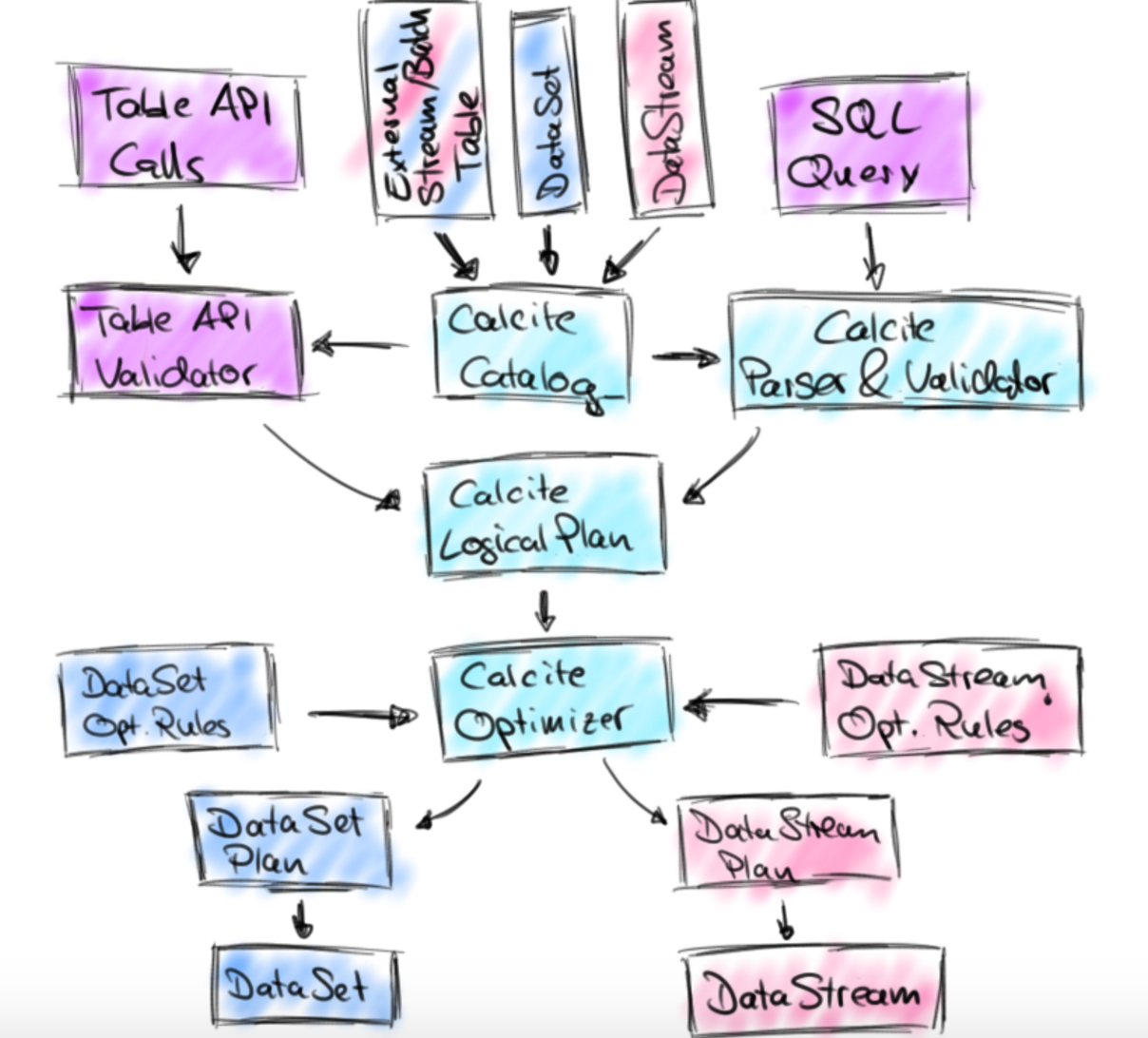
提到目前Table API的问题,batch和stream的API各自能支持的query不一样。
However, the original Table API had a few limitations. First of all, it could not stand alone. Table API queries had to be always embedded into a DataSet or DataStream program. Queries against batch Tables did not support outer joins, sorting, and many scalar functions which are commonly used in SQL queries. Queries against streaming tables only supported filters, union, and projections and no aggregations or joins. Also, the translation process did not leverage query optimization techniques except for the physical optimization that is applied to all DataSet programs.
不想再做成一个众多的sql-on-hadoop实现。
继续使用Calcite。为不同的source(streaming 或 static data),使用不同的rule sets。
window agg和join在stream sql上的表达,依赖于Calcite stream SQL对标准SQL的扩展。https://calcite.apache.org/docs/stream.html
下面是tumbling window的一个例子(Calcite语法),
SELECT STREAM
TUMBLE_END(time, INTERVAL '1' DAY) AS day,
location AS room,
AVG((tempF - 32) * 0.556) AS avgTempC
FROM sensorData
WHERE location LIKE 'room%'
GROUP BY TUMBLE(time, INTERVAL '1' DAY), locationFlink会在Table API里支持成这样
val avgRoomTemp: Table =
tableEnv.ingest("sensorData") // "location", "time", "tempF" 三个字段
.where('location.like("room%"))
.partitionBy('location)
.window(Tumbling every Days(1) on 'time as 'w)
.select('w.end, 'location, , (('tempF - 32) * 0.556).avg as 'avgTempCs)RoadMap
- 1.1.0,query on stream支持selection,filter,and union。Table API重构
- 1.2.0, window agg, maybe also streaming joins
Calcite Streaming
https://calcite.apache.org/docs/stream.html
可定义一个stream,或,一个table,或both。stream 关键字(在select后面)。
stream的查询不会终止,有新的row进来就会输出。
| SQL操作 | 语义(相比regular sql) |
|---|---|
| filter | 支持 |
| project | 支持,推荐在select的时候带上rowtime这列 |
| window | GROUP BY的字段必须monotonic或quasi-monotonic |
| grouping sets | 每个grouping set包含monotonic或quasi-monotonic字段。不支持CUBE, ROLLUP |
| filter after agg | 支持HAVING,跟在GROUP BY后面 |
| subquery | 支持,支持with; HAVING就相当于在agg之后外面套了层query |
| view | 支持 |
| sorting | 支持,SORT BY的字段也需要是monotonic expression |
| join | stream 2 table, stream 2 stream两类 |
| DML |
Window
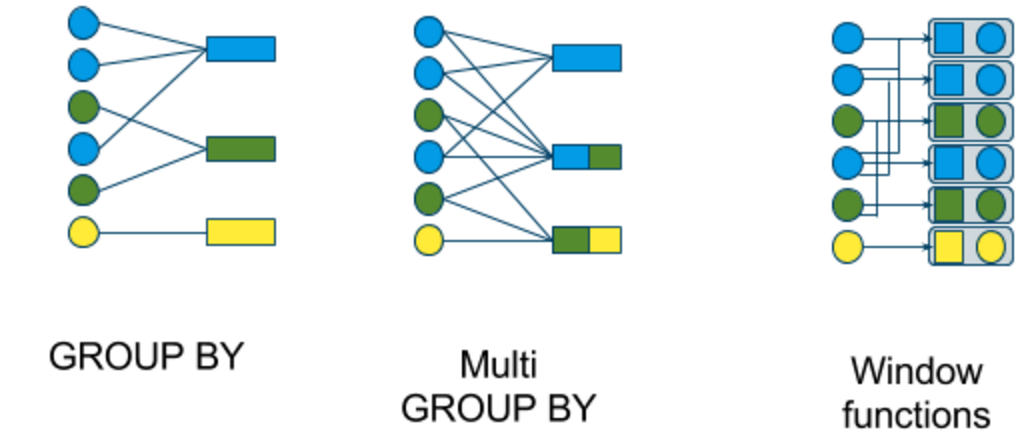
Window种类
tumbling window (GROUP BY)
hopping window (multi GROUP BY)
- sliding window (window functions)
- cascading window (window functions)
如果有 punctuation or watermarks声明一个特定的值(保证单调)不会再出现了,那么那列称为quasi-monotonic
Tumbling Window
CEIL(rowtime TO HOUR)保证rowtime在小时上单调
TUMBLE_END(rowtime, INTERVAL '1' HOUR)是一个更灵活的控制,这样用
SELECT STREAM TUMBLE_END(rowtime, INTERVAL '1' HOUR) AS rowtime,
productId,
COUNT(*) AS c,
SUM(units) AS units
FROM Orders
GROUP BY TUMBLE(rowtime, INTERVAL '1' HOUR), productId;对应还有一个TUMBLE_START
Hopping Window
GROUP BY HOP(rowtime, INTERVAL '1' HOUR, INTERVAL '3' HOUR),定义窗口之间是1小时,而每个窗口涵盖了3小时(闭区间)的数据。
HOP_START这样的fn可以被当做常量使用在agg里
Sliding Window
SELECT STREAM rowtime,
productId,
units,
SUM(units) OVER (ORDER BY rowtime RANGE INTERVAL '1' HOUR PRECEDING) unitsLastHour
FROM Orders;SELECT STREAM *
FROM (
SELECT STREAM rowtime,
productId,
units,
AVG(units) OVER product (RANGE INTERVAL '10' MINUTE PRECEDING) AS m10,
AVG(units) OVER product (RANGE INTERVAL '7' DAY PRECEDING) AS d7
FROM Orders
WINDOW product AS (
ORDER BY rowtime
PARTITION BY productId))
WHERE m10 > d7;Cascading Window
SELECT STREAM rowtime,
productId,
units,
SUM(units) OVER (PARTITION BY FLOOR(rowtime TO HOUR)) AS unitsSinceTopOfHour
FROM Orders;类似sliding window,每条record来会输出一个结果,但是又类似tumbling window,一定范围内可以reset
让Calcite知道某些旧分区不会再之后的window计算里出现了,所以sub-totals就在内部移除了
Subquery/View
STREAM关键字放在subquery或view里不生效。
stream和relation可相互转化。
Join
Joining streams to tables
如果table在变,可以用多version的方式,即为其设置startDate, endDate字段,或使用temporal。
Calcite认为用户可以接受跑两次结果不一样,省去这种复杂度的支持
Joining streams to streams
SELECT STREAM o.rowtime, o.productId, o.orderId, s.rowtime AS shipTime
FROM Orders AS o
JOIN Shipments AS s
ON o.orderId = s.orderId
AND s.rowtime BETWEEN o.rowtime AND o.rowtime + INTERVAL '1' HOUR全文完 :)