版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
一、机器学习中的数据
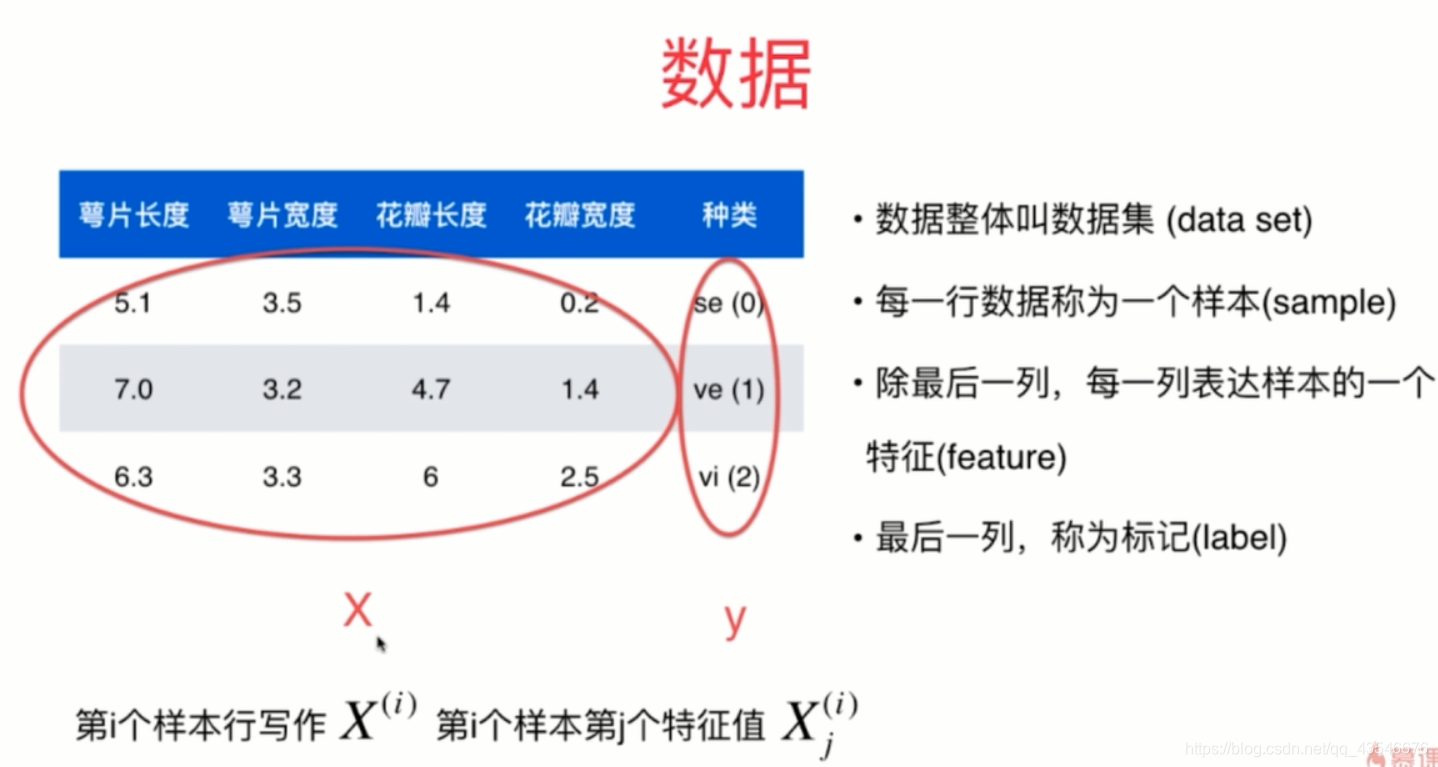
一般,数据都是上表的形式。每一行代表一个样本,每一列代表的是样本的一个特征,样本和特征构成矩阵X(大X), 最后一列是向量y(小y),是我们通过机器学习算法及数据所得到的结果。
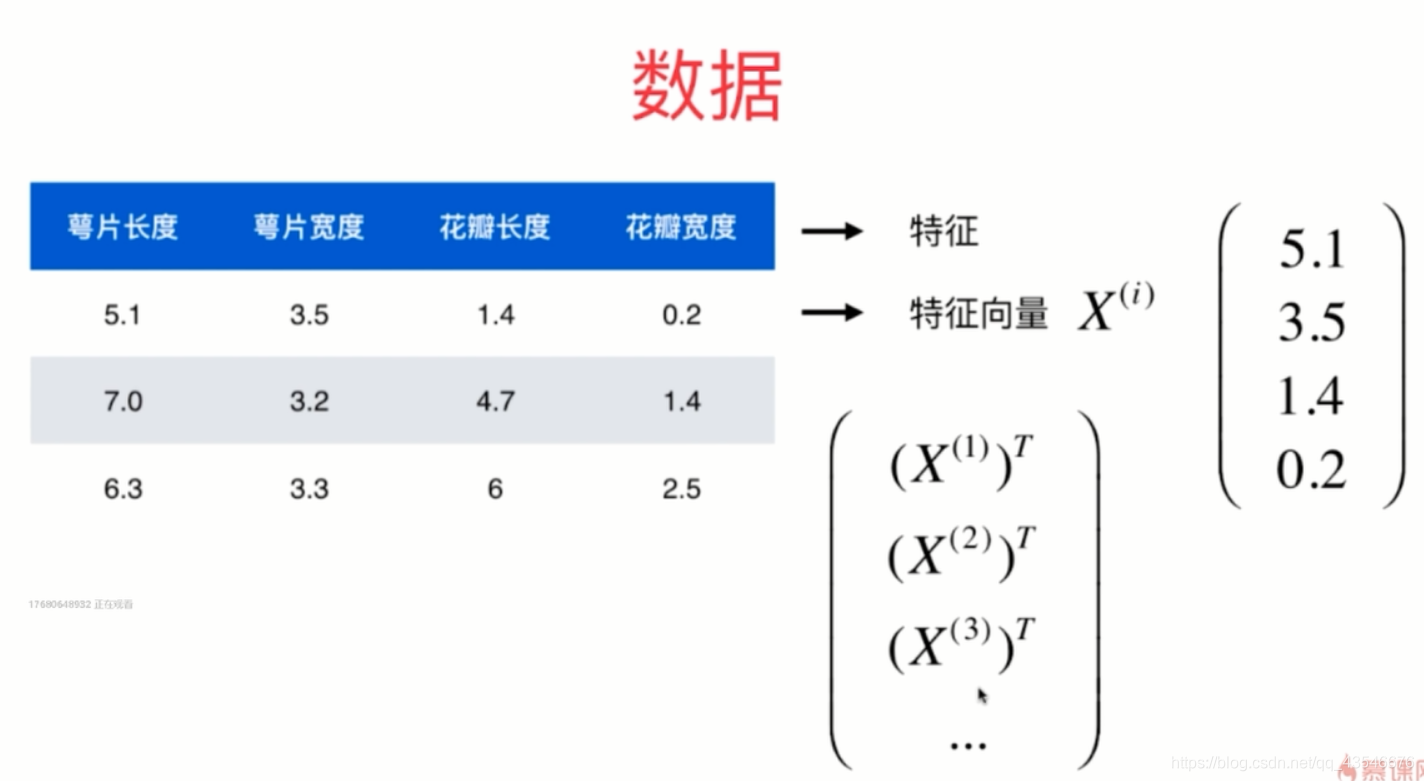
约定:
- 向量用小写的字母表示
- 矩阵用大写的字母表示
- 对于样本用X^(i)的形式表示
二、机器学习流程
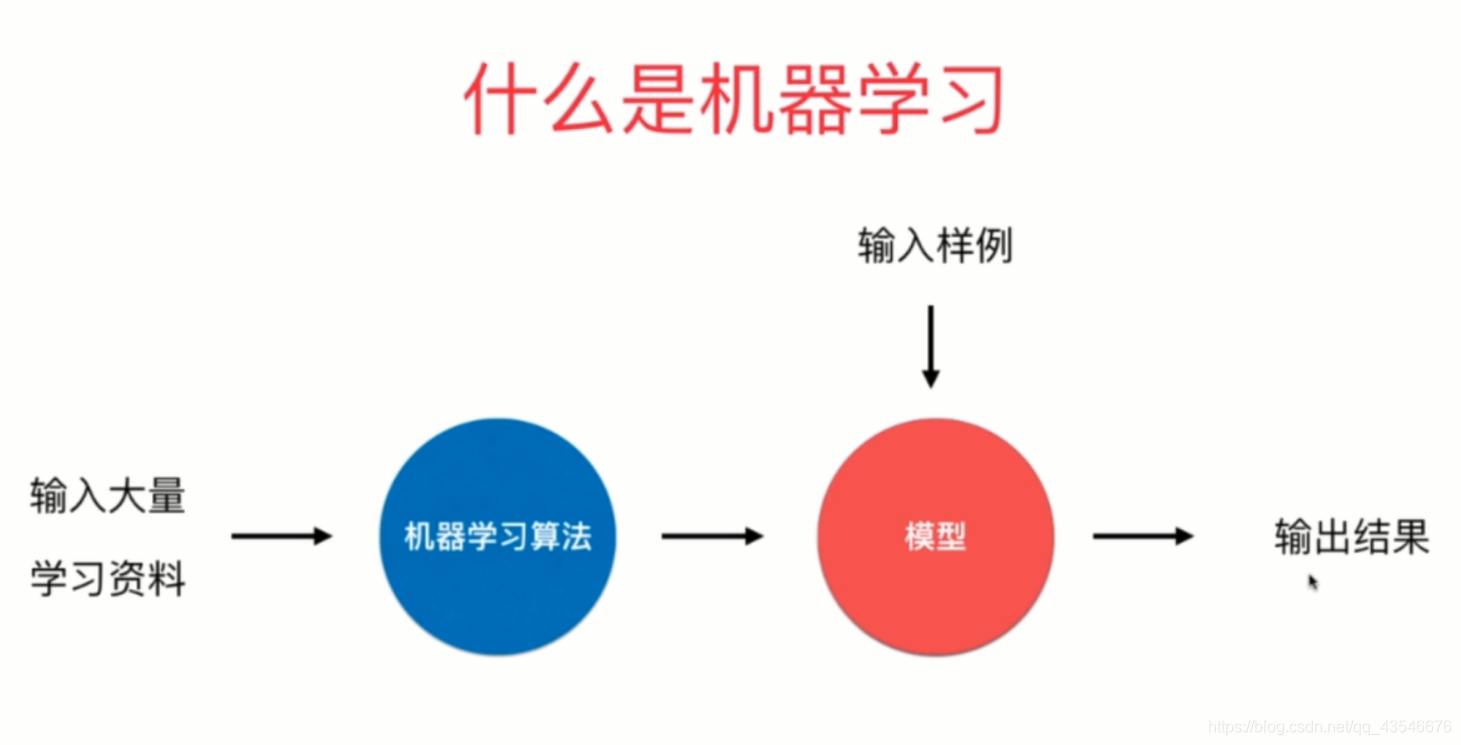
通过上图可以清晰的看到机器学习的抽象流程,显然的f(x)的确定是关键,也就是建立合适的模型是机器学习的关键;后面输出的结果可以为离散型的值和连续型值,前者为分类问题,后者为回归问题。
三 、机器学习分类
机器学习的分类并不是唯一的,不同的角度,分类不同:
纬度一:
(1)监督学习:既给出了样本矩阵X,又给出了lable向量y的数据集。主要处理分类和回归的问题。
(2)非监督学习:就是只给出了样本矩阵X,没有lable向量y的数据集。对没有“标记”的数据进行分类,俗称聚类分析。
eg:电商网站将用户分类。
非监督学习的意义:
- 可以对数据进行降维处理:特征提取(信用卡等级与体重无关)和特征压缩(PCA)
- 异常检测
(3)半监督学习:部分数据又lable向量y,部分没有。
通常先使用无监督学习手段对数据进行处理,之后使用监督学习做模型进行训练和预测。
(4)增强学习:训练-反馈-训练-反馈的循环。
比如围棋机器人
纬度二:
(1)批量学习:一次喂给模型大量数据。上面的监督学习,非监督学习大多数都是与批量学习交集。
优点:简单
缺点:不能够很快的适应新的环境。比如,股票预测不适合用批量学习
(2)在线学习:及时、不断的喂给模型数据。
优点:及时的反映型的环境变化
缺点:新的数据会有不好的数据,比如竞争对手故意的放出错误的数据。 通常,我们采用非监督学习来检测异常的数据。
纬度三:
(1)参数学习:对模型做一些假设,然后通过训练拿到参数,拿到参数之后就不再需要原有的数据集。
(2)非参数学习:不对模型做过多的假设。需要强调的是非参数学习不等于没参数,肯定会有参数。
所有算法的期望值都是相同的,但是对于具体问题,可能不同的算法效果不一样。