任务发生了Failover,其状态不会丢失、不会被多算少算,同时提供了非常高的性能。
有界流,有明确的开始和结束的定义,有界流可以等待数据全部注入完整了再开始处理。注入的顺序不是必须的了,引起对于一个静态的数据集,我们是可以对其进行排序的。有界流的处理也可以称为批处理。
无界流,只有开始没有结束,必须连续的处理无界流数据,也即是在事件注入后立即要进行处理,不等待数据全部到达了在去全部处理,因为数据是误的并且永远不会结束数据注入。处理无界流数据往往要求数据事件的注入的时候有一定的顺序。
其它特点:

- 性能优秀(尤其在流计算领域)
- 高可扩展性
- 支持容错
- 纯内存式的计算引擎,做了内存管理方面的大量优化
- 支持eventime的处理
- 支持超大状态的Job(在阿里巴巴中作业的state大小超过TB的是非常常见的)
- 支持exactly-once的处理。
2,SparkStreaming和Flink对比
| SparkStreaming | Flink | |
|---|---|---|
| 定义 | 弹性的分布式数据集,并非真正的实时计算 | 真正的流计算,就像storm 一样; 但flink 同时支持有限的数据流计算(批处理) 和无限数据流计算(流处理) |
| 高容错 | 沉重 | 非常轻量级 |
| 内存管理 | JVM相关操作暴露给用户 | Flink 在JVM 中实现的是自己的内存管理 |
| 程序调优 | 只有SQL 有自动优化机制 | 自动地优化一些场景,比如避免一些昂贵的操作 (如shuffle 和sorts),还有一些中间缓存 |
二,Flink集群的安装
Flink支持多种安装模式
- local(本地)--单继模式
- standalone--独立模式,Flink自带集群,开发测试环境使用
- yarn--计算资源统一由Hadoop Yarn管理,生产测试环境使用‘
1,伪分布式环境部署

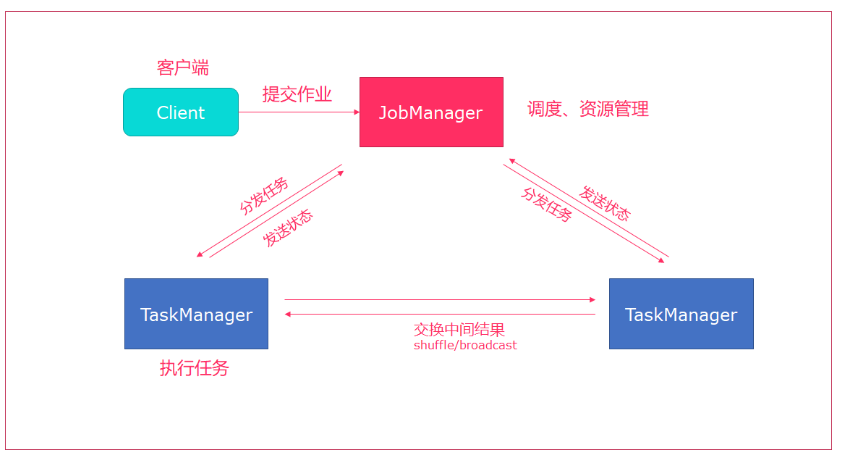
- Flink将job提交给Jobclient
- JobClient将作业提交给JobManager
- JobManager负责资源的分配和作业的执行,资源分配完成后,将任务提交给相应的TaskManager
- TaskManager启动一个线程开始执行,TaskManager会向JobManager报告状态更改(开始,正在,结束)
- 作业结束完成后,将结果返回给JobClient。
web界面:http://node01:8081运行测试任务:
bin/flink run /export/servers/flink-1.7.2/examples/batch/WordCount.jar --input /export/servers/zookeeper-3.4.9/zookeeper.out --output /export/servers/flink_data2,Standalone模式集群部署
修改配置
# jobManager 的IP地址
jobmanager.rpc.address: node01
# JobManager 的端口号
jobmanager.rpc.port: 6123
# JobManager JVM heap 内存大小
jobmanager.heap.size: 1024
# TaskManager JVM heap 内存大小
taskmanager.heap.size: 1024
# 每个 TaskManager 提供的任务 slots 数量大小
taskmanager.numberOfTaskSlots: 2
#是否进行预分配内存,默认不进行预分配,这样在我们不使用flink集群时候不会占用集群资源
taskmanager.memory.preallocate: false
# 程序默认并行计算的个数
parallelism.default: 1
#JobManager的Web界面的端口(默认:8081)
jobmanager.web.port: 8081
#配置每个taskmanager生成的临时文件目录(选配)
taskmanager.tmp.dirs: /export/servers/flink-1.7.2/tmpslot和parallelism总结
taskmanager.numberOfTaskSlots:2
每一个taskmanager分配2个TaskSlot,3个taskManager一共6个TaskSlot
parallelism.default:1
运行程序默认的并行度为1,6个TaskSlot只用了一个,有5个空闲。
使用vi修改slaves文件
node01
node02
node03使用vi修改/etc/profile系统环境变量配置文件,添加HADOOP_CONF_DIR目录
export HADOOP_CONF_DIR=/export/servers/hadoop-2.7.5/etc/hadoop分发/etc/profile到其他两个节点
scp -r /etc/profile node02:/etc
scp -r /etc/profile node03:/etc每个节点重新加载环境变量
source /etc/profile使用scp命令分发flink到其他节点
scp -r /export/servers/flink-1.7.2/ node02:/export/servers/
scp -r /export/servers/flink-1.7.2/ node03:/export/servers/启动Flink集群
./bin/start-cluster.sh启动/停止flink集群
启动:./bin/start-cluster.sh
停止:./bin/stop-cluster.sh
启动/停止jobmanager
如果集群中的jobmanager进程挂了,执行下面命令启动
bin/jobmanager.sh start
bin/jobmanager.sh stop
启动/停止taskmanager
添加新的taskmanager节点或者重启taskmanager节点
- bin/taskmanager.sh start
- bin/taskmanager.sh stop
启动HDFS集群
cd /export/servers/hadoop-2.7.5/sbin
start-all.sh在HDFS中创建/test/input目录
hdfs dfs -mkdir -p /test/input上传wordcount.txt文件到HDFS /test/input目录
hdfs dfs -put /export/servers/flink-1.7.2/README.txt /test/input并运行测试任务
bin/flink run /export/servers/flink-1.7.2/examples/batch/WordCount.jar --input hdfs://node01:8020/test/input/README.txt --output hdfs://node01:8020/test/output2/result.txt浏览Flink Web UI界面
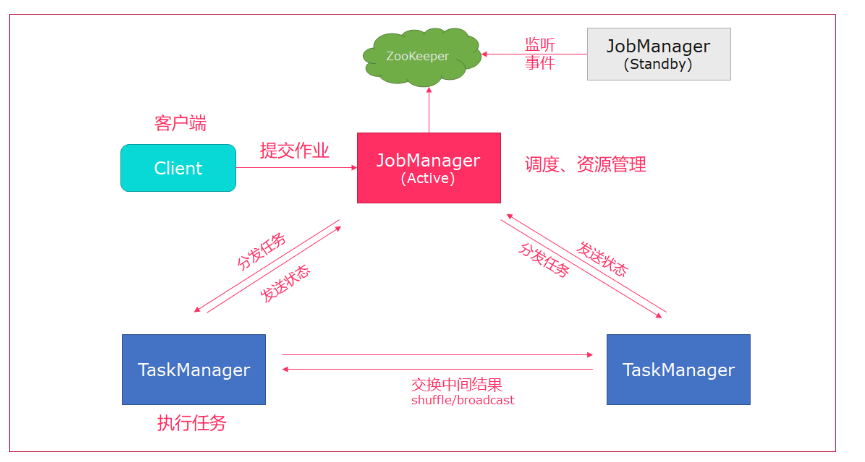
http://node01:80813,Standalone HA模式
4,Yarn集群环境
1,yarn seesion
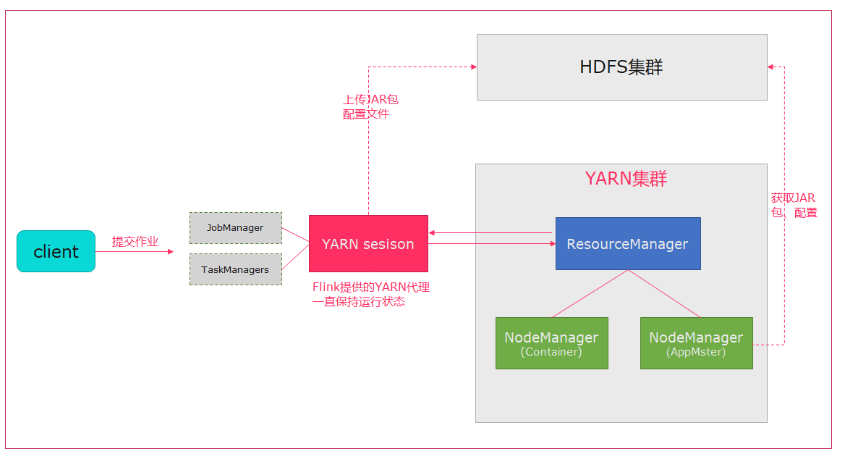
Flink运行在Yarn上,可以使用yarn-session来快速提交作业到Yarn集群。
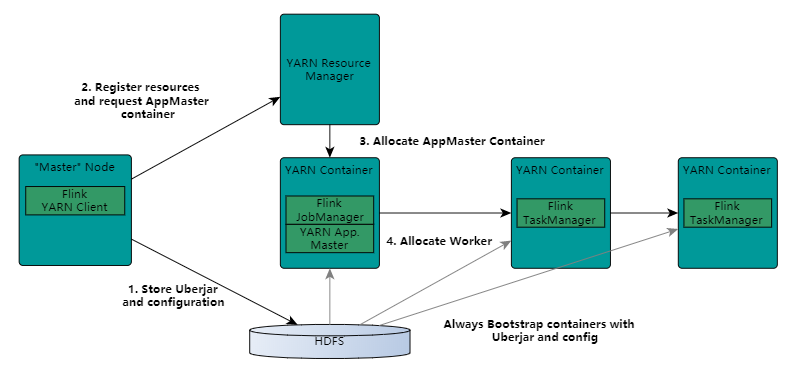
- 当一个新的Flink yarn会话时,客户端会检查所有请求的资源(container和内存)是否可用,如果资源够用,之后上传一个jar包,包含Flink和Hdfs的配置。
- 客户端向RM发送请求,申请Yarn Container启动AppMaster
- RM会在nodemanager分配一个Container,启动Appmaster并启动JobManager
- 初始化完成后,AppMaster构建完成,JobManager和AppMaster在一个Container中,一旦它们启动成功,Appmaster就会知道JobManager的地址,它就会为TaskManager生成一个配置文件(使得TaskManager根据配置文件去连接Jobmanager),配置文件也会上传到hdfs,yarn也提供flink的web接口,yarn分配的端口都是临时的,这就允许用户并行多个Flink。
- AppMaster为TaskManager申请containers,task启动会下载jar包和配置文件,根据配置文件与JobManager进行连接通信。
2,会话模式
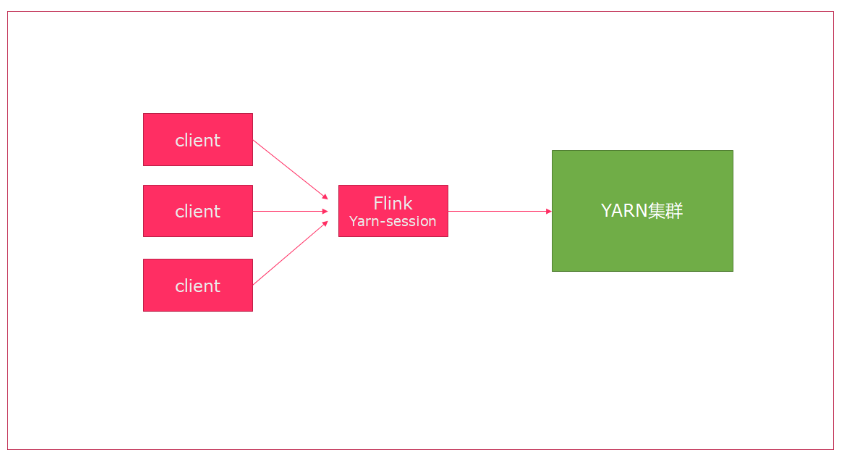
- 使用Flink中的yarn-session(yarn客户端),会启动两个必要服务
JobManager和TaskManager - 客户端通过yarn-session提交作业
- yarn-session会一直启动,不停地接收客户端提交的作业
- 有大量的小作业,适合使用这种方式
在flink目录启动yarn-session
bin/yarn-session.sh -n 2 -tm 800 -s 1 -d
# -n 表示申请2个容器,
# -s 表示每个容器启动多少个slot
# -tm 表示每个TaskManager申请800M内存
# -d 表示以后台程序方式运行可以通过 bin/yarn-session.sh --help 查看yarn-session.sh脚本可以携带的参数:
Required
-n,--container <arg> 分配多少个yarn容器 (=taskmanager的数量)
Optional
-D <arg> 动态属性
-d,--detached 独立运行 (以分离模式运行作业)
-id,--applicationId <arg> YARN集群上的任务id,附着到一个后台运行的yarn session中
-j,--jar <arg> Path to Flink jar file
-jm,--jobManagerMemory <arg> JobManager的内存 [in MB]
-m,--jobmanager <host:port> 指定需要连接的jobmanager(主节点)地址
使用这个参数可以指定一个不同于配置文件中的jobmanager
-n,--container <arg> 分配多少个yarn容器 (=taskmanager的数量)
-nm,--name <arg> 在YARN上为一个自定义的应用设置一个名字
-q,--query 显示yarn中可用的资源 (内存, cpu核数)
-qu,--queue <arg> 指定YARN队列
-s,--slots <arg> 每个TaskManager使用的slots数量
-st,--streaming 在流模式下启动Flink
-tm,--taskManagerMemory <arg> 每个TaskManager的内存 [in MB]
-z,--zookeeperNamespace <arg> 针对HA模式在zookeeper上创建NameSpace观察启动日志

访问yarn的webui, http://node01:8088/
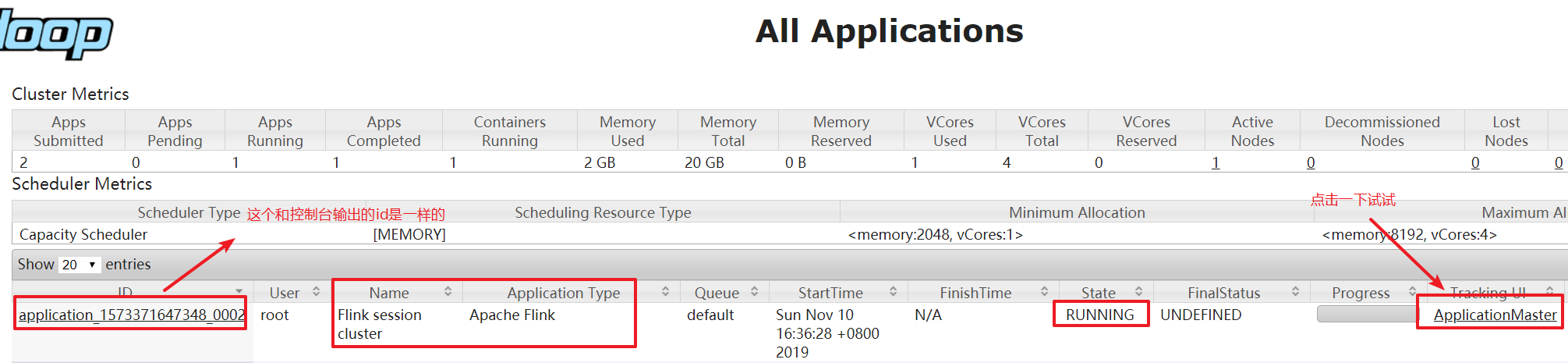
使用flink提交任务
bin/flink run examples/batch/WordCount.jar
- 如果程序运行完了,可以使用yarn application -kill application_id杀掉任务
yarn application -kill application_1573371647348_00023,分离模式
- 直接提交任务给YARN
- 大作业,适合使用这种方式

使用flink直接提交任务
bin/flink run -m yarn-cluster -yn 2 ./examples/batch/WordCount.jar
# -m jobmanager的地址
# -yn 表示TaskManager的个数 查看Yarn的WEB UI, 发现任务结束, Yarn的状态是SUCCESSED

三,Flink架构介绍
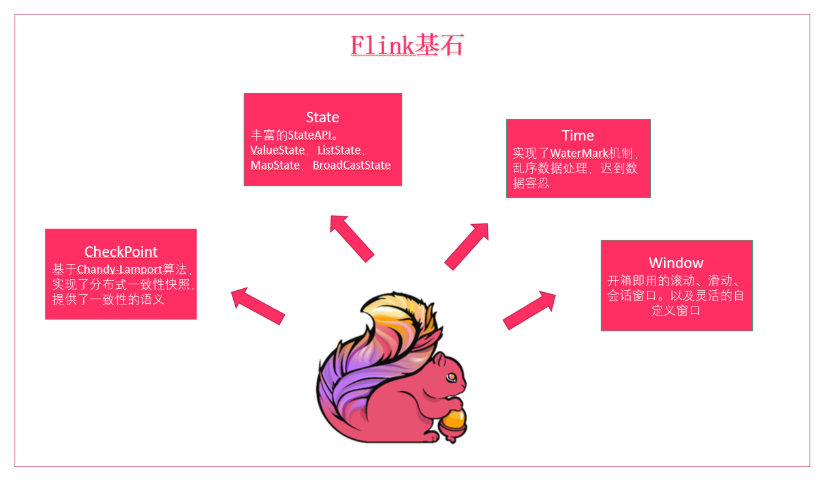
1,Flink基石
Flink的四个基石Checkpoint,State,Time,Window。
2,Flink程序结构
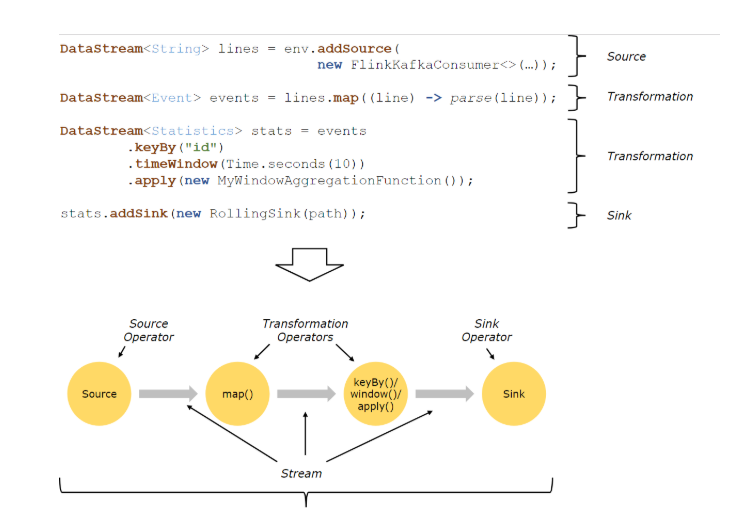
Source:数据源,Flink在流处理和批处理的source大概有四种:本地集合,本地文件的source,socket,自定义的source(自定义的 source 常见的有 Apache kafka、RabbitMQ 等,当然你也可以定义自己的 source。)
Transformation:数据转换的各种操作,有 Map / FlatMap / Filter / KeyBy / Reduce / Fold / Aggregations / Window / WindowAll / Union / Window join / Split / Select等,操作很多,可以将数据转换计算成你想要的数据。
Sink:接收器,Flink将转换计算的数据发送的地点,Flink 常见的 Sink 大概有如下几类:写入文件、打印出来、写入 socket 、自定义的 sink 。自定义的 sink 常见的有 Apache kafka、RabbitMQ、MySQL、ElasticSearch、Apache Cassandra、Hadoop FileSystem 等,同理你也可以定义自己的 sink。
3,Flink并行数据流
Flink程序在执行的时候,会被映射成一个Streaming DataFlow,一个DataFlow是由一组Stream好transformation Operator组成。在启动时从一个或多个Source Operator开始,结束于一个或多个Sink Operator。
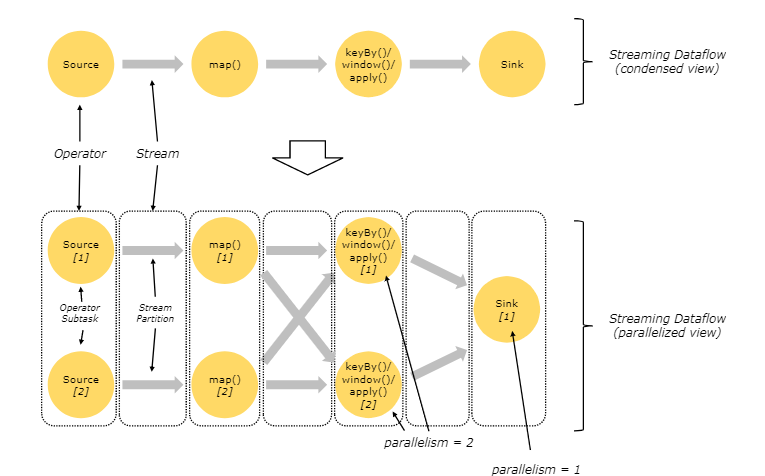
一个stream可以分成多个stream的分区,也就是opera Partition,一个operaor也可以分为多个operator subtask。如上图中,Source被分成Source1和Source2,它们分别为Source的Operator Subtask。每一个Operator Subtask都是在不同的线程当中独立执行的。一个Operator的并行度,就等于Operator Subtask的个数。上图Source的并行度为2。而一个Stream的并行度就等于它生成的Operator的并行度。
数据在两个operator之间传递的时候有两种模式:
One to One模式:两个operator用此模式传递的时候,会保持数据的分区数和数据的排序;如上图中的Source1到Map1,它就保留的Source的分区特性,以及分区元素处理的有序性。
Redistributing (重新分配)模式:这种模式会改变数据的分区数;每个一个operator subtask会根据选择transformation把数据发送到不同的目标subtasks,比如keyBy()会通过hashcode重新分区,broadcast()和rebalance()方法会随机重新分区;
4,Task和Operator chain
Flink的所有操作都称之为Operator,客户端在提交任务的时候会对Operator进行优化操作,能进行合并的Operator会被合并为一个Operator,合并后的Operator称为Operator chain,实际上就是一个执行链,每个执行链会在TaskManager上一个独立的线程中执行。

5,任务调度与执行
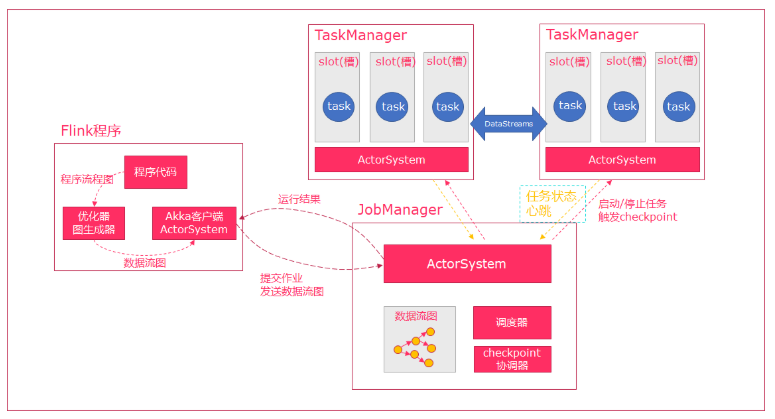
- Flink执行executor会根据代码生成DAG数据流图
- ActorSystem会创建Actor将数据流图发送给JobManager中的Actor
- JobManager会不断接收TaskManager的心跳信息,从中获取到有效额TaskManager
- JobManager通过调度器在TaskManager中调度task(task对应一个线程)
- 在程序运行过程中,task与task之间是可以进行数据传输的。
- Job Client
- 主要职责是
提交任务, 提交后可以结束进程, 也可以等待结果返回 - Job Client
不是Flink 程序执行的内部部分,但它是任务执行的起点。 - Job Client 负责接受用户的程序代码,然后创建数据流,将数据流提交给 Job Manager 以便进一步执行。 执行完成后,Job Client 将结果返回给用户
- 主要职责是
JobManager- 主要职责是调度工作并协调任务做
检查点 - 集群中至少要有一个
master,master 负责调度 task,协调checkpoints 和容错, - 高可用设置的话可以有多个 master,但要保证一个是 leader, 其他是
standby; - Job Manager 包含
Actor System、Scheduler、CheckPoint协调器三个重要的组件 JobManager从客户端接收到任务以后, 首先生成优化过的执行计划, 再调度到TaskManager中执行
- 主要职责是调度工作并协调任务做
TaskManager- 主要职责是从
JobManager处接收任务, 并部署和启动任务, 接收上游的数据并处理 - Task Manager(本身是一个进程)在 JVM 中的一个或多个线程中执行任务的工作节点。
TaskManager在创建之初就设置好了Slot, 每个Slot可以执行一个任务
- 主要职责是从
6,task-slot和slot sharing
1,task-slot
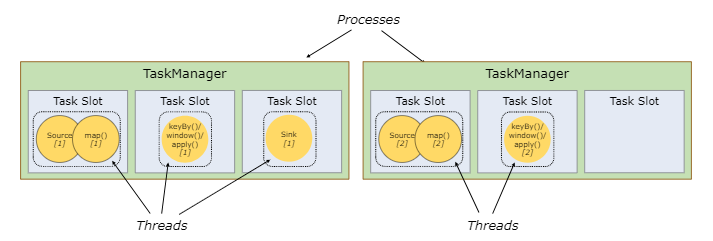
每个TaskManager是一个JVM进程,可以在不同的线程中执行一个或者多个子任务。
每个TaskManager能接收多好个task,由TaskManager中的slot决定(每个TaskManager中至少有一个slot)
Flink将进程的内存划分到多个slot中,这样做可以获得如下好处:
- Task最多能同时并发执行任务的数量是可以控制的。
- solt拥有独立的内存空间,这样一个TaskManager中可以运行多个不同作业,作业之间不受影响。
2,slot sharing
- Flink默认允许同一个Job下的subtask可以共享slot。
- 这样可以让一个slot可以运行整个job的流水线
- 好处是只需要计算job中最高的并行度的task slot,只要满足,其他的job也都满足,还可以提高资源的利用率,让空闲的slot可以执行负载较高的subtask。
- slot的数量最好与cpu核数一样,考虑到超线程可以等于线程*2
四,Flink的应用场景
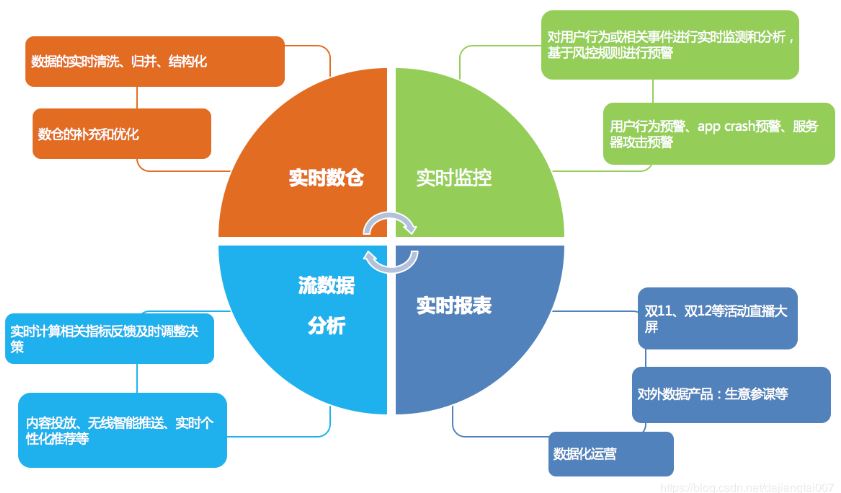
实时监控:
- 用户行为预警,服务器攻击预警(用户银行卡消费行为)
- 对用户行为或者相关事件进行实时监测和分析,基于风控规则进行预警
实时报表:
- 双11、双12等活动直播大屏
- 对外数据产品:生意参谋等
- 数据化运营
流数据分析:
- 实时计算相关指标反馈及时调整决策
- 内容投放、无线智能推送、实时个性化推荐等
实时数仓:
- 数据实时清洗、归并、结构化
- 数仓的补充和优化
场景:
假设你是一个电商公司,经常搞运营活动,但收效甚微,经过细致排查,发现原来是羊毛党在薅平台的羊毛,把补给用户的补贴都薅走了,钱花了不少,效果却没达到。我们应该怎么办呢?
你可以做一个实时的异常检测系统,监控用户的高危行为,及时发现高危行为并采取措施,降低损失。
系统流程:
1.用户的行为经由app上报或web日志记录下来,发送到一个消息队列里去;
2.然后流计算订阅消息队列,过滤出感兴趣的行为,比如:购买、领券、浏览等;
3.流计算把这个行为特征化;
4.流计算通过UDF调用外部一个风险模型,判断这次行为是否有问题(单次行为);
5.流计算里通过CEP功能,跨多条记录分析用户行为(比如用户先做了a,又做了b,又做了3次c),整体识别是否有风险;
6.综合风险模型和CEP的结果,产出预警信息。