一、Fink知识框架
Flink快速上手PDF,入门强烈推荐--链接:https://pan.baidu.com/s/1W8Dgq40qmSmcXb110gAJ7Q 提取码:1234
Flink: 分布式、高性能框架,支持实时模式和批处理模式
一、Apache Flink作为一款高吞吐量、低延迟的针对流数据和批数据的分布式实时处理引擎
和Storm/Spark Streaming一样,定位于流式处理系统
区别:
– Storm:速度快,低延迟,吞吐能力低,无法保证精确一致性,必须独立集群 ,慢慢的就被抛弃了
– Spark Streaming:非实时,慢,吞吐高,依赖yarn资源利用率高 (微批处理 -》 准实时的效果)
并不能算是实时的处理引擎,也是批处理,只不过,每个批次很小,然后处理起来很快。让我们感觉有实时的效果。

– Flink:集成以上两种框架的优点,具备丰富的时间流式窗口概念
就是真正意义上的实时处理,真的会来一条数据,就处理一条数据。
二、 处理无界和有界数据
任何类型的数据都可以形成一种事件流。信用卡交易、传感器测量、机器日志、网站或移动应用程序上的用户交互记录,所有这些数据都形成一种流。
数据可以被作为 无界 或者 有界 流来处理。
- 无界流 有定义流的开始,但没有定义流的结束。它们会无休止地产生数据。无界流的数据必须持续处理,即数据被摄取后需要立刻处理。我们不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。
- 有界流 有定义流的开始,也有定义流的结束。有界流可以在摄取所有数据后再进行计算。有界流所有数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为批处理
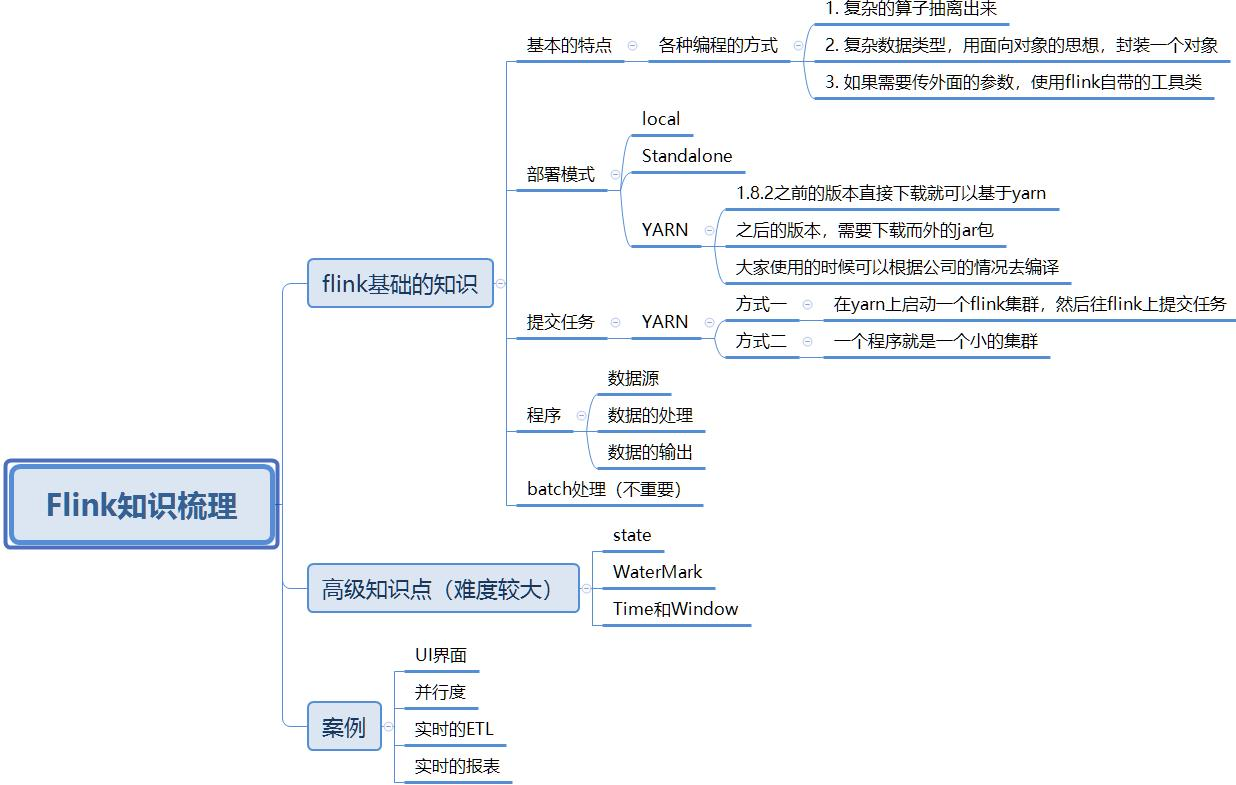
Flink的组件栈有哪些?
根据 Flink 官网描述,Flink 是一个分层架构的系统,每一层所包含的组件都提供了特定的抽象,用来服务于上层组件。
自下而上,每一层分别代表:
1.Deploy 层:该层主要涉及了Flink的部署模式,在上图中我们可以看出,Flink 支持包括local、Standalone、Cluster、Cloud等多种部署模式 。
2.Runtime 层:Runtime层提供了支持 Flink 计算的核心实现,比如:支持分布式 Stream 处理、JobGraph到ExecutionGraph的映射、调度等等,为上层API层提供基础服务 。
3.API层:API 层主要实现了面向流(Stream)处理和批(Batch)处理API,其中面向流处理对应DataStream API,面向批处理对应DataSet API,后续版本,Flink有计划将DataStream和DataSet API进行统一 。
4. Libraries层:该层称为Flink应用框架层,根据API层的划分,在API层之上构建的满足特定应用的实现计算框架,也分别对应于面向流处理和面向批处理两类。面向流处理支持:CEP(复杂事件处理)、基于SQL-like的操作(基于Table的关系操作);面向批处理支持:FlinkML(机器学习库)、Gelly(图处理)。
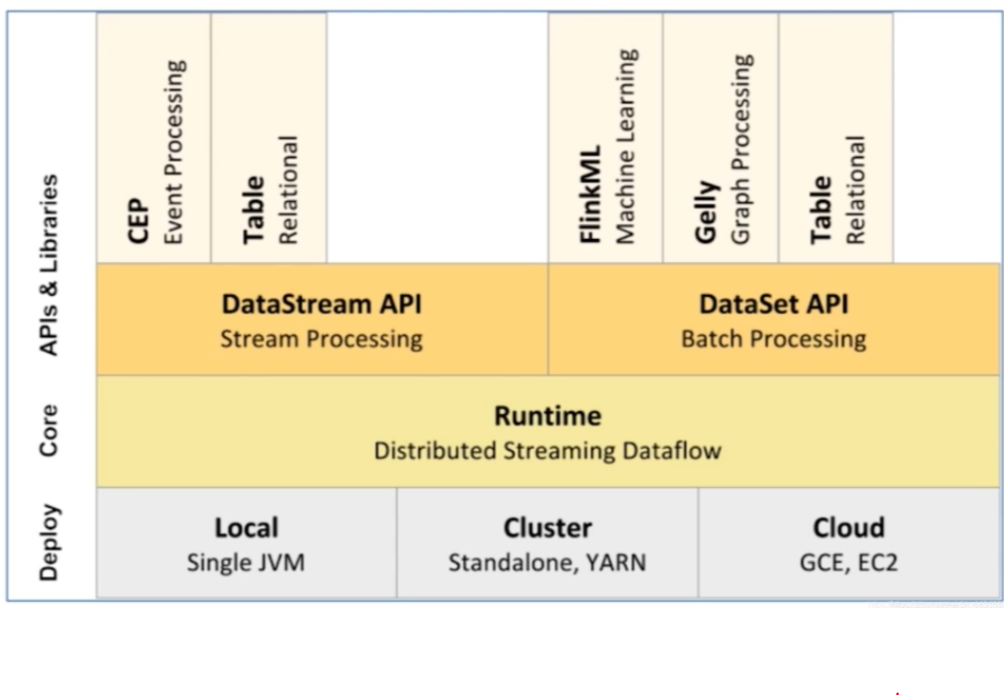
Flink集群有哪些角色?各自有什么作用?
Flink 程序在运行时主要有TaskManager,JobManager,Client三种角色。
- JobManager扮演着集群中的管理者Master的角色,它是整个集群的协调者,负责接收Flink Job,协调检查点,Failover 故障恢复等,同时管理Flink集群中从节点TaskManager。
- TaskManager是实际负责执行计算的Worker,在其上执行Flink Job的一组Task,每个TaskManager负责管理其所在节点上的资源信息,如内存、磁盘、网络,在启动的时候将资源的状态向JobManager汇报。
- Client是Flink程序提交的客户端,当用户提交一个Flink程序时,会首先创建一个Client,该Client首先会对用户提交的Flink程序进行预处理,并提交到Flink集群中处理,所以Client需要从用户提交的Flink程序配置中获取JobManager的地址,并建立到JobManager的连接,将Flink Job提交给JobManager。