目录
特点
Use Case
Flink vs Spark
架构
运行模式
Layered APIs & Component Stack
DataStream 例子
DataSet 例子
状态
Time、Watermark、Late Data
Windows
Checkpoint
DataStream 的 Sources、Transformations、Sinks
DataStream 的 Join
Process Function
异步 IO
DataSet 的 Sources、Transformation、Sinks
Table API & SQL
Library CEP
Library Gelly
特点
- 分布式并行计算框架
- 强大的状态管理,支持有状态的计算
- 支持流数据处理、和批数据处理,以流数据为基础,批处理是流处理的特例
- 支持基于数据自身携带的 event-time 进行处理,支持 Watermark 机制
- 提供基于时间、数量、会话的强大的 window 机制
- 提供精准一致语义 (exactly-once) 的保证机制
- 提供 checkpoint、savepoint,支持错误恢复、升级、伸缩等机制
- 提供流处理 DataStream API 和批处理 DataSet API,在此之上提供 SQL、Table API 统一流批接口
- 基于 Java 实现,提供 Scala 支持,在 Table API、SQL 层面提供 Python 支持
- 基于内存的计算、低延迟、高吞吐、高可用、可扩展、支持数千核心、支持 TB 级别的状态管理
- 多种部署方式:Standalone Cluster、Yarn、Mesos、K8S
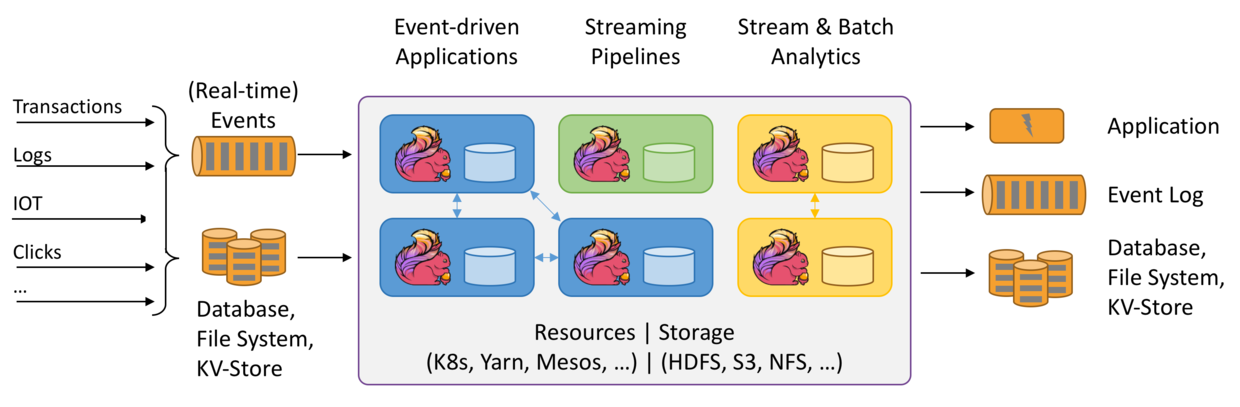
Use Case
- Event-Driven Applications:事件驱动程序,可以在收到一个或多个数据后实时做出响应,不需要等待 (相比较 Spark 就做不到,Spark 需要等待收到一批数据后才能响应,所以 Spark 的实时性不够),适用于 Fraud detection、Anomaly detection、Rule-based alerting、monitoring 等有实时响应要求的应用
- Data Analytics Applications:对有边界数据做批数据分析、对无边界数据做流数据分析 (实时地、持续地、增量地,获取数据、分析数据、更新结果),Flink 提供 SQL 接口统一对批数据和流数据的操作
- Data Pipeline Applications:类似 ETL,做数据的清理、扩展、入库,区别在于传统 ETL 是周期性启动程序,Flink 可以是一个程序在持续运行
Flink (最新 1.10 版本) vs Spark (最新 2.4.5)
- Flink 优点:有状态管理 ( Spark 只有 checkpoint )、强大的窗口机制 ( Spark 只支持时间窗口,不支持事件窗口、会话窗口)、实时性更强 ( Spark 是通过微批处理,延时比较高,而且无法基于事件实时响应,Flink 原生就是基于数据流/事件流的 )、exactly-once 的实现比 Spark 要好
- Spark 优点:流批统一得更好、批处理能力更强、MachineLearning 投入更多、原生 Scala 支持 Java/Python ( Flink 原生 Java,支持 Scala,只在 Table API、SQL 层面支持 Python,而 Scala 比 Java 简洁 )
架构
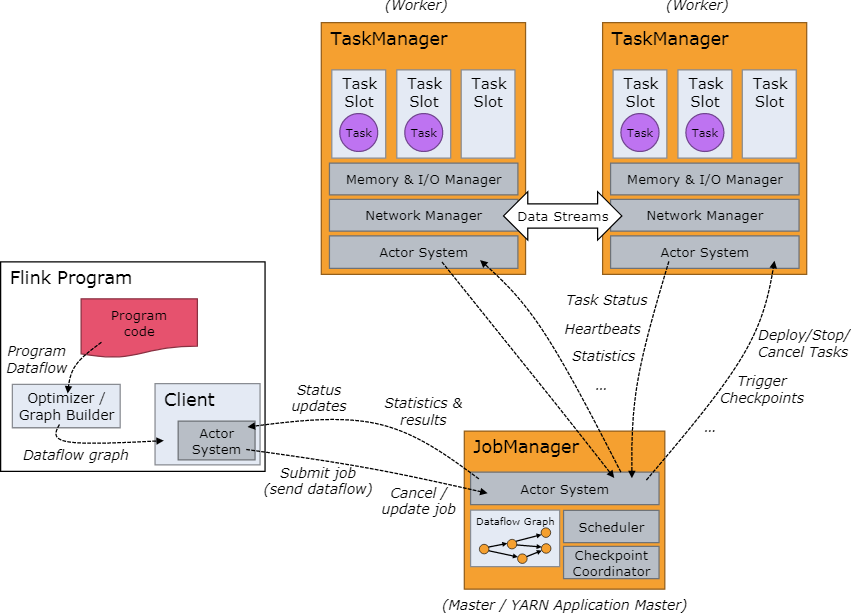
JobManagers
也叫 masters,至少一个,也可以配置多个实现 HA,负责管理集群、调度任务、协调分布式执行、协调 checkpoints 和故障恢复等等,JobManager 有 3 个主要的组件
- ResourceManager:负责 Flink 集群资源的管理和配置,管理 TaskManager 的 task slots,在不同的部署模式下(Standalone、Yarn、Mesos、K8S)会有不同的实现,在 Standalone 模式下,JobManager 无法根据需要自己启动新的 TaskManager
- Dispatcher:提供 REST 接口用以接受 Client 提交 Flink 程序,同时用于启动 JobManager 程序,并且提供 WebUI 用于查询 Job 信息
- JobMaster:用于管理一个 JobGraph 的执行,多个 Job 可以同时运行,每个 Job 都有自己的 JobMaster
TaskManagers
也叫 workers,至少要有一个,用于执行数据流的任务,缓存和交换数据,TaskManagers 需要和 JobManagers 建议链接,报告自己的状态,接受任务的分配
TaskManager 是一个 JVM 进程,管理着一个或多个 task slots,代表 TaskManager 最多能同时接收多少 task,每个 task slot 是一个 thread,每个 slot 会预留相应的内存不会被其他 slot 占据,现在 slot 只预留内存资源,不预留其他资源比如 CPU,同一个 TaskManager 的不同 task 可以共享相同的 TCP 链接和心跳信息,也可以共享数据集和数据结构,可以有效减少 overhead
Flink 默认允许不同 tasks 的 subtasks 共享 slots,只要这些 tasks 是来自同一个 Job,这样有可能管理着一个 Job 的整个 pipeline,这样可以有效提高资源利用率
Task slots 的数量最好配置成和 CPU 的核心数量一样
Client
通过 flink run 命令准备并将任务提交给 JobManager,然后就可以退出了,也可以保持链接以接受 JobManager 返回的运行状态
运行模式
- Flink Session Cluster:有一个长期运行的、提前规划好资源的集群,所有 client 向同一个集群提交 Job,缺点是有资源的竞争、JobManager 和 TaskManager 出错的话会影响所有 Job,优点是启动快,适合那些频繁启动、运行时间短、要求快速启动响应的程序
- Flink Job Cluster:每个 Job 都有独立的集群,需要提交 Job 到外部程序比如 Yarn、K8S 等,然后由这些外部程序先分配资源,然后用分配的资源启动 JobManager,再根据 Job 的需求启动 TaskManager,再运行程序,优点是每个 Job 都是独立的互不影响,缺点是启动时间长、缺乏统一管理,适合那些需要长期运行、对启动时间不敏感的程序
- Flink Application Cluster:将应用和依赖打包成一个可运行的 Jar 包直接运行,不需要先启动集群再提交 Job,而是一步到位直接启动程序
- Self-contained Flink Applications:there are efforts in the community towards fully enabling Flink-as-a-Library in the future.
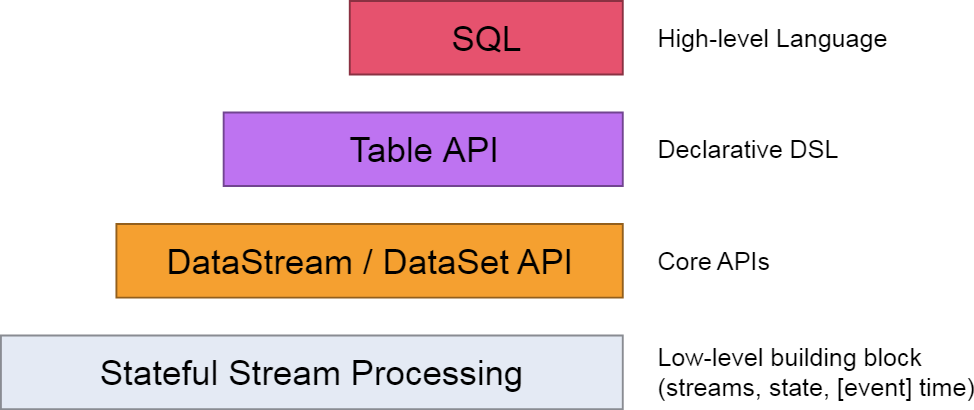
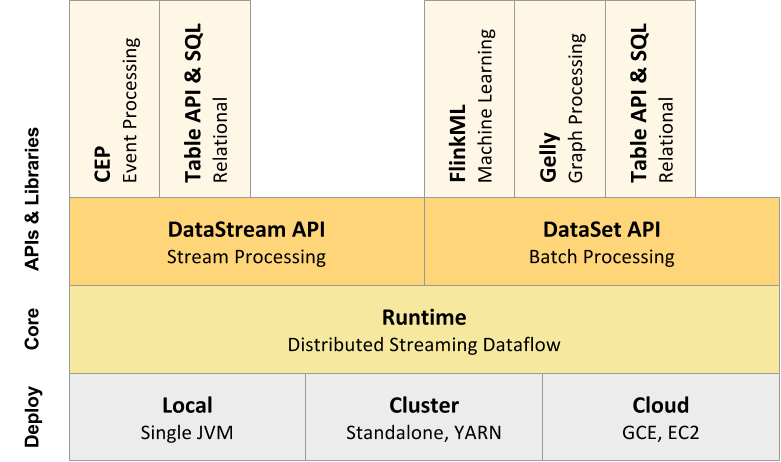
Layered APIs & Component Stack
Flink 提供了不同 level 的 API 供程序使用
DataStream 例子
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
public class WindowWordCount {
public static void main(String[] args) throws Exception {
// env 的初始化和 DataSet 不一样
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Tuple2<String, Integer>> dataStream = env
.socketTextStream("localhost", 9999)
.flatMap(new Splitter())
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1);
dataStream.print();
env.execute("Window WordCount");
}
public static class Splitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String sentence, Collector<Tuple2<String, Integer>> out) throws Exception {
for (String word: sentence.split(" ")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
}
更多信息参考 https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/datastream_api.html
DataSet 例子
public class WordCountExample {
public static void main(String[] args) throws Exception {
// env 的初始化和 DataStream 不一样
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<String> text = env.fromElements(
"Who's there?",
"I think I hear them. Stand, ho! Who's there?");
DataSet<Tuple2<String, Integer>> wordCounts = text
.flatMap(new LineSplitter())
.groupBy(0)
.sum(1);
wordCounts.print();
}
public static class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> out) {
for (String word : line.split(" ")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
}
更多信息参考 https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/batch/
状态
如果一个流处理程序,需要对多个数据计算才能得出结果,那么通常这个程序就是有状态的,需要保存某个值,或某个中间结果,比如有个程序用于实时监控司机的驾驶状态,如果连续驾驶 3 小时就要立刻出告警信息,这就需要保存每个司机的状态,以司机为 key,保存开始计时的时间,既 (Driver, StartTime),收到新数据后,如果显示司机没在驾驶,就更新 StartTime 为当前时间,如果在驾驶,就和 StartTime 比较,如果超过 3 小时,就发告警信息,Flink 会自动帮我们管理并保存这个状态信息,并且如果程序出错重启,能自动恢复这个状态,这样能继续从出错时读取的数据开始继续运行,而不需要回溯历史数据重新计算,Flink 的状态管理功能简化了应用程序的编写,让应用程序更专注于业务上
Flink 的状态管理功能包括:
- Multiple State Primitives:支持多种数据类型的状态,包括基本数据类型,list 类型,map 类型,等等
- Pluggable State Backends:可插拔的状态后端,状态后端用于管理状态,决定了一个状态最多能有多大,异步还是同步,用什么方法保存,保存在什么地方,Flink 可以通过配置就能改变所有 Job 的 State Backend,也可以每个 Job 的代码自己决定,Flink 提供了几个 State Backend:
1)MemoryStateBackend(默认,用于少量状态或测试),Checkpoint 候把状态保存到 JobManager 的内存;
2)FsStateBackend,Checkpoint 时把状态保存到文件系统;
3)RocksDBStateBackend,运行时和 Checkpoint 时都是把状态落盘到 RocksDB,只支持异步;
4)用户自定义的 State Backend
更多信息参考 https://ci.apache.org/projects/flink/flink-docs-release-1.10/ops/state/state_backends.html - Exactly-once state consistency: 通过 Checkpoint 和恢复机制保证状态的一致性,使失败处理对程序透明
- Very Large State: 通过异步保存和增量 checkpoint 算法,Flink Job 可以维护 TB 级别的状态
- Scalable Applications: Flink supports scaling of stateful applications by redistributing the state to more or fewer workers.
Flink 有两种基本的 State
- Keyed State:和 key 相关的一种 state,只能用于 KeyedStream 类型数据集对应的 functions 和 operators 上,每个 Keyed State 和一个 Operator 和 Key 的组合绑定,Keyed State 通过 Key Groups 组织,Flink 以 Key Groups 为单位重新调度 Keyed State
- Operator State:和 operator 的一个并行实例绑定的 state,Kafka Connector 就是一个使用 Operator State 的例子,Kafka consumer 的每个并行实例有一个 Operator State 用于维护一个 topic partitions 和 offsets 的 map
State 以两种形式存在
- 托管:就是数据结构是 Flink 知道的,比如 list,可以完全交给 Flink 管理
- 原生:就是数据结构是自己定义的,Flink 不清楚,只当成二进制数据,需要 operator 做进一步处理
Flink 能管理的类型包括:
- ValueState
- ListState
- ReducingState
- AggregatingState<IN, OUT>
- FoldingState<T, ACC>
- MapState<UK, UV>
更多信息参考 https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/stream/state/state.html
KeyedState 例子
public class CountWindowAverage extends RichFlatMapFunction<Tuple2<Long, Long>, Tuple2<Long, Long>> {
private transient ValueState<Tuple2<Long, Long>> sum;
@Override
public void flatMap(Tuple2<Long, Long> input, Collector<Tuple2<Long, Long>> out) throws Exception {
Tuple2<Long, Long> currentSum = sum.value();
currentSum.f0 += 1;
currentSum.f1 += input.f1;
sum.update(currentSum);
if (currentSum.f0 >= 2) {
out.collect(new Tuple2<>(input.f0, currentSum.f1 / currentSum.f0));
sum.clear();
}
}
@Override
public void open(Configuration config) {
ValueStateDescriptor<Tuple2<Long, Long>> descriptor =
new ValueStateDescriptor<>(
"average", // the state name
TypeInformation.of(new TypeHint<Tuple2<Long, Long>>() {}), // type information
Tuple2.of(0L, 0L)); // default value of the state, if nothing was set
sum = getRuntimeContext().getState(descriptor);
}
}
// this can be used in a streaming program like this (assuming we have a StreamExecutionEnvironment env)
env.fromElements(Tuple2.of(1L, 3L), Tuple2.of(1L, 5L), Tuple2.of(1L, 7L), Tuple2.of(1L, 4L), Tuple2.of(1L, 2L))
.keyBy(0)
.flatMap(new CountWindowAverage())
.print();
// the printed output will be (1,4) and (1,5)
// 第一个是 (3+5)/2,第二个是 (7+4)/2,接下来只剩一个不会触发
// 这个例子都是相同的 key,如果是不同的 key 会按 key 聚合,sum 会自动和 key 关联
Operator State 例子(通过 state 使得 sink operator 实现 offset 错误恢复机制)
public class BufferingSink
implements SinkFunction<Tuple2<String, Integer>>,
CheckpointedFunction {
private final int threshold;
private transient ListState<Tuple2<String, Integer>> checkpointedState;
private List<Tuple2<String, Integer>> bufferedElements;
public BufferingSink(int threshold) {
this.threshold = threshold;
this.bufferedElements = new ArrayList<>();
}
@Override
public void invoke(Tuple2<String, Integer> value, Context contex) throws Exception {
bufferedElements.add(value);
if (bufferedElements.size() == threshold) {
for (Tuple2<String, Integer> element: bufferedElements) {
// send it to the sink
}
bufferedElements.clear();
}
}
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
checkpointedState.clear();
for (Tuple2<String, Integer> element : bufferedElements) {
checkpointedState.add(element);
}
}
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
ListStateDescriptor<Tuple2<String, Integer>> descriptor =
new ListStateDescriptor<>(
"buffered-elements",
TypeInformation.of(new TypeHint<Tuple2<String, Integer>>() {}));
// 和 key state 的差别,这里调用 getOperatorStateStore,初始化方式不一样,而 state 的定义可以一样
checkpointedState = context.getOperatorStateStore().getListState(descriptor);
if (context.isRestored()) {
for (Tuple2<String, Integer> element : checkpointedState.get()) {
bufferedElements.add(element);
}
}
}
}
State-Backend 可以在 flink-conf.yaml 设置
# The backend that will be used to store operator state checkpoints
state.backend: filesystem
# Directory for storing checkpoints
state.checkpoints.dir: hdfs://namenode:40010/flink/checkpoints
也可以在每个 Job 设置
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new FsStateBackend("hdfs://namenode:40010/flink/checkpoints"));
State 还可以设置 TTL,超时的 State 会被清除
Time、Watermark、Late Data
Flink 流处理程序支持基于不同类型的时间进行操作(比如 Window 操作)
- Event Time:基于数据自身携待的时间
- Ingestion Time:基于数据被 Flink 收到时的系统时间
- Processing Time(默认):基于程序执行操作时的系统时间
指定时间类型
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
// env.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime);
// env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
DataStream<MyEvent> stream = env.addSource(new FlinkKafkaConsumer09<MyEvent>(topic, schema, props));
stream.keyBy( (event) -> event.getUser() )
.timeWindow(Time.hours(1))
.reduce( (a, b) -> a.add(b) )
.addSink(...);
没指定的话默认是 Processing Time
基于窗口的运算中,可能会出现数据的乱序和延迟,即某个窗口结束后,依然有属于该窗口的数据到来,Flink 通过 Watermarking (水印)指定最多可容忍多久的延迟、控制触发窗口计算的时机
Flink 可以自定义时间字段,以及自定义 Watermark 时间,Flink 触发窗口计算的条件:
- Watermark 时间 >= 窗口的结束时间
- 窗口的时间范围内有数据
比如窗口大小是 10 分钟,那么(0,10)这个窗口在 Watermark 时间大于 10 的时候触发
Flink 提供了统一的 DataStream.assignTimestampsAndWatermarks() 方法提取事件时间并产生 Watermark
assignTimestampsAndWatermarks() 接受的类型有
- AssignerWithPeriodicWatermarks
- AssignerWithPunctuatedWatermarks
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
DataStream<MyEvent> stream = env.readFile(
myFormat, myFilePath, FileProcessingMode.PROCESS_CONTINUOUSLY, 100,
FilePathFilter.createDefaultFilter(), typeInfo);
DataStream<MyEvent> withTimestampsAndWatermarks = stream
.filter( event -> event.severity() == WARNING )
// MyTimestampsAndWatermarks 是自己实现的 AssignerWithPeriodicWatermarks 或 AssignerWithPunctuatedWatermarks 的子类
.assignTimestampsAndWatermarks(new MyTimestampsAndWatermarks());
withTimestampsAndWatermarks
.keyBy( (event) -> event.getGroup() )
.timeWindow(Time.seconds(10))
.reduce( (a, b) -> a.add(b) )
.addSink(...);
AssignerWithPeriodicWatermarks 是周期性产生 Watermarks
默认周期 200ms,通过ExecutionConfig.setAutoWatermarkInterval() 可以指定新的周期
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.getConfig().setAutoWatermarkInterval(200);
每次产生 Watermarks 的时候是通过调用 AssignerWithPeriodicWatermarks 的 getCurrentWatermark() 函数
时间的获取则是通过 AssignerWithPeriodicWatermarks 的 extractTimestamp 函数实现
// 这个自定义的类,将所有收到的数据所携待的时间的最大值,减去 maxOutOfOrderness 作为 Watermark
// 假设窗口大小是 10 分钟,maxOutOfOrderness 是 3 分钟,那么
// (0,10)窗口需要在收到的数据时间大于等于 13 的时候才触发
public class MyTimestampsAndWatermarks implements AssignerWithPeriodicWatermarks<MyEvent> {
private final long maxOutOfOrderness = 3500; // 3.5 seconds
private long currentMaxTimestamp;
@Override
public long extractTimestamp(MyEvent element, long previousElementTimestamp) {
// 每来一条数据就解析数据的时间,用以更新 Watermark,其中 MyEvent 是自定义的数据类
long timestamp = element.getCreationTime();
currentMaxTimestamp = Math.max(timestamp, currentMaxTimestamp);
return timestamp;
}
@Override
public Watermark getCurrentWatermark() {
// getCurrentWatermark 被周期性的调用
// 如果返回的 Watermark 大于窗口的结束时间,那就触发窗口的计算
return new Watermark(currentMaxTimestamp - maxOutOfOrderness);
}
}
Flink 提供了几个内置的 AssignerWithPeriodicWatermarks 类
// AscendingTimestampExtractor
// 新数据的时间变大就直接将该时间作为 Watermark,否则进行异常处理
// 需要自定义 extractAscendingTimestamp 函数获取时间
public abstract long extractAscendingTimestamp(T element);
@Override
public final long extractTimestamp(T element, long elementPrevTimestamp) {
final long newTimestamp = extractAscendingTimestamp(element);
if (newTimestamp >= this.currentTimestamp) {
this.currentTimestamp = newTimestamp;
return newTimestamp;
} else {
violationHandler.handleViolation(newTimestamp, this.currentTimestamp);
return newTimestamp;
}
}
@Override
public final Watermark getCurrentWatermark() {
return new Watermark(currentTimestamp == Long.MIN_VALUE ? Long.MIN_VALUE : currentTimestamp - 1);
}
// BoundedOutOfOrdernessTimestampExtractor
// 新数据的时间变大,就在该时间的基础上减去一个阀值 maxOutOfOrderness 作为 Watermark
// 需要自定义 extractTimestamp 获取数据时间
public BoundedOutOfOrdernessTimestampExtractor(Time maxOutOfOrderness) {
if (maxOutOfOrderness.toMilliseconds() < 0) {
throw new RuntimeException("Tried to set the maximum allowed " +
"lateness to " + maxOutOfOrderness + ". This parameter cannot be negative.");
}
this.maxOutOfOrderness = maxOutOfOrderness.toMilliseconds();
this.currentMaxTimestamp = Long.MIN_VALUE + this.maxOutOfOrderness;
}
public abstract long extractTimestamp(T element);
@Override
public final Watermark getCurrentWatermark() {
long potentialWM = currentMaxTimestamp - maxOutOfOrderness;
if (potentialWM >= lastEmittedWatermark) {
lastEmittedWatermark = potentialWM;
}
return new Watermark(lastEmittedWatermark);
}
@Override
public final long extractTimestamp(T element, long previousElementTimestamp) {
long timestamp = extractTimestamp(element);
if (timestamp > currentMaxTimestamp) {
currentMaxTimestamp = timestamp;
}
return timestamp;
}
// IngestionTimeExtractor
// 基于系统时间生成 Watermark
@Override
public long extractTimestamp(T element, long previousElementTimestamp) {
final long now = Math.max(System.currentTimeMillis(), maxTimestamp);
maxTimestamp = now;
return now;
}
@Override
public Watermark getCurrentWatermark() {
final long now = Math.max(System.currentTimeMillis(), maxTimestamp);
maxTimestamp = now;
return new Watermark(now - 1);
}
AssignerWithPunctuatedWatermarks 是打点型 Watermark,就是每次收到数据,都会判断是不是要立刻产生 Watermark
public class MyTimestampsAndWatermarks implements AssignerWithPunctuatedWatermarks<MyEvent> {
@Override
public long extractTimestamp(MyEvent element, long previousElementTimestamp) {
return element.getCreationTime();
}
@Override
public Watermark checkAndGetNextWatermark(MyEvent lastElement, long extractedTimestamp) {
// checkAndGetNextWatermark 会在 extractTimestamp 之后被立刻调用
return lastElement.hasWatermarkMarker() ? new Watermark(extractedTimestamp) : null;
}
}
打点型 Watermark 没有内置类
如果 Window 的数据源有多个,每个都有自己的 Watermark,那么会选取最小的那个
如果希望处理在窗口被 Watermark 触发后才到来的数据,一般有两种方法
- Allowed Lateness
- Side Outputs
DataStream<T> input = ...;
input
.keyBy(<key selector>)
.window(<window assigner>)
.allowedLateness(Time.seconds(30))
.<windowed transformation>(<window function>);
allowedLateness(Time.seconds(30)) 会在窗口计算结束后,依然保留 30s 不销毁,这段时间内如果有属于这个窗口的数据进来,还可以进行计算
final OutputTag<T> lateOutputTag = new OutputTag<T>("late-data"){};
DataStream<T> input = ...;
SingleOutputStreamOperator<T> result = input
.keyBy(<key selector>)
.window(<window assigner>)
.allowedLateness(Time.seconds(30))
.sideOutputLateData(lateOutputTag)
.<windowed transformation>(<window function>);
DataStream<T> lateStream = result.getSideOutput(lateOutputTag);
sideOutputLateData(lateOutputTag) 将窗口结束后才到来的数据进行分流,可以对其单独处理
Debugging Watermarks:
https://ci.apache.org/projects/flink/flink-docs-release-1.10/monitoring/debugging_event_time.html
Windows
大体上有两种 Windows
Keyed Windows
stream
.keyBy(...) <- keyed versus non-keyed windows
.window(...) <- required: "assigner"
[.trigger(...)] <- optional: "trigger" (else default trigger)
[.evictor(...)] <- optional: "evictor" (else no evictor)
[.allowedLateness(...)] <- optional: "lateness" (else zero)
[.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/fold/apply() <- required: "function"
[.getSideOutput(...)] <- optional: "output tag"
Non-Keyed Windows
stream
.windowAll(...) <- required: "assigner"
[.trigger(...)] <- optional: "trigger" (else default trigger)
[.evictor(...)] <- optional: "evictor" (else no evictor)
[.allowedLateness(...)] <- optional: "lateness" (else zero)
[.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/fold/apply() <- required: "function"
[.getSideOutput(...)] <- optional: "output tag"
可以看到两者的主要区别在于 .keyBy.window 还是 .windowAll
对于 keyed streams,计算由多个并行的 task 执行,相同的 key 的数据会被同一个 task 计算
对于 non-keyed streams,所有的计算由一个单独的 task 执行
Window Assigners 决定了如何将数据分配给 Window
Flink 定义了几种常用的窗口机制:tumbling windows,sliding windows,session windows,global windows
除了 global windows 其他几种 Windows 都是基于时间,可以是 processing time 或者 event time
Flink 也运行用户通过继承 WindowAssigner 类自定义窗口机制
Tumbling Windows:翻滚窗口,固定窗口大小,且窗口没有重叠
DataStream<T> input = ...;
// tumbling event-time windows
input
.keyBy(<key selector>)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.<windowed transformation>(<window function>);
// tumbling processing-time windows
input
.keyBy(<key selector>)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.<windowed transformation>(<window function>);
// daily tumbling event-time windows offset by -8 hours.
input
.keyBy(<key selector>)
.window(TumblingEventTimeWindows.of(Time.days(1), Time.hours(-8))) // 用于调整时区
.<windowed transformation>(<window function>);
Sliding Windows:滑动窗口,窗口大小固定,可以有重叠,比如大小 20 滑动距离 5 的两个窗口(0,20)和(5,25)
DataStream<T> input = ...;
// sliding event-time windows
input
.keyBy(<key selector>)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.<windowed transformation>(<window function>);
// sliding processing-time windows
input
.keyBy(<key selector>)
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.<windowed transformation>(<window function>);
// sliding processing-time windows offset by -8 hours
input
.keyBy(<key selector>)
.window(SlidingProcessingTimeWindows.of(Time.hours(12), Time.hours(1), Time.hours(-8)))
.<windowed transformation>(<window function>);
Session Windows:没有固定的窗口大小,当一定时间内没收到新数据时,就将之前收到的数据作为一个窗口
DataStream<T> input = ...;
// event-time session windows with static gap(10 分钟内没收到数据就触发窗口)
input
.keyBy(<key selector>)
.window(EventTimeSessionWindows.withGap(Time.minutes(10)))
.<windowed transformation>(<window function>);
// event-time session windows with dynamic gap(自定义窗口间隔时间)
input
.keyBy(<key selector>)
.window(EventTimeSessionWindows.withDynamicGap((element) -> {
// determine and return session gap
}))
.<windowed transformation>(<window function>);
// processing-time session windows with static gap(10 分钟内没收到数据就触发窗口)
input
.keyBy(<key selector>)
.window(ProcessingTimeSessionWindows.withGap(Time.minutes(10)))
.<windowed transformation>(<window function>);
// processing-time session windows with dynamic gap(自定义窗口间隔时间)
input
.keyBy(<key selector>)
.window(ProcessingTimeSessionWindows.withDynamicGap((element) -> {
// determine and return session gap
}))
.<windowed transformation>(<window function>);
Global Windows:将相同 key 的数据作为一个窗口,需要自定义窗口触发机制 Trigger(比如收多少个数据后触发)
DataStream<T> input = ...;
input
.keyBy(<key selector>)
.window(GlobalWindows.create())
.trigger(CountEvictor.of(size))
.<windowed transformation>(<window function>);
Flink 还提供了 timeWindow 和 countWindow 函数做了封装
public WindowedStream<T, KEY, TimeWindow> timeWindow(Time size) {
if (environment.getStreamTimeCharacteristic() == TimeCharacteristic.ProcessingTime) {
return window(TumblingProcessingTimeWindows.of(size));
} else {
return window(TumblingEventTimeWindows.of(size));
}
}
public WindowedStream<T, KEY, TimeWindow> timeWindow(Time size, Time slide) {
if (environment.getStreamTimeCharacteristic() == TimeCharacteristic.ProcessingTime) {
return window(SlidingProcessingTimeWindows.of(size, slide));
} else {
return window(SlidingEventTimeWindows.of(size, slide));
}
}
public WindowedStream<T, KEY, GlobalWindow> countWindow(long size) {
return window(GlobalWindows.create()).trigger(PurgingTrigger.of(CountTrigger.of(size)));
}
public WindowedStream<T, KEY, GlobalWindow> countWindow(long size, long slide) {
return window(GlobalWindows.create())
.evictor(CountEvictor.of(size))
.trigger(CountTrigger.of(slide));
}
如果有特殊要求就自定义 WindowAssigner 子类
Triggers 决定了 Windows 如何被触发
每个 Trigger 主要有下面几个函数
- onElement:有数据添加到窗口时执行
- onEventTime:触发 event time 计时器时执行
- onProcessingTime:触发 processing time 计时器时执行
- onMerge:窗口合并时执行
- clear:清理窗口时执行
前三个函数返回 TriggerResult 告知 Flink 需要对窗口执行什么操作,主要有
- CONTINUE:什么都不用做
- FIRE:触发窗口计算
- PURGE:清理窗口数据
- FIRE_AND_PURGE:触发并清理窗口
内置的 Trigger 都只触发 FIRE 不会触发 PURGE
Flink 内置的 Triggers
- EventTimeTrigger:将 event-time 作为窗口时间,当 watermark 超过窗口 end time 时触发
- ProcessingTimeTrigger:将 processing-time 作为窗口时间,当 watermark 超过窗口 end time 时触发
- CountTrigger:窗口内的数据量超过上限时触发
- PurgingTrigger:Trigger 的包装类,被包装的 Trigger 返回 FIRE 时,将返回值改为 FIRE_AND_PURGE
如果有特殊需求可以自定义 Trigger 子类
Window Functions
- ReduceFunction:两个输入,产生一个输出
DataStream<Tuple2<String, Long>> input = ...;
input
.keyBy(<key selector>)
.window(<window assigner>)
.reduce(new ReduceFunction<Tuple2<String, Long>> {
public Tuple2<String, Long> reduce(Tuple2<String, Long> v1, Tuple2<String, Long> v2) {
return new Tuple2<>(v1.f0, v1.f1 + v2.f1);
}
});
- AggregateFunction:聚合函数,需要定义三个数据,输入数据类型,中间值类型,输出值类型
private static class AverageAggregate
implements AggregateFunction<Tuple2<String, Long>, Tuple2<Long, Long>, Double> {
@Override
public Tuple2<Long, Long> createAccumulator() {
return new Tuple2<>(0L, 0L);
}
// add 函数依据每个输入数据,更新中间值
@Override
public Tuple2<Long, Long> add(Tuple2<String, Long> value, Tuple2<Long, Long> accumulator) {
return new Tuple2<>(accumulator.f0 + value.f1, accumulator.f1 + 1L);
}
// getResult 函数依据中间值,计算输出值
@Override
public Double getResult(Tuple2<Long, Long> accumulator) {
return ((double) accumulator.f0) / accumulator.f1;
}
// merge 函数合并两个中间值
@Override
public Tuple2<Long, Long> merge(Tuple2<Long, Long> a, Tuple2<Long, Long> b) {
return new Tuple2<>(a.f0 + b.f0, a.f1 + b.f1);
}
}
DataStream<Tuple2<String, Long>> input = ...;
input
.keyBy(<key selector>)
.window(<window assigner>)
.aggregate(new AverageAggregate());
- FoldFunction:直接依据输入数据,更新输出结果
DataStream<Tuple2<String, Long>> input = ...;
input
.keyBy(<key selector>)
.window(<window assigner>)
.fold("", new FoldFunction<Tuple2<String, Long>, String>> {
public String fold(String acc, Tuple2<String, Long> value) {
// 在前面的 acc 基础上,根据输入数据产生新的 acc,并且 acc 会作为最终输出,acc 的初始值由 fold 函数指定
return acc + value.f1;
}
});
- ProcessWindowFunction:最灵活的方式,可以获取窗口的所有数据,但更耗性能和资源
DataStream<Tuple2<String, Long>> input = ...;
input.keyBy(t -> t.f0)
.timeWindow(Time.minutes(5))
.process(new MyProcessWindowFunction());
public class MyProcessWindowFunction extends ProcessWindowFunction<Tuple2<String, Long>, String, String, TimeWindow> {
@Override
public void process(String key, Context context, Iterable<Tuple2<String, Long>> input, Collector<String> out) {
long count = 0;
for (Tuple2<String, Long> in: input) {
count++;
}
out.collect("Window: " + context.window() + "count: " + count);
}
}
ProcessWindowFunction 还可以和 ReduceFunction、AggregateFunction、FoldFunction 等函数结合
DataStream<SensorReading> input = ...;
input.keyBy(<key selector>)
.timeWindow(<duration>)
.reduce(new MyReduceFunction(), new MyProcessWindowFunction());
private static class MyReduceFunction implements ReduceFunction<SensorReading> {
public SensorReading reduce(SensorReading r1, SensorReading r2) {
return r1.value() > r2.value() ? r2 : r1;
}
}
private static class MyProcessWindowFunction
extends ProcessWindowFunction<SensorReading, Tuple2<Long, SensorReading>, String, TimeWindow> {
public void process(String key,
Context context,
Iterable<SensorReading> minReadings,
Collector<Tuple2<Long, SensorReading>> out) {
// 窗口结束后,如果只有 reduce 会直接把 reduce 的结果输出
// 结合 ProcessWindowFunction 后会把 reduce 结果再传给 ProcessWindowFunction 再进一步处理
// 这里在 reduce 的基础上把 window 的 start time 加入到输出
SensorReading min = minReadings.iterator().next();
out.collect(new Tuple2<Long, SensorReading>(context.window().getStart(), min));
}
}
有的地方可以用旧版本的 WindowFunction
Evictors
用于在窗口执行之前或窗口执行之后删除数据,Evictor 类主要由两个函数实现
void evictBefore(Iterable<TimestampedValue<T>> elements, int size, W window, EvictorContext evictorContext);
void evictAfter(Iterable<TimestampedValue<T>> elements, int size, W window, EvictorContext evictorContext);
Flink 有三个内置的 Evictors
- CountEvictor:指定保留最近的多少个数据,其余丢弃,可以参考前面滑动计数窗口 countWindow 的例子
- DeltaEvictor:自定义 DeltaFunction 和 threshold,和最后一个数据的 delta 超过 threshold 的会被丢弃
- TimeEvictor:找到所有数据的最大时间戳 max_ts,把时间戳小于 max_ts - interval 的数据删除
内置 Evictors 默认都是在 window function 前执行
Flink 不保证 Window 内元素的顺序,即先来到的数据不一定排在窗口的前面
Allowed Lateness & Side Output
final OutputTag<T> lateOutputTag = new OutputTag<T>("late-data"){};
DataStream<T> input = ...;
SingleOutputStreamOperator<T> result = input
.keyBy(<key selector>)
.window(<window assigner>)
.allowedLateness(Time.seconds(30))
.sideOutputLateData(lateOutputTag)
.<windowed transformation>(<window function>);
DataStream<T> lateStream = result.getSideOutput(lateOutputTag);
讲 Watermark 的时候也提到了,就是允许窗口计算结束后依然等待一段时间,如果还有属于这个窗口的数据到来,还可以触发新的计算,也可以将迟到数据放到另一个数据流处理
Checkpoint
Checkpoint 用于定期存储 data source 被消费的位置,以及应用程序自己使用的 state(参考前面状态部分)
实现 Checkpoint 的前提条件
- data source 的数据能保存一定时间,可以从指定的位置重复消费,比如消息队列(Kafka、RabbitMQ、Amazon Kinesis、Google PubSub 等)或文件系统(HDFS、S3、GFS、NFS、Ceph 等)
- 永久存储系统,通常都是分布式文件系统,比如 HDFS、S3、GFS、NFS、Ceph 等
Checkpoint 默认是关闭的,需要在代码里设置打开
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// start a checkpoint every 1000 ms
env.enableCheckpointing(1000);
// advanced options:
// set mode to exactly-once (this is the default)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// make sure 500 ms of progress happen between checkpoints
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
// checkpoints have to complete within one minute, or are discarded
env.getCheckpointConfig().setCheckpointTimeout(60000);
// allow only one checkpoint to be in progress at the same time
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// enable externalized checkpoints which are retained after job cancellation
env.getCheckpointConfig().enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// allow job recovery fallback to checkpoint when there is a more recent savepoint
env.getCheckpointConfig().setPreferCheckpointForRecovery(true);
conf/flink-conf.yaml 文件里更多相应的设置可以参考
https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/stream/state/checkpointing.html#related-config-options
要在 Iterative Jobs(查看 Iterate Transformation 部分)打开 Checkpoint 需要多指定一个参数,并且有可能丢数据
env.enableCheckpointing(interval, CheckpointingMode.EXACTLY_ONCE, force = true)
Checkpoint 可以异步和增量的执行,这样可以减少对数据处理的影响
Checkpoint 只要保证最新的就行,旧的可以被自动删除
Savepoint 和 Checkpoint 一样,区别在于 Savepoint 是认为触发的,生成的 Savepoint 不会超时
比如通过 flink stop
Suspending job "c2cbdb0bca115d2375706b2c95d8a323" with a savepoint.
Savepoint completed. Path: file:/tmp/flink-savepoints-directory/savepoint-c2cbdb-8d350f39371f
可以从指定的 Savepoint 恢复程序
flink run -s /tmp/flink-savepoints-directory/savepoint-c2cbdb-8d350f39371f flink-app.jar
更多信息参考 https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/stream/state/checkpointing.html
DataStream 的 Sources、Transformations、Sinks
StreamExecutionEnvironment 提供一些函数用于接入数据源
readTextFile(String filePath)
readTextFile(String filePath, String charsetName)
readFile(FileInputFormat<OUT> inputFormat, String filePath)
readFile(FileInputFormat<OUT> inputFormat, String filePath, FileProcessingMode watchType,
long interval, TypeInformation<OUT> typeInformation)
readFile(FileInputFormat<OUT> inputFormat, String filePath, FileProcessingMode watchType,
long interval, FilePathFilter filter)
socketTextStream(String hostname, int port)
socketTextStream(String hostname, int port, String delimiter, long maxRetry)
fromCollection(Collection<OUT> data)
fromCollection(Iterator<OUT> data, Class<OUT> type)
fromElements(OUT... data)
fromParallelCollection(SplittableIterator<OUT> iterator, Class<OUT> type)
generateSequence(long from, long to)
也可以通过 StreamExecutionEnvironment 的 addSource 函数添加 connectors(预定义或自定义的)
addSource(new FlinkKafkaConsumer08<>("topic", new SimpleStringSchema(), properties)
addSource(new FlinkKinesisConsumer<>("kinesis_stream_name", new SimpleStringSchema(), consumerConfig))
addSource(new TwitterSource(props))
addSource(new RMQSource<String>(connectionConfig, "queueName", true, new SimpleStringSchema()))
addSource(new NiFiSource(clientConfig))
DataStream Transformations 的主要函数有
map
flatMap
filter
keyBy
reduce
fold // 用于将所有数据合成一个结果
sum
min
max
minBy
maxBy
keyBy(0).window
windowAll
windowedStream.apply
allWindowedStream.apply
union
dataStream.join(otherStream).where(<key selector>).equalTo(<key selector>)
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
keyedStream.intervalJoin(otherKeyedStream).between(Time.milliseconds(-2), Time.milliseconds(2))
.upperBoundExclusive(true).lowerBoundExclusive(true)
dataStream.coGroup(otherStream).where(0).equalTo(1)
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
someStream.connect(otherStream)
split & select
stream.assignTimestamps // 用于从数据中解析出时间戳,这个时间戳可以和 window 配合
initialStream.iterate() // 后面细讲
dataStream.partitionCustom
dataStream.shuffle
dataStream.rebalance
Iterate Transformation
DataStream<Long> someIntegers = env.generateSequence(0, 1000);
IterativeStream<Long> iteration = someIntegers.iterate(); // iterate 可以带参数指定最大迭代次数
DataStream<Long> minusOne = iteration.map(new MapFunction<Long, Long>() {
@Override
public Long map(Long value) throws Exception {
return value - 1 ;
}
});
DataStream<Long> stillGreaterThanZero = minusOne.filter(new FilterFunction<Long>() {
@Override
public boolean filter(Long value) throws Exception {
return (value > 0);
}
});
// 把 stillGreaterThanZero 里面的值扔回去,从 iteration.map 开始继续计算
// 直到 stillGreaterThanZero 为空,或是达到最大迭代次数
iteration.closeWith(stillGreaterThanZero);
// 取出不再需要迭代的数据
DataStream<Long> lessThanZero = minusOne.filter(new FilterFunction<Long>() {
@Override
public boolean filter(Long value) throws Exception {
return (value <= 0);
}
});
env.execute()
数据的传输是有 buffer 的,可以设置 buffer 的超时时间,buffer 满了或超时才会发出去
env.generateSequence(1,10).map(new MyMapper()).setBufferTimeout(timeoutMillis);
DataStream 提供一些方法用于将数据输出
writeAsText(String path)
writeAsCsv(String path)
print()
writeUsingOutputFormat(OutputFormat<T> format)
writeToSocket(String hostName, int port, SerializationSchema<T> schema)
DataStream 也提供 addSink 函数添加 connectors(预定义或自定义的)
stream.addSink(new FlinkKafkaProducer011<String>("localhost:9092", "my-topic", new SimpleStringSchema()))
stream.addSink(new FlinkKinesisProducer<>(new SimpleStringSchema(), producerConfig))
stream.addSink(new BucketingSink<String>("/base/path")) // 可用于 HDFS
stream.addSink(new RMQSink<String>(connectionConfig, "queueName", new SimpleStringSchema()))
streamExecEnv.addSink(new NiFiSink<>(clientConfig, new NiFiDataPacketBuilder<T>() {...}));
CassandraSink.addSink(result)
.setQuery("INSERT INTO example.wordcount(word, count) values (?, ?);")
.setHost("127.0.0.1")
.build();
stream.addSink(new ElasticsearchSink<>(config, transportAddresses, new ElasticsearchSinkFunction<String>() {
public IndexRequest createIndexRequest(String element) {
Map<String, String> json = new HashMap<>();
json.put("data", element);
return Requests.indexRequest()
.index("my-index")
.type("my-type")
.source(json);
}
@Override
public void process(String element, RuntimeContext ctx, RequestIndexer indexer) {
indexer.add(createIndexRequest(element));
}
}));
更多信息查看 https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/datastream_api.html
DataStream 的 Join
Window Join(同一个窗口的两个 Stream 的数据两两传到 join 函数,比如两个窗口各 10 个数据,join 函数执行 100 次)
stream.join(otherStream)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(<WindowAssigner>)
.apply(<JoinFunction>)
Interval Join
DataStream<Integer> orangeStream = ...
DataStream<Integer> greenStream = ...
// 针对 orangeStream 的每个数据 a,都会寻找 greenStream 内时间戳和 a 的差在(-2,1)范围内的数据
// 将这些数据分别和 a 组合传给 join 函数
orangeStream
.keyBy(<KeySelector>)
.intervalJoin(greenStream.keyBy(<KeySelector>))
.between(Time.milliseconds(-2), Time.milliseconds(1))
.process (new ProcessJoinFunction<Integer, Integer, String(){
@Override
public void processElement(Integer left, Integer right, Context ctx, Collector<String> out) {
out.collect(first + "," + second);
}
});
https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/stream/operators/joining.html
Process Function
低阶函数,可以对数据进行操作处理
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction.Context;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction.OnTimerContext;
import org.apache.flink.util.Collector;
DataStream<Tuple2<String, String>> stream = ...;
DataStream<Tuple2<String, Long>> result = stream
.keyBy(0)
.process(new CountWithTimeoutFunction());
public class CountWithTimestamp {
public String key;
public long count;
public long lastModified;
}
public class CountWithTimeoutFunction
extends KeyedProcessFunction<Tuple, Tuple2<String, String>, Tuple2<String, Long>> {
private ValueState<CountWithTimestamp> state;
@Override
public void open(Configuration parameters) throws Exception {
state = getRuntimeContext().getState(new ValueStateDescriptor<>("myState", CountWithTimestamp.class));
}
@Override
public void processElement(
Tuple2<String, String> value,
Context ctx,
Collector<Tuple2<String, Long>> out) throws Exception {
CountWithTimestamp current = state.value();
if (current == null) {
current = new CountWithTimestamp();
current.key = value.f0;
}
current.count++;
current.lastModified = ctx.timestamp();
state.update(current);
// schedule the next timer 60 seconds from the current event time
ctx.timerService().registerEventTimeTimer(current.lastModified + 60000);
}
@Override
public void onTimer(
long timestamp,
OnTimerContext ctx,
Collector<Tuple2<String, Long>> out) throws Exception {
CountWithTimestamp result = state.value();
if (timestamp == result.lastModified + 60000) {
out.collect(new Tuple2<String, Long>(result.key, result.count));
}
}
}
异步 IO
class AsyncDatabaseRequest extends RichAsyncFunction<String, Tuple2<String, String>> {
private transient DatabaseClient client;
@Override
public void open(Configuration parameters) throws Exception {
client = new DatabaseClient(host, post, credentials);
}
@Override
public void close() throws Exception {
client.close();
}
@Override
public void asyncInvoke(String key, final ResultFuture<Tuple2<String, String>> resultFuture) throws Exception {
// issue the asynchronous request, receive a future for result
final Future<String> result = client.query(key);
// set the callback to be executed once the request by the client is complete
// the callback simply forwards the result to the result future
CompletableFuture.supplyAsync(new Supplier<String>() {
@Override
public String get() {
try {
return result.get();
} catch (InterruptedException | ExecutionException e) {
// Normally handled explicitly.
return null;
}
}
}).thenAccept( (String dbResult) -> {
resultFuture.complete(Collections.singleton(new Tuple2<>(key, dbResult)));
});
}
}
DataStream<String> stream = ...;
DataStream<Tuple2<String, String>> resultStream =
AsyncDataStream.unorderedWait(stream, new AsyncDatabaseRequest(), 1000, TimeUnit.MILLISECONDS, 100);
https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/stream/operators/asyncio.html
DataSet 的 Sources、Transformation、Sinks
ExecutionEnvironment 提供一些函数用以获取数据源
readTextFile(String filePath)
readTextFileWithValue(String filePath)
readCsvFile(String filePath)
readFileOfPrimitives(String filePath, Class<X> typeClass)
readFileOfPrimitives(String filePath, String delimiter, Class<X> typeClass)
fromCollection(Collection<X> data)
fromCollection(Iterator<X> data, Class<X> type)
fromElements(X... data)
fromParallelCollection(SplittableIterator<X> iterator, Class<X> type)
generateSequence(long from, long to)
readFile(FileInputFormat<X> inputFormat, String filePath)
// createInput 是一个通用函数,可以通过实现 InputFormat 类接入各种数据源
createInput(InputFormat<X, ?> inputFormat)
DataSet<Tuple2<String, Integer> dbData =
env.createInput(
JDBCInputFormat.buildJDBCInputFormat()
.setDrivername("org.apache.derby.jdbc.EmbeddedDriver")
.setDBUrl("jdbc:derby:memory:persons")
.setQuery("select name, age from persons")
.setRowTypeInfo(new RowTypeInfo(BasicTypeInfo.STRING_TYPE_INFO, BasicTypeInfo.INT_TYPE_INFO))
.finish()
);
DataSet 支持的 Transformation 主要有
map
flatMap
mapPartition
filter
reduce
reduceGroup
aggregate
distinct
join
leftOuterJoin
coGroup
cross
union
rebalance
partitionByHash
partitionByRange
partitionCustom
sortPartition
first
groupBy
project
DataSet 提供的 Sink 函数主要有
writeAsText(String filePath)
writeAsFormattedText(String filePath, TextFormatter<T> formatter)
writeAsCsv(String filePath)
print()
write(FileOutputFormat<T> outputFormat, String filePath)
// output 是通用函数,通过实现 outputFormat 可以将数据写入不同的 Sink
output(OutputFormat<T> outputFormat)
myResult.output(
JDBCOutputFormat.buildJDBCOutputFormat()
.setDrivername("org.apache.derby.jdbc.EmbeddedDriver")
.setDBUrl("jdbc:derby:memory:persons")
.setQuery("insert into persons (name, age, height) values (?,?,?)")
.finish()
);
Iteration
// 初始数据为 0,最多迭代 10000 次
IterativeDataSet<Integer> initial = env.fromElements(0).iterate(10000);
DataSet<Integer> iteration = initial.map(new MapFunction<Integer, Integer>() {
@Override
public Integer map(Integer i) throws Exception {
double x = Math.random();
double y = Math.random();
return i + ((x * x + y * y < 1) ? 1 : 0);
}
});
// 当 iteration 为空或迭代次数达到最大时停止迭代,这里 iteration 永远有数据,所以只能等最大迭代次数
DataSet<Integer> count = initial.closeWith(iteration);
// 跳出迭代后的操作
count.map(new MapFunction<Integer, Double>() {
@Override
public Double map(Integer count) throws Exception {
return count / (double) 10000 * 4;
}
}).print();
env.execute("Iterative Pi Example");
https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/batch/
Table API & SQL
Table API 和 SQL 把 DataStream 和 DataSet 当成表,可以用 SQL 执行,可以统一 stream 和 batch 的操作
Flink SQL 基于?Apache Calcite 实现
Table API 和 SQL 有两个不同的 Planner:Old-Planner 和 Blink-Planner
两者的一些区别参考:
https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/table/common.html#main-differences-between-the-two-planners
https://flink.apache.org/news/2019/02/13/unified-batch-streaming-blink.html
Table API 和 SQL 支持 Java、Scala、Python
使用 Python 需要先按照 PyFlink,要求 Python 版本是 3.5,3.6,3.7
python -m pip install apache-flink
Flink 和 Blink 创建 TableEnvironment 的方式
// **********************
// FLINK STREAMING QUERY
// **********************
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.java.StreamTableEnvironment;
EnvironmentSettings fsSettings = EnvironmentSettings.newInstance().useOldPlanner().inStreamingMode().build();
StreamExecutionEnvironment fsEnv = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment fsTableEnv = StreamTableEnvironment.create(fsEnv, fsSettings);
// or TableEnvironment fsTableEnv = TableEnvironment.create(fsSettings);
// ******************
// FLINK BATCH QUERY
// ******************
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.table.api.java.BatchTableEnvironment;
ExecutionEnvironment fbEnv = ExecutionEnvironment.getExecutionEnvironment();
BatchTableEnvironment fbTableEnv = BatchTableEnvironment.create(fbEnv);
// **********************
// BLINK STREAMING QUERY
// **********************
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.java.StreamTableEnvironment;
StreamExecutionEnvironment bsEnv = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings bsSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment bsTableEnv = StreamTableEnvironment.create(bsEnv, bsSettings);
// or TableEnvironment bsTableEnv = TableEnvironment.create(bsSettings);
// ******************
// BLINK BATCH QUERY
// ******************
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
EnvironmentSettings bbSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inBatchMode().build();
TableEnvironment bbTableEnv = TableEnvironment.create(bbSettings);
Table API 和 SQL 的基本用法
// create a TableEnvironment for specific planner batch or streaming
TableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section
// create a Table
tableEnv.connect(...).createTemporaryTable("table1");
// register an output Table
tableEnv.connect(...).createTemporaryTable("outputTable");
// create a Table object from a Table API query
Table tapiResult = tableEnv.from("table1").select(...);
// create a Table object from a SQL query
Table sqlResult = tableEnv.sqlQuery("SELECT ... FROM table1 ... ");
// emit a Table API result Table to a TableSink, same for SQL result
tapiResult.insertInto("outputTable");
// execute
tableEnv.execute("java_job");
创建表
// 为一个经过 SQL 生成的 Table 类创建表名
Table projTable = tableEnv.from("X").select(...);
tableEnv.createTemporaryView("projectedTable", projTable);
// 链接外部数据系统(数据库,文件系统,消息队列,等等)并创建表名
tableEnvironment
.connect(...)
.withFormat(...)
.withSchema(...)
.inAppendMode()
.createTemporaryTable("MyTable")
创建表的时候除了表名,还可以指定 catalog 和 database
Table table = ...;
// register the view named 'exampleView' in the catalog named 'custom_catalog'
// in the database named 'custom_database'
tableEnv.createTemporaryView("exampleView", table);
// register the view named 'exampleView' in the catalog named 'custom_catalog'
// in the database named 'other_database'
tableEnv.createTemporaryView("other_database.exampleView", table);
// register the view named 'View' in the catalog named 'custom_catalog' in the
// database named 'custom_database'. 'View' is a reserved keyword and must be escaped.
tableEnv.createTemporaryView("`View`", table);
// register the view named 'example.View' in the catalog named 'custom_catalog'
// in the database named 'custom_database'
tableEnv.createTemporaryView("`example.View`", table);
// register the view named 'exampleView' in the catalog named 'other_catalog'
// in the database named 'other_database'
tableEnv.createTemporaryView("other_catalog.other_database.exampleView", table);
Table API 查询表
// get a TableEnvironment
TableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section
// register Orders table
// scan registered Orders table
Table orders = tableEnv.from("Orders");
// compute revenue for all customers from France
Table revenue = orders
.filter("cCountry === 'FRANCE'")
.groupBy("cID, cName")
.select("cID, cName, revenue.sum AS revSum");
// emit or convert Table
// execute query
SQL 查询表
// get a TableEnvironment
TableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section
// register Orders table
// compute revenue for all customers from France
Table revenue = tableEnv.sqlQuery(
"SELECT cID, cName, SUM(revenue) AS revSum " +
"FROM Orders " +
"WHERE cCountry = 'FRANCE' " +
"GROUP BY cID, cName"
);
// emit or convert Table
// execute query
// get a TableEnvironment
TableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section
// register "Orders" table
// register "RevenueFrance" output table
// compute revenue for all customers from France and emit to "RevenueFrance"
tableEnv.sqlUpdate(
"INSERT INTO RevenueFrance " +
"SELECT cID, cName, SUM(revenue) AS revSum " +
"FROM Orders " +
"WHERE cCountry = 'FRANCE' " +
"GROUP BY cID, cName"
);
// execute query
写入数据表
// create an output Table
final Schema schema = new Schema()
.field("a", DataTypes.INT())
.field("b", DataTypes.STRING())
.field("c", DataTypes.LONG());
tableEnv.connect(new FileSystem("/path/to/file"))
.withFormat(new Csv().fieldDelimiter('|').deriveSchema())
.withSchema(schema)
.createTemporaryTable("CsvSinkTable");
// compute a result Table using Table API operators and/or SQL queries
Table result = ...
// emit the result Table to the registered TableSink
result.insertInto("CsvSinkTable");
Table result = ...
// create TableSink
TableSink<Row> sink = ...
// register TableSink
tableEnv.registerTableSink(
"outputTable", // table name
new String[]{...}, // field names
new TypeInformation[]{...}, // field types
sink); // table sink
// emit result Table via a TableSink
result.insertInto("outputTable");
将 DataStream 和 DataSet 转换为表
DataStream<Tuple2<Long, String>> stream = ...
// register the DataStream as View "myTable" with fields "f0", "f1"
tableEnv.createTemporaryView("myTable", stream);
// register the DataStream as View "myTable2" with fields "myLong", "myString"
tableEnv.createTemporaryView("myTable2", stream, "myLong, myString");
DataStream<Tuple2<Long, String>> stream = ...
// Convert the DataStream into a Table with default fields "f0", "f1"
Table table1 = tableEnv.fromDataStream(stream);
// Convert the DataStream into a Table with fields "myLong", "myString"
Table table2 = tableEnv.fromDataStream(stream, "myLong, myString");
// convert the DataStream into a Table with swapped fields and field names "myString" and "myLong"
Table table3 = tableEnv.fromDataStream(stream, "f1 as myString, f0 as myLong");
// Person is a POJO with fields "name" and "age"
DataStream<Person> stream = ...
// convert DataStream into Table with default field names "age", "name" (fields are ordered by name!)
Table table = tableEnv.fromDataStream(stream);
// convert DataStream into Table with renamed fields "myAge", "myName" (name-based)
Table table = tableEnv.fromDataStream(stream, "age as myAge, name as myName");
// convert DataStream into Table with projected field "name" (name-based)
Table table = tableEnv.fromDataStream(stream, "name");
// convert DataStream into Table with projected and renamed field "myName" (name-based)
Table table = tableEnv.fromDataStream(stream, "name as myName");
// DataStream of Row with two fields "name" and "age" specified in `RowTypeInfo`
DataStream<Row> stream = ...
// convert DataStream into Table with default field names "name", "age"
Table table = tableEnv.fromDataStream(stream);
// convert DataStream into Table with renamed field names "myName", "myAge" (position-based)
Table table = tableEnv.fromDataStream(stream, "myName, myAge");
// convert DataStream into Table with renamed fields "myName", "myAge" (name-based)
Table table = tableEnv.fromDataStream(stream, "name as myName, age as myAge");
// convert DataStream into Table with projected field "name" (name-based)
Table table = tableEnv.fromDataStream(stream, "name");
// convert DataStream into Table with projected and renamed field "myName" (name-based)
Table table = tableEnv.fromDataStream(stream, "name as myName");
将表转换为 DataStream 和 DataSet
// convert the Table into an append DataStream of Row by specifying the class
DataStream<Row> dsRow = tableEnv.toAppendStream(table, Row.class);
// convert the Table into an append DataStream of Tuple2<String, Integer>
// via a TypeInformation
TupleTypeInfo<Tuple2<String, Integer>> tupleType = new TupleTypeInfo<>(Types.STRING(), Types.INT());
DataStream<Tuple2<String, Integer>> dsTuple = tableEnv.toAppendStream(table, tupleType);
// convert the Table into a retract DataStream of Row.
// A retract stream of type X is a DataStream<Tuple2<Boolean, X>>.
// The boolean field indicates the type of the change.
// True is INSERT, false is DELETE.
DataStream<Tuple2<Boolean, Row>> retractStream = tableEnv.toRetractStream(table, Row.class);
// convert the Table into a DataSet of Row by specifying a class
DataSet<Row> dsRow = tableEnv.toDataSet(table, Row.class);
// convert the Table into a DataSet of Tuple2<String, Integer> via a TypeInformation
TupleTypeInfo<Tuple2<String, Integer>> tupleType = new TupleTypeInfo<>(Types.STRING(), Types.INT());
DataSet<Tuple2<String, Integer>> dsTuple = tableEnv.toDataSet(table, tupleType);
Connector:可以通过 connector 以 table 的方式读写外部系统(文件系统,数据库,消息队列,等等)
https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/table/connect.html
tableEnvironment
.connect(
new Kafka()
.version("0.10")
.topic("test-input")
.startFromEarliest()
// .startFromLatest()
// .startFromSpecificOffsets(...)
.property("zookeeper.connect", "localhost:2181")
.property("bootstrap.servers", "localhost:9092")
// .sinkPartitionerFixed()
// .sinkPartitionerRoundRobin()
)
.withFormat(
new Avro()
.avroSchema(
"{" +
" \"namespace\": \"org.myorganization\"," +
" \"type\": \"record\"," +
" \"name\": \"UserMessage\"," +
" \"fields\": [" +
" {\"name\": \"timestamp\", \"type\": \"string\"}," +
" {\"name\": \"user\", \"type\": \"long\"}," +
" {\"name\": \"message\", \"type\": [\"string\", \"null\"]}" +
" ]" +
"}"
)
)
.withSchema(
new Schema()
.field("rowtime", DataTypes.TIMESTAMP(3))
.rowtime(new Rowtime() // optional: declares this field as a event-time attribute
// also can declares this field as a processing-time attribute via .proctime()
.timestampsFromField("timestamp")
.watermarksPeriodicBounded(60000) // also can be .watermarksPeriodicAscending()
// or .watermarksFromSource()
)
.field("user", DataTypes.BIGINT())
.field("message", DataTypes.STRING())
)
.createTemporaryTable("MyUserTable");
.connect(
new FileSystem()
.path("file:///path/to/whatever") // required: path to a file or directory
)
.withFormat( // required: file system connector requires to specify a format,
... // currently only OldCsv format is supported.
) // Please refer to old CSV format part of Table Formats section for more details.
.connect(
new Elasticsearch()
.version("6") // required: valid connector versions are "6"
.host("localhost", 9200, "http") // required: one or more Elasticsearch hosts to connect to
.index("MyUsers") // required: Elasticsearch index
.documentType("user") // required: Elasticsearch document type
.keyDelimiter("$") // optional: delimiter for composite keys ("_" by default)
// e.g., "$" would result in IDs "KEY1$KEY2$KEY3"
.keyNullLiteral("n/a") // optional: representation for null fields in keys ("null" by default)
// optional: failure handling strategy in case a request to Elasticsearch fails (fail by default)
.failureHandlerFail() // optional: throws an exception if a request fails and causes a job failure
.failureHandlerIgnore() // or ignores failures and drops the request
.failureHandlerRetryRejected() // or re-adds requests that have failed due to queue capacity saturation
.failureHandlerCustom(...) // or custom failure handling with a ActionRequestFailureHandler subclass
// optional: configure how to buffer elements before sending them in bulk to the cluster for efficiency
.disableFlushOnCheckpoint() // optional: disables flushing on checkpoint (see notes below!)
.bulkFlushMaxActions(42) // optional: maximum number of actions to buffer for each bulk request
.bulkFlushMaxSize("42 mb") // optional: maximum size of buffered actions in bytes per bulk request
// (only MB granularity is supported)
.bulkFlushInterval(60000L) // optional: bulk flush interval (in milliseconds)
.bulkFlushBackoffConstant() // optional: use a constant backoff type
.bulkFlushBackoffExponential() // or use an exponential backoff type
.bulkFlushBackoffMaxRetries(3) // optional: maximum number of retries
.bulkFlushBackoffDelay(30000L) // optional: delay between each backoff attempt (in milliseconds)
// optional: connection properties to be used during REST communication to Elasticsearch
.connectionMaxRetryTimeout(3) // optional: maximum timeout (in milliseconds) between retries
.connectionPathPrefix("/v1") // optional: prefix string to be added to every REST communication
)
.withFormat( // required: Elasticsearch connector requires to specify a format,
... // currently only Json format is supported.
// Please refer to Table Formats section for more details.
)
.connect(
new HBase()
.version("1.4.3") // required: currently only support "1.4.3"
.tableName("hbase_table_name") // required: HBase table name
.zookeeperQuorum("localhost:2181") // required: HBase Zookeeper quorum configuration
.zookeeperNodeParent("/test") // optional: the root dir in Zookeeper for HBase cluster.
// The default value is "/hbase".
.writeBufferFlushMaxSize("10mb") // optional: writing option, determines how many size in memory of buffered
// rows to insert per round trip. This can help performance on writing to JDBC
// database. The default value is "2mb".
.writeBufferFlushMaxRows(1000) // optional: writing option, determines how many rows to insert per round trip.
// This can help performance on writing to JDBC database. No default value,
// i.e. the default flushing is not depends on the number of buffered rows.
.writeBufferFlushInterval("2s") // optional: writing option, sets a flush interval flushing buffered requesting
// if the interval passes, in milliseconds. Default value is "0s", which means
// no asynchronous flush thread will be scheduled.
)
// JDBC 似乎只支持 SQL 的方式导入,不支持 API 的方式导入
CREATE TABLE MyUserTable (
...
) WITH (
'connector.type' = 'jdbc', -- required: specify this table type is jdbc
'connector.url' = 'jdbc:mysql://localhost:3306/flink-test', -- required: JDBC DB url
'connector.table' = 'jdbc_table_name', -- required: jdbc table name
'connector.driver' = 'com.mysql.jdbc.Driver', -- optional: the class name of the JDBC driver to use to connect to this URL.
-- If not set, it will automatically be derived from the URL.
'connector.username' = 'name', -- optional: jdbc user name and password
'connector.password' = 'password',
-- scan options, optional, used when reading from table
-- These options must all be specified if any of them is specified. In addition, partition.num must be specified. They
-- describe how to partition the table when reading in parallel from multiple tasks. partition.column must be a numeric,
-- date, or timestamp column from the table in question. Notice that lowerBound and upperBound are just used to decide
-- the partition stride, not for filtering the rows in table. So all rows in the table will be partitioned and returned.
-- This option applies only to reading.
'connector.read.partition.column' = 'column_name', -- optional, name of the column used for partitioning the input.
'connector.read.partition.num' = '50', -- optional, the number of partitions.
'connector.read.partition.lower-bound' = '500', -- optional, the smallest value of the first partition.
'connector.read.partition.upper-bound' = '1000', -- optional, the largest value of the last partition.
'connector.read.fetch-size' = '100', -- optional, Gives the reader a hint as to the number of rows that should be fetched
-- from the database when reading per round trip. If the value specified is zero, then
-- the hint is ignored. The default value is zero.
-- lookup options, optional, used in temporary join
'connector.lookup.cache.max-rows' = '5000', -- optional, max number of rows of lookup cache, over this value, the oldest rows will
-- be eliminated. "cache.max-rows" and "cache.ttl" options must all be specified if any
-- of them is specified. Cache is not enabled as default.
'connector.lookup.cache.ttl' = '10s', -- optional, the max time to live for each rows in lookup cache, over this time, the oldest rows
-- will be expired. "cache.max-rows" and "cache.ttl" options must all be specified if any of
-- them is specified. Cache is not enabled as default.
'connector.lookup.max-retries' = '3', -- optional, max retry times if lookup database failed
-- sink options, optional, used when writing into table
'connector.write.flush.max-rows' = '5000', -- optional, flush max size (includes all append, upsert and delete records),
-- over this number of records, will flush data. The default value is "5000".
'connector.write.flush.interval' = '2s', -- optional, flush interval mills, over this time, asynchronous threads will flush data.
-- The default value is "0s", which means no asynchronous flush thread will be scheduled.
'connector.write.max-retries' = '3' -- optional, max retry times if writing records to database failed
)
.connect(...)
.inAppendMode()
// inAppendMode : a dynamic table and an external connector only exchange INSERT messages.
// inUpsertMode : a dynamic table and an external connector exchange UPSERT and DELETE messages.
// inRetractMode : a dynamic table and an external connector exchange ADD and RETRACT messages.
Table Format
.withFormat(
new Csv()
.withFormat(
new Json()
.withFormat(
new Avro()
explain
Table table1 = tEnv.fromDataStream(stream1, "count, word");
Table table2 = tEnv.fromDataStream(stream2, "count, word");
Table table = table1
.where("LIKE(word, 'F%')")
.unionAll(table2);
String explanation = tEnv.explain(table);
System.out.println(explanation);
== Abstract Syntax Tree ==
LogicalUnion(all=[true])
LogicalFilter(condition=[LIKE($1, _UTF-16LE'F%')])
FlinkLogicalDataStreamScan(id=[1], fields=[count, word])
FlinkLogicalDataStreamScan(id=[2], fields=[count, word])
== Optimized Logical Plan ==
DataStreamUnion(all=[true], union all=[count, word])
DataStreamCalc(select=[count, word], where=[LIKE(word, _UTF-16LE'F%')])
DataStreamScan(id=[1], fields=[count, word])
DataStreamScan(id=[2], fields=[count, word])
== Physical Execution Plan ==
Stage 1 : Data Source
content : collect elements with CollectionInputFormat
Stage 2 : Data Source
content : collect elements with CollectionInputFormat
Stage 3 : Operator
content : from: (count, word)
ship_strategy : REBALANCE
Stage 4 : Operator
content : where: (LIKE(word, _UTF-16LE'F%')), select: (count, word)
ship_strategy : FORWARD
Stage 5 : Operator
content : from: (count, word)
ship_strategy : REBALANCE
Table & SQL 里处理 Event-Time 和 Process-Time
https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/table/streaming/time_attributes.html
Joins in Continuous Queries
https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/table/streaming/joins.html
Data Type
https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/table/types.html
Table API & SQL
https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/table/tableApi.html
https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/table/sql/
SQL:Detecting Patterns in Tables
# 将 MyTable 表按 userid 分类,再按 proctime 排序
# 如果连续三条数据的 name 分别是 a b c,就将这三条数据的 id 分别作为 aid,bid,cid 输出
SELECT T.aid, T.bid, T.cid
FROM MyTable
MATCH_RECOGNIZE (
PARTITION BY userid
ORDER BY proctime
MEASURES
A.id AS aid,
B.id AS bid,
C.id AS cid
PATTERN (A B C)
DEFINE
A AS name = 'a',
B AS name = 'b',
C AS name = 'c'
) AS T
这个 Detecting Patterns 的功能看起来挺强的
https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/table/streaming/match_recognize.html
SQL Function
https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/table/functions/
Library CEP
Complex Event Processing (CEP) library implemented on top of Flink. It allows you to detect event patterns in an endless stream of events, giving you the opportunity to get hold of what’s important in your data.
// 假设有一条数据的 id 是 42
// 并且接下来相连的一条数据的 volume 大于等于 10
// 并且后面还有一条 name 是 end 的数据(不需要和第二条相连)
// 把满足这个 Pattern 的数据找出来
DataStream<Event> input = ...
Pattern<Event, ?> pattern = Pattern.<Event>begin("start").where(
new SimpleCondition<Event>() {
@Override
public boolean filter(Event event) {
return event.getId() == 42;
}
}
).next("middle").subtype(SubEvent.class).where(
new SimpleCondition<SubEvent>() {
@Override
public boolean filter(SubEvent subEvent) {
return subEvent.getVolume() >= 10.0;
}
}
).followedBy("end").where(
new SimpleCondition<Event>() {
@Override
public boolean filter(Event event) {
return event.getName().equals("end");
}
}
);
PatternStream<Event> patternStream = CEP.pattern(input, pattern);
DataStream<Alert> result = patternStream.process(
new PatternProcessFunction<Event, Alert>() {
@Override
public void processMatch(
Map<String, List<Event>> pattern,
Context ctx,
Collector<Alert> out) throws Exception {
out.collect(createAlertFrom(pattern));
}
});
指定数据出现的次数
Pattern<Event, ?> start = Pattern.<Event>begin("start").where(...)
// expecting 4 occurrences
start.times(4);
// expecting 0 or 4 occurrences
start.times(4).optional();
// expecting 2, 3 or 4 occurrences
start.times(2, 4);
// expecting 2, 3 or 4 occurrences and repeating as many as possible
start.times(2, 4).greedy();
// expecting 0, 2, 3 or 4 occurrences
start.times(2, 4).optional();
// expecting 0, 2, 3 or 4 occurrences and repeating as many as possible
start.times(2, 4).optional().greedy();
// expecting 1 or more occurrences
start.oneOrMore();
// expecting 1 or more occurrences and repeating as many as possible
start.oneOrMore().greedy();
// expecting 0 or more occurrences
start.oneOrMore().optional();
// expecting 0 or more occurrences and repeating as many as possible
start.oneOrMore().optional().greedy();
// expecting 2 or more occurrences
start.timesOrMore(2);
// expecting 2 or more occurrences and repeating as many as possible
start.timesOrMore(2).greedy();
// expecting 0, 2 or more occurrences and repeating as many as possible
start.timesOrMore(2).optional().greedy();
指定条件
// Iterative Conditions
.where(new IterativeCondition<SubEvent>() {
@Override
public boolean filter(SubEvent value, Context<SubEvent> ctx) throws Exception {
if (!value.getName().startsWith("foo")) {
return false;
}
double sum = value.getPrice();
for (Event event : ctx.getEventsForPattern("middle")) {
sum += event.getPrice();
}
return Double.compare(sum, 5.0) < 0;
}
});
// Simple Conditions
.where(new SimpleCondition<Event>() {
@Override
public boolean filter(Event value) {
return value.getName().startsWith("foo");
}
});
// Combining Conditions
.where(new SimpleCondition<Event>() {
@Override
public boolean filter(Event value) {
return ... // some condition
}
}).or(new SimpleCondition<Event>() {
@Override
public boolean filter(Event value) {
return ... // or condition
}
});
// Stop condition
.oneOrMore().until(new IterativeCondition<Event>() {
@Override
public boolean filter(Event value, Context ctx) throws Exception {
return ... // alternative condition
}
});
// Defines a subtype condition for the current pattern.
// An event can only match the pattern if it is of this subtype:
pattern.subtype(SubEvent.class);
组合
next() // 相连的下一条数据,比如(a,b,c),可以指定匹配(a,b),但不能指定匹配(a,c)
followedBy() // 在后面出现的数据,比如(a,b,c),可以指定匹配(a,b)或(a,c)都可以
followedByAny() // 在后面出现的所有满足要求的数据,比如(a,b,c,c),指定匹配(a,c)时
// 会返回两个满足条件的(a,c)组合,而 followedBy 只会返回一个
notNext() // 相连的下一条不能出现的数据
notFollowedBy() // 在后面不能出现的数据
next.within(Time.seconds(10)); // 指定时间范围
Groups of patterns
// strict contiguity
Pattern<Event, ?> strict = start.next(
Pattern.<Event>begin("next_start").where(...).followedBy("next_middle").where(...)
).times(3);
// relaxed contiguity
Pattern<Event, ?> relaxed = start.followedBy(
Pattern.<Event>begin("followedby_start").where(...).followedBy("followedby_middle").where(...)
).oneOrMore();
// non-deterministic relaxed contiguity
Pattern<Event, ?> nonDetermin = start.followedByAny(
Pattern.<Event>begin("followedbyany_start").where(...).followedBy("followedbyany_middle").where(...)
).optional();
一个数据有可能被多次命中匹配,可以设置如何处理
https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/libs/cep.html#after-match-skip-strategy
更多 CEP 信息参考
https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/libs/cep.html
Library Gelly
Gelly is a Graph API for Flink
https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/libs/gelly/