一、发展历史
Flink起源于一个名为Stratosphere的研究项目,目的是建立下一代大数据分析平台,于2014年4月16日成为Apache孵化器项目。Stratosphere的最初版本是基于Neffele的研究论文。下面的图表显示了Stratosphere随时间的演化:

二、Flink架构
Flink1.X的架构包括各种组件,比如deploy,core processing和APIs。下图展示了各种组件:

Flink具有分层结构,其中每个组件是特定层的一部分。每层建立在其他的顶部,用于清晰的抽象。Flink被设计为可以在local、yarn以及cloud上运行。Runtime是Flink的核心数据处理引擎,通过以JobGraph形式的APIs接收program,JobGraph是一个简单的并行数据流。
DataStrame和DataSet API是程序员可以用来定义Job的接口。在编译程序时,这些API会生成JobGraph。一但编译后,DataSet API允许优化器生成最佳执行计划。然后根据部署模型将优化的JobGraph提交给执行者。您可以选择本地、远程或yarn部署模式。如果你有一个Hadoop集群已经运行,可以使用yarn的部署模式。
三、Flink分布式执行过程
Flink分布式执行包括两个重要的进程,即master和worker。当一个flink程序执行时,会有许多的进程参与执行,分别为Job Manager、Task Manager和Job Client。下图展示了Flink程序的执行过程:

Flink的程序需要提交到Job Client。Job Client然后提交作业到Job Manager,Job Manager负责资源分配和作业执行。Job Manager首先做的事情是分配需要的资源,一旦资源分配完成,task会被提交到各自的Task Manager。在接收的task上,Task Manager会初始化一个线程用来启动执行(Execution),当execution准备就绪,Task Manager会持续向Job Manager报告状态改变(比如启动execution,运行execution,执行结束),一旦作业执行结束,执行的结果会被发送到Client。
JobManager
master节点的进程,称之为JobManager,协调和管理程序的execution,主要的作用包括:调度task,管理checkpoint,失败恢复等等。Job Manager包括以下三个非常重要的组件:
(1)Actor system:一个容器,提供调度,配置,登录等服务
(2)Scheduler:在Flink中Executors被称之为task slots,每个Task Manager需要管理一个或多个task slot。在内部,Flink决定哪些task需要共享slot,哪些task需要被分配到相应的slot中,主要是由SlotSharingGroup 和 CoLocationGroup实现这种操作
(3)Check pointing:容错机制
Task Manager
Task Manager是worker节点,用来在JVM中执行一个或多个线程,task执行的并行度取决于每个TaskMamager的可用的task slot(槽)的数量,在同一个slot的线程共享同一个JVM,在同一个JVM中的他上课共享TPC连接和心跳信息。

Job Client
Job Client不是Flink程序执行的内部组成部分,而是执行的开始。Job Client负责接收应用程序,然后创建数据流,最后提交数据流到Job Manager。一旦执行完成,Job Client会将结果返回给用户。
一个数据流是一个执行计划,以下面的wordcount为例:

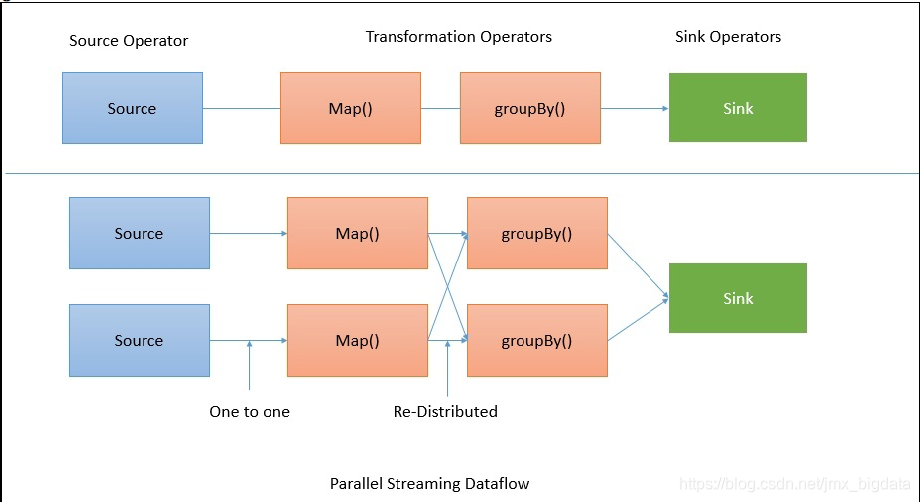
当client接收到程序后,会将其转换为数据流,上述代码的数据流如下图所示:

数据流直接从源到map操作不需要shuffle数据,但是对于GroupBy操作,Flink需要根据key重新分布数据。如下图: