QQ交流群:64655993
转发自:https://blog.csdn.net/lmalds/article/details/53736836
本文主要翻译自官方文档中Configuration的部分:Flink1.1.3 configuration。
Common Options
env.java.home : java安装路径,如果没有指定则默认使用系统的$JAVA_HOME环境变量。建议设置此值,因为之前我曾经在standalone模式中启动flink集群,报找不到JAVA_HOME的错误。config.sh中(Please specify JAVA_HOME. Either in Flink config ./conf/flink-conf.yaml or as system-wide JAVA_HOME.)
env.java.opts : 定制JVM选项,在Flink启动脚本中执行。需要单独执行JobManager和TaskManager的选项。
env.java.opts.jobmanager : 执行jobManager的JVM选项。在Yarn Client环境下此参数无效。
env.java.opts.taskmanager : 执行taskManager的JVM选项。在Yarn Client环境下此参数无效。
jobmanager.rpc.address : Jobmanager的IP地址,即master地址。默认是localhost,此参数在HA环境下或者Yarn下无效,仅在local和无HA的standalone集群中有效。
jobmanager.rpc.port : JobMamanger的端口,默认是6123。
jobmanager.heap.mb : JobManager的堆大小(单位是MB)。当长时间运行operator非常多的程序时,需要增加此值。具体设置多少只能通过测试不断调整。
taskmanager.heap.mb : 每一个TaskManager的堆大小(单位是MB),由于每个taskmanager要运行operator的各种函数(Map、Reduce、CoGroup等,包含sorting、hashing、caching),因此这个值应该尽可能的大。如果集群仅仅跑Flink的程序,建议此值等于机器的内存大小减去1、2G,剩余的1、2GB用于操作系统。如果是Yarn模式,这个值通过指定tm参数来分配给container,同样要减去操作系统可以容忍的大小(1、2GB)。
taskmanager.numberOfTaskSlots : 每个TaskManager的并行度。一个slot对应一个core,默认值是1.一个并行度对应一个线程。总的内存大小要且分给不同的线程使用。
parallelism.default : 每个operator的默认并行度。默认是1.如果程序中对operator设置了setParallelism,或者提交程序时指定了-p参数,则会覆盖此参数。如果只有一个Job运行时,此值可以设置为taskManager的数量 * 每个taskManager的slots数量。即NumTaskManagers * NumSlotsPerTaskManager 。
fs.default-scheme : 设置默认的文件系统模式。默认值是file:///即本地文件系统根目录。如果指定了hdfs://localhost:9000/,则程序中指定的文件/user/USERNAME/in.txt,即指向了hdfs://localhost:9000/user/USERNAME/in.txt。这个值仅仅当没有其他schema被指定时生效。一般hadoop中core-site.xml中都会配置fs.default.name。
fs.hdfs.hadoopconf : HDFS的配置路径。例如:/home/flink/hadoop/hadoop-2.6.0/etc/hadoop。如果配置了这个值,用户程序中就可以简写hdfs路径如:hdfs:///path/to/files。而不用写成:hdfs://address:port/path/to/files这种格式。配置此参数后,Flink就可以找到此路径下的core-site.xml和hdfs-site.xml了。建议配置此参数。
Advanced Options
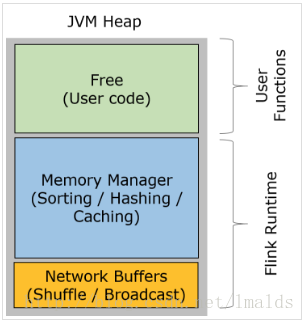
Managed Memory
对于批处理程序,Flink使用了自我的内存管理,默认使用70%的taskmanager.heap.mb的内存。这样Flink批处理程序不会出现OOM问题,因为Flink自己知道有多少内存可以使用,当内存不够时,就使用磁盘空间。而且这样有些operation可以直接访问数据,
而不需要序列化数据到java对象。Flink自我管理的内存可以加速程序的执行。如果需要的话,自我管理的内存也可以在JVM堆外被分配,这也有助于提升性能。
taskmanager.memory.size :相对于jobmanager.heap.mb,使用多少内存用于内存管理器进行内存的自我管理。如果没有指定,则默认值是-1,代表参考参数taskmanager.memory.fraction。设置了自我内存管理,Flink在批处理中就可以在堆内或堆外进行排序、hash、cache等操作。
taskmanager.memory.fraction : 当taskmanager.memory.size没有设置时(或-1),此参数才生效。意思是使用taskmanager.heap.mb的百分比用于自我内存管理。默认值是0.7,代表使用70%的taskmanager的内存。剩余的30%用于UDF的堆以及用于taskmanager间通信数据的内存。
taskmanager.memory.off-heap : 默认是false。如果设置为true,则taskmanager在JVM堆外分配内存。这对于大段内存的使用很有效。
taskmanager.memory.segment-size : 内存段的大小,默认单位是32KB。
taskmanager.memory.preallocate: : 默认是false。指定Flink当启动时,是否一次性分配所有管理的内存。
如果taskmanager.memory.off-heap设置true,则建议此值也设置为true。
Memory and Performance Debugging
当遇到OOM等内存问题时,可以设置这些debbug参数。
taskmanager.debug.memory.startLogThread :设置为true可以记录堆或堆外或内存池的使用信息以及垃圾回收信息。
taskmanager.debug.memory.logIntervalMs : 当上边的值设置为ture时,此参数有效。代表多久收集一次内存统计信息(单位是毫秒)。
Kerberos
忽略。
Other
taskmanager.tmp.dirs: taskmanager的临时目录,默认是系统的tmp路径。可以指定多个路径,通过:隔开,多路径的设置导致多个线程去执行IO操作。
taskmanager.log.path:taskmanager的日志文件路径,默认在$FLINK_HOME/log
jobmanager.web.address: Jobmanager的web接口地址,默认是anyLocalAddress(),即所有地址的请求都会被处理,指向jobmanager的IP地址
jobmanager.web.port: Jobmanager的web接口,默认是8081
jobmanager.web.tmpdir: 存放web接口静态文件的路径,上传的jar文件也会存储在此路径(这里指通过webUI启动job时上传的jar文件)。默认是系统tmp路径。
jobmanager.web.upload.dir: 通过web UI上传的jar文件的路径,如果没有指定,则指向jobmanager.web.tmpdir的路径。
fs.overwrite-files: 当输出文件到文件系统时,是否覆盖已经存在的文件。默认是false
fs.output.always-create-directory: 文件输出时是否单独创建一个子目录。默认是false,即直接将文件输出到指向的目录下
taskmanager.network.numberOfBuffers: taskmanager数据在网络传输的大小,默认是2048个块,每个块大小是32KB。这个值官方建议的值为:#slots-per-TM^2 * #TMs * 4。我之前按照这个建议配置时,系统出错说这个值太小。个人建议这个值可以稍微设置大些。
state.backend: 当检查点被激活时,保存的有状态的检查点的目录。默认是存在jobmanager的内存中。也支持保存到hdfs或者rocksdb中。默认是jobmanager,如果是hdfs,则制定filesystem。例如hdfs://namenode-host:port/flink-checkpoints;如果是RocksDB,则制定RocksDB的路径。
state.backend.fs.checkpointdir: 存储检查点的具体路径,必须是Flink可访问的路径。例如:hdfs://namenode-host:port/flink-checkpoints。
state.backend.rocksdb.checkpointdir: 存储RocksDB的检查点路径,默认是taskmanager.tmp.dirs
state.checkpoints.dir: checkpoint数据的目录。
recovery.zookeeper.storageDir: 定义Jobmanager的的元数据信息,zookeeper只是保存一个指向此目录的指针,在HA环境下用于Jobmanager的恢复。例如设置为: hdfs:///flink/recovery。
blob.storage.directory: 指定taskmanager中Blob文件(jar)的路径。
blob.server.port: taskmanager中blob服务器的端口号,默认是0,即操作系统选定一个可用的端口。可以指定一个范围 (“50100-50200”),避免相同机器中运行多个Jobmanager的情况时使用。
restart-strategy: 默认是"none",即不设置任何重启策略。如果设置为"fixed-delay",则代表固定延迟策略;如果指定"failure-rate",则代表失败的时间比例。
restart-strategy.fixed-delay.attempts: fixed-delay模式下的恢复尝试次数,默认是1次。
restart-strategy.fixed-delay.delay: fixed-delay模式下,两次重启尝试之间的延迟时间。默认为akka.ask.timeout.
restart-strategy.failure-rate.max-failures-per-interval: failure-rate模式下,失败重启的最大次数,默认是1次。
restart-strategy.failure-rate.failure-rate-interval: failure-rate下,失败时间间隔的度量。
restart-strategy.failure-rate.delay: failure-rate模式下,两次重启之间的延迟时间,默认是akka.ask.timeout.
Full Reference
HDFS
Flink使用的HDFS相关的配置。
fs.hdfs.hadoopconf: hadoop的配置路径。Flink将在此路径下寻找core-site.xml和hdfs-site.xml中的配置信息,此值默认是null。如果需要用到HDFS,则必须设置此值,例如$HADOOP_HOME/etc/hadoop。
fs.hdfs.hdfsdefault: hdfs-default.xml的路径。默认是null。如果设置了第一个值,则此值不用设置。
fs.hdfs.hdfssite: hdfs-site.xml的路径。默认是null。如果设置了第一个值,则此值不用设置。
JobManager & TaskManager
jobmanager.rpc.address : Jobmanager的IP地址,即master地址。默认是localhost,此参数在HA环境下或者Yarn下无效,仅在local和无HA的standalone集群中有效。
jobmanager.rpc.port : JobMamanger的端口,默认是6123。
taskmanager.hostname: taskmanager绑定的网络接口的主机名。通常这个值在非共享模式下使用,每个taskmanager的配置不一样,因此一般都单独指定文件来设置。这个参数一般不设置。
taskmanager.rpc.port: taskmanager的通信接口,默认是0。一般不指定,即由操作系统自己决定一个可用的端口。
taskmanager.data.port: taskmanager的数据接口,默认是0。一般不指定,即由操作系统自己决定一个可用的端口。
jobmanager.heap.mb : JobManager的堆大小(单位是MB)。默认256MB。当长时间运行operator非常多的程序时,需要增加此值。具体设置多少只能通过测试不断调整。
taskmanager.heap.mb : 每一个TaskManager的堆大小(单位是MB),默认512MB。由于每个taskmanager要运行operator的各种函数(Map、Reduce、CoGroup等,包含sorting、hashing、caching),因此这个值应该尽可能的大。如果集群仅仅跑Flink的程序,建议此值等于机器的内存大小减去1、2G,剩余的1、2GB用于操作系统。如果是Yarn模式,这个值通过指定tm参数来分配给container,同样要减去操作系统可以容忍的大小(1、2GB)。
taskmanager.numberOfTaskSlots : 每个TaskManager的并行度。一个slot对应一个core,默认值是1.一个并行度对应一个线程。总的内存大小要且分给不同的线程使用。
taskmanager.tmp.dirs: taskmanager的临时目录,默认是系统的tmp路径。可以指定多个路径,通过“:”隔开,多路径的设置导致多个线程去执行IO操作。
taskmanager.network.numberOfBuffers: taskmanager数据在网络传输的大小,默认是2048个块,每个块大小是32KB。这个值官方建议的值为:#slots-per-TM^2 * #TMs * 4。我之前按照这个建议配置时,系统出错说这个值太小。个人建议这个值可以稍微设置大些。见下图。
taskmanager.memory.size :相对于jobmanager.heap.mb,使用多少内存用于内存管理器进行内存的自我管理。如果没有指定,则默认值是-1,代表参考参数taskmanager.memory.fraction。设置了自我内存管理,Flink在批处理中就可以在堆内或堆外进行排序、hash、cache等操作。默认是-1. 注意,目前自我管理的内存机制仅仅适用于Flink的bactch操作,如果是流计算,则可以忽略此值。
taskmanager.memory.fraction : 当taskmanager.memory.size没有设置时(或-1),此参数才生效。意思是使用taskmanager.heap.mb的百分比用于自我内存管理。默认值是0.7,代表使用70%的taskmanager的内存。剩余的30%用于UDF的堆以及用于taskmanager间通信数据的内存。如果是流计算,则可以忽略此值。
taskmanager.debug.memory.startLogThread: taskmanager周期性的记录堆内、堆外的内存使用以及垃圾回收的统计信息,一般用于debug模式。
taskmanager.debug.memory.logIntervalMs: taskmanager收集统计信息的时间间隔,单位毫秒。
blob.fetch.retries: taskmanager从jobmanager下载BLOB类型的文件(jar文件)的重试次数,默认是50次。
blob.fetch.num-concurrent: jobmanager提供的并发下载BLOB类型的文件的数量,默认50.
blob.fetch.backlog: jobmanager提供用于下载的BLOB对象的最大队列数,默认1000.
task.cancellation-interval: 2个task取消的时间间隔,默认30000毫秒。
taskmanager.exit-on-fatal-akka-error:taskmanager通信失败时是否被终止。默认是false。
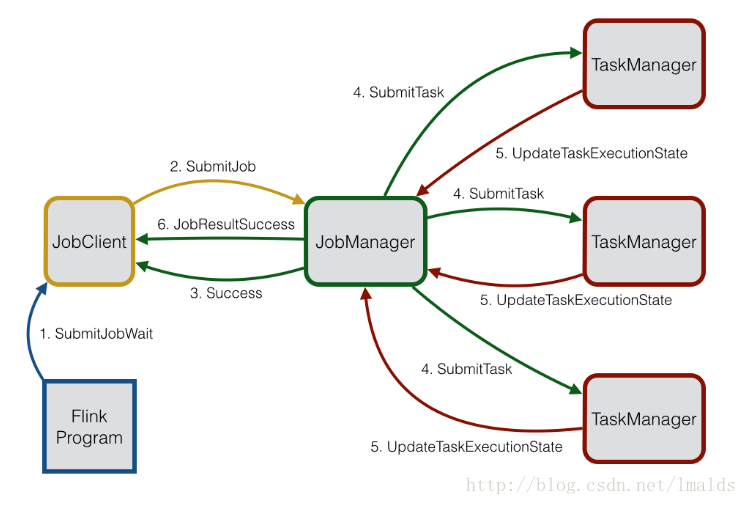
Distributed Coordination (via Akka)
这块略掉,可参考:Akka and Actors
JobManager Web Frontend
jobmanager.web.port: Jobmanager的web访问断口,默认是8081。当设置为-1时禁用webUI。
jobmanager.web.history: 在webUI中显示最近5个完成的Job的历史信息。默认值是5个。
jobmanager.web.checkpoints.disable: webUI中禁止收集检查点相关的统计信息。默认false,即收集。
jobmanager.web.checkpoints.history: webUI中保存的检查点条数,默认10条。
jobmanager.web.backpressure.cleanup-interval: webUI中放没有访问背压界面(信息)时,系统缓存的时间长度,默认600000毫秒,即10分钟。
jobmanager.web.backpressure.refresh-interval: webUI中背压的统计信息刷新的频率,默认是6000毫秒,即1分钟。
jobmanager.web.backpressure.num-samples: webUI中背压收集的样本数量,默认是100个。
jobmanager.web.backpressure.delay-between-samples: webUI中背压采样的延迟
File Systems
fs.default-scheme: 设置默认的文件系统模式。默认值是file:///即本地文件系统根目录。如果指定了hdfs://localhost:9000/,则程序中指定的文件/user/USERNAME/in.txt,即指向了hdfs://localhost:9000/user/USERNAME/in.txt。这个值仅仅当没有其他schema被指定时生效。一般hadoop中core-site.xml中都会配置fs.default.name。
fs.overwrite-files: 当输出文件到文件系统时,是否覆盖已经存在的文件。默认是false。
fs.output.always-create-directory: 文件输出时是否单独创建一个子目录。默认是false,即直接将文件输出到指向的目录下。Compiler/Optimizer
Runtime Algorithms
此部分忽略。
Resource Manager
resourcemanager.rpc.port: 配置与资源管理器的通信端口,默认是Jobmanager的端口。此参数不能定义端口范围。YARN
yarn.heap-cutoff-ratio: 从yarn container中移除的内存百分比(默认0.25)。例如,当用户请求为taskmanager container分配4GB的内存时, 我们不能直接从JVM中划分4GB的内存给container。 因为当请求的内存不能达到要求时,yarn会立刻终止taskmanager container。因此为了安全起见,我们可以从用户的请求中去掉15%的内存。
yarn.heap-cutoff-min: 请求的内存中,最少去掉的内存,默认384MB。
yarn.maximum-failed-containers: 最大的失败的containers的数量,默认是-n指定的container的数量。当达到此值时,如果失败,则重新分配container。
yarn.application-attempts: 默认值为1. 重启AppicationMaster的个数。 注意当Flink集群重启时,client会丢失连接。 因此Jobmanager的地址会改变,因此需要手动设置iobmanager的host:port对儿。建议此值设为默认值1.
yarn.heartbeat-delay: 与resourceManager的心跳时间间隔,默认5秒一次。
yarn.properties-file.location: 默认tmp路径。当Flink job提交给yarn后,jobmanager的host信息以及可用的slot个数将写到此路径下,以便client可以获得这些信息。
yarn.containers.vcores: 每个yarn container的vcore的数量,默认等于taskmanager的slot数量。
yarn.application-master.env.ENV_VAR1=value: 以 yarn.application-master.env.为前缀的参数,将会作为环境变量传递给AM/Jobmanager进程。例如传递 LD_LIBRARY_PATH传递给ApplicationMaster, 可以这样设置:
yarn.application-master.env.LD_LIBRARY_PATH: "/usr/lib/native"
yarn.containers.vcores The number of virtual cores (vcores) per YARN container. By default, the number of vcores is set to the number of slots per TaskManager, if set, or to 1, otherwise.
yarn.taskmanager.env.: 和上边的环境变量配置一样,可以用前缀的形式给taskmanager进程配置环境变量。
yarn.application-master.port: 与AM通信的端口号或者列表。 默认是0,建议设置为默认值,即让操作系统决定一个可用的端口号作为通信端口。
当Flink on Yarn时,此参数可以指定一个端口范围作为一个受限制的防火墙。High Availability Mode
recovery.mode: 集群运行时的恢复模式,默认是standalone。当前Flink支持单jobManager的的standalone模式;当指定zookeeper时,代表用zookeeper作为Jobmanager的集群,zookeeper负责Jobmanager的leader选举。如果使用zookeeper模式,则强制要求指定recovery.zookeeper.quorom参数。
recovery.zookeeper.quorum: 当使用zookeeper作为恢复模式时,需要指定zookeeper的quorum,例如:flink:2181,data0:2181,mf:2181
recovery.zookeeper.path.root: zookeeper恢复模式时指定的用于创建命名空间的路径,默认/flink路径。
recovery.zookeeper.path.namespace: 在standalone或者yarn模式下,默认是/default_ns。此参数代表作为zookeeper模式下的znode的名字。即有可能跑多个集群,因此zookeeper需要标识每个集群的的信息,因此设置Flink集群唯一的标识给zookeeper。例如可以设置/cluster_first.
recovery.zookeeper.path.latch: 默认是/leaderlatch。定义用于leader选举的znode节点名。
recovery.zookeeper.path.leader: 默认是/leader。定义一个znode节点,保存当前leader的URL以及session ID信息。
recovery.zookeeper.storageDir: 定义Jobmanager的的元数据信息,zookeeper只是保存一个指向此目录的指针,在HA环境下用于Jobmanager的恢复。例如设置为: hdfs:///flink/recovery。
recovery.zookeeper.client.session-timeout: 定义zookeeper session的超时时间,默认60000毫秒。1分钟。
recovery.zookeeper.client.connection-timeout: 定义与zookeeper的连接超时时间,默认15000毫秒。
recovery.zookeeper.client.retry-wait: 定义每次重试等待的时间间隔,默认5000毫秒。
recovery.zookeeper.client.max-retry-attempts: 客户端重新连接的最大次数,默认是3次。
recovery.job.delay: 定义job恢复期间最大的延迟,默认是 ‘akka.ask.timeout’。Environment
env.log.dir: Flink的log目录,默认是$FLINK_HOME/log,必须制定全路径。Metrics
忽略。
引用
https://cwiki.apache.org/confluence/display/FLINK/Akka+and+Actors
http://vinoyang.com/2016/04/14/akka-in-flink/
http://wuchong.me/blog/2016/04/29/flink-internals-memory-manage/
https://ci.apache.org/projects/flink/flink-docs-release-1.1/setup/config.html#full-reference
http://doc.flink-china.org/apis/streaming/fault_tolerance.html#section-1
https://ci.apache.org/projects/flink/flink-docs-master/setup/fault_tolerance.html