一、什么是Flink?
Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,提供支持流处理和批处理两种类型应用的功能。
二、Flink特点
1、现有的开源计算方案,会把流处理和批处理作为两种不同的应用类型:流处理一般需要支持低延迟、Exactly-Once保证,而批处理一般要支持高吞吐、高效处理
2、Flink是完全支持流处理,也就是说作为流处理看待时输入数据流是无界的;而批处理被作为一种特殊的流处理,只是它的输入数据流被定义为有界的。
技术特点:
1、流处理特性
支持高吞吐、低延迟、高性能的流处理
支持带有事件时间的窗口操作
支持有状态计算 的Exactly-Once语义
支持高度灵活的窗口操作,支持基于time、count、session,以及data-driver的窗口操作
支持具有Backpressure功能的持续六模型
支持基于轻量级分布式快照(Snapshot)实现的容错
支持迭代计算
支持程序自动优化:避免特点情况下Shuffle、排序等操作,中间结果有必要进行缓存
Flink在JVM内部实现了自己的内存管理
三、Flink技术栈
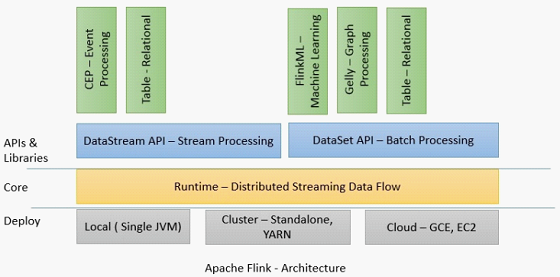
1、从部署上讲,Flink支持Local模式、集群模式(standalone模式或者Yarn模式)、云端部署(GCE、EC2)
2、Runtime是主要的数据处理引擎,它以JobGraph形式的API接收程序。JobGraph是一个简单的并行数据流,包含一些列的tasks,每个task包含了输入和输出(source和sink例外)。
3、DataStream API和DataSet API分别是流处理和批处理的应用程序接口,当程序编译时,生成JobGraph。编译完成后,根据API的不同,优化器(批或流)会生成不同的执行计划。根据不同的部署方式,优化后的JobGraph被提交给executors去执行。