引言
本文介绍机器学习的一些基本概念。包括机器学习的主要任务,机器学习的分类等。
用到的数据
鸢尾花(IRIS)是比较常见的在我们学习机器学习时用到的数据。数据来源: http://archive.ics.uci.edu/ml/datasets/Iris
iris以鸢尾花的特征作为数据来源,常用在分类操作中。该数据集由3种不同类型的鸢尾花的各50个样本数据构成。其中的一个种类与另外两个种类是线性可分离的,后两个种类是非线性可分离的。
该数据集包含了4个属性:
- Sepal.Length(花萼长度),单位是cm;
- Sepal.Width(花萼宽度),单位是cm;
- Petal.Length(花瓣长度),单位是cm;
- Petal.Width(花瓣宽度),单位是cm;

种类:Iris Setosa(山鸢尾)、Iris Versicolour(杂色鸢尾),以及Iris Virginica(维吉尼亚鸢尾)。
这里我们抽出三份数据,最后一列是所属种类。一般我们会对这个类别进行数值化,这样好在机器学习中进行处理。
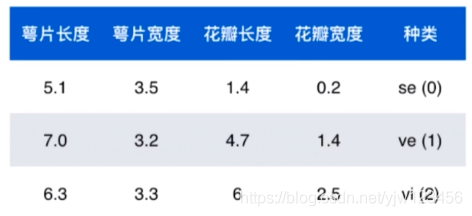
接下来介绍一些常见概念。
- 数据整体叫数据集(data set)
- 其中每一份(写成表格形式的话就是每一行)数据称为一个样本(sample)
- 除了最后一列(一般所属类别都放到最后一列),每一列都叫样本的一个特征(feature,有时也叫属性)
- 最后一列,称为标记(label)

我们把除标记列的特征都放到一个矩阵 中,每一份数据对应矩阵的一行,每个特征对应矩阵的一列。
标记列通常用 表示,这是一个向量,每一维度表示某份数据对应的类别。在数学上大写字母表示矩阵,小写字母表示向量。
第 个样本的标记写作 ,其中的括号可加可不加。

- 对于数据而言,萼片长度、萼片宽度等都叫特征;
- 每一行本身也组成了一个向量,通常叫特征向量 ;
通常向量都表示为列向量的形式。
因此矩阵 也可以表示为:
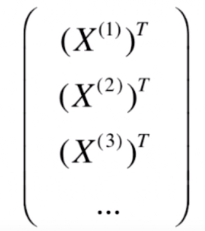
我们抽出这份数据的前两个特征(这样可以在直角坐标系中画出这些点):
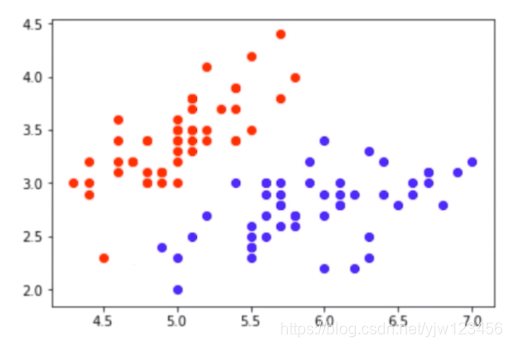
萼片长度作为横轴,萼片宽度作为纵轴。
每个样本都是这些特征所组成的空间中的一个点,这个空间我们叫称为特征空间(feature space)。
分类任务本质就是在特征空间上进行切分,以区分不同的类别。
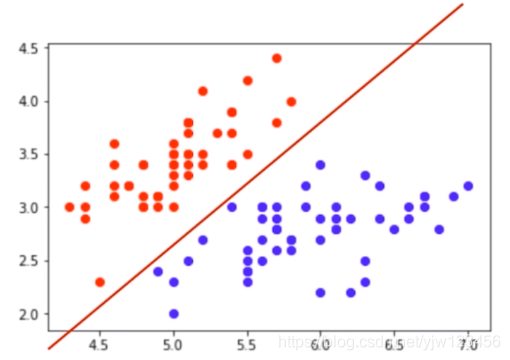
比如我们能在这个空间上画一条直线将这两个类别切分开来。切分之后,如果有了一个新的未知数据点,它出现在红线的上分,那么我们就可以说它属于红点类别。
这里我们用的是直线切分,真正在机器学习的时候我们也可以用曲线进行切分。
这里我们虽然用二维平面展示切分,其实在高维空间也是同理的。比如在三维空间,你可以想象是用平面去切分。
这里要注意的是,特征很多情况下是很抽象的,也就是人类不好理解。以手写数字识别为例

这是个数字5,是28*28的图像,在图像中就由一个个像素点构成的。最简单的方式就是把每个像素点都看成是一个特征。
也就是说每个图像有784个特征。
机器学习的主要任务
主要有两类:分类和回归。
分类
分类任务有很多,比如分辨一张图片里面的动物是猫还是狗。

或者是手写数字识别。

分类任务中根据要分类的类别数量可分为 二分类任务和多分类任务。
上面的分类猫狗就是二分类。
二分类任务看起来简单,但是生活中还是很常见的。比如判断邮件是否为垃圾邮件;银行判断发给客户信用卡有无风险。
而手写数字识别,要识别10个数字,属于多分类任务。
其实可以把很多复杂的问题转换为多分类任务问题。

比如训练机器玩2048这款游戏,给定现在的盘面,只需要机器判断上移、下移、左移、右移即可。
围棋也可以转换为多分类任务;无人驾驶可以想想也可以转换为分类任务,无非就是控制方向角度,油门。刹车。
但这里只是说可以解决这些问题,但不一定是接近这些问题的最佳方法。
有些算法只支持完成二分类的任务,但是多分类的任务可以转换成二分类的任务。
就是说通过转换,只支持二分类任务的算法通过转换可以变成支持多分类。
还有些算法本身支持多分类任务。
现在前沿的还有一种更高级的分类任务,可以把一张图片分到多个类别中。

比如这张图片,可以分类到女人、白色裙子、网球拍等等。综合这些信息,我们可以得到这张图片的语义。可以知道这张图片描述了一个什么样的场景。比如我们上面的类别可知,大概就是说一个穿白色裙子的女人在打网球。
回归
上面介绍的都是分类任务,和我们介绍的数据是相对应。还有一种数据是这样的。
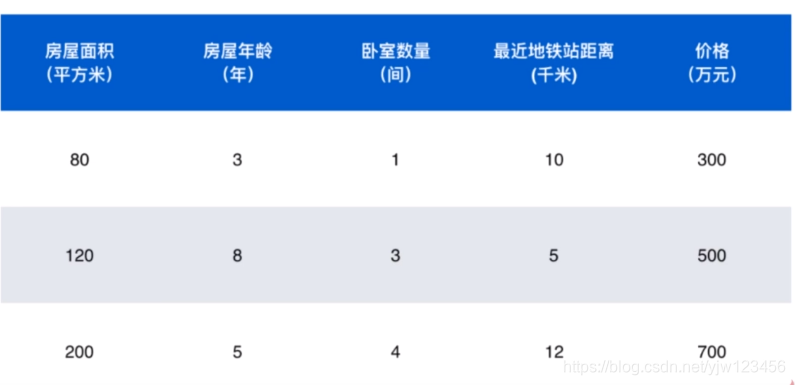
前面四个列是这份数据的特征,最后一列是这份数据的标签,是个价格。我们可以猜到这个任务需要预测房屋的价格。
而价格它不能简单的分为几个类别。毕竟如果你想卖房子,当然是想知道确切的数字。
对于这种连续数值的问题,就是回归任务要解决的问题。
回归任务的结果是一个连续数值,而不是一个类别。
回归任务也有很多常见的场景:
- 房屋价格
- 市场分析
- 学生成绩
- 股票价格
对于回归问题来说:
- 有些算法只能解决回归问题
- 有些算法只能解决分类问题
- 还有一些算法既能解决回归问题,又能解决分类问题(比如SVM)
还要注意的是,在某些情况下,回归任务可以简化为分类任务。

还是以无人驾驶为例,方向盘转动的角度这是一个连续的数值,上面在分类任务中,我们将它类别话,也就是将每一度看作一个类别。这样一来,我们将回归任务简化为分类任务。
还有在成绩预测中,现在很多学校都不给出具体成绩,只给出 等等这种,这里也是回归任务简化为分类任务的一个例子。
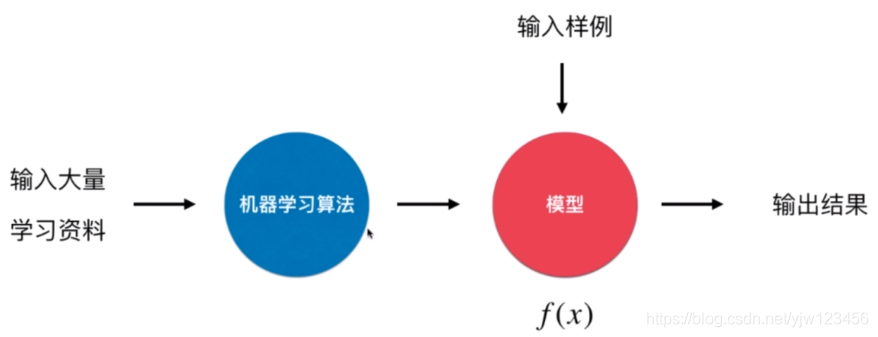
在机器学习的流程中,我们通过将训练数据喂给机器学习算法,可以学得一个模型 ,学好模型后,给定一个新的样例 ,输入到这个模型中,可以得到一个输出。
我们根据输出结果是否是连续的,可以分为回归和分类。
我们说机器学习能解决分类问题和回归问题,更加具体的说法应该是,监督学习能解决这两个问题。
机器学习还可以解决其他问题。
从解决问题的角度分类,机器学习可以解决分类问题和回归问题。如果从机器学习算法本身,整体上可以将机器学习算法分为监督学习、非监督学习、半监督学习以及增强学习。
机器学习算分分类
监督学习
训练数据有标记。

在区分猫狗任务中,仅仅给包含猫狗的照片是不够的,还是告诉机器哪些是狗,哪些是猫。

手写数字识别中也一样了,每份训练样本都会有对应的真实数字标记。
我们要介绍的监督学习算法主要有:
- K近邻
- 线性回归于多项式回归
- 逻辑回归
- SVM
- 决策树和随机森林
非监督学习
训练数据本身无标记。
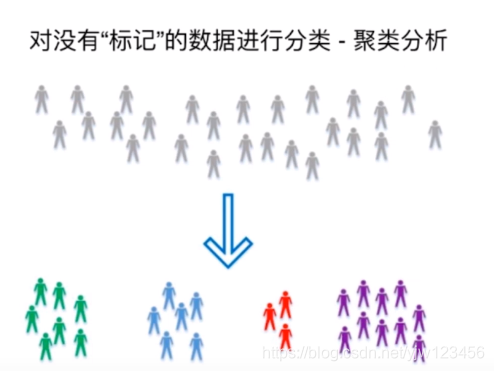
非监督学习可以通过一定的方法将上面的样本进行归类。
它的意义是可以对没有标记的数据进行分类-聚类分析:
非监督学习还有一个重要的作用是可以对数据进行降维处理。
主要包含两部分:
- 特征提取:信用卡的信用评级和人的胖瘦无关?(如果确定无关,就可以把胖瘦这个特征扔掉)
- 特征压缩:PCA
对数据降维意义之一是方便可视化。
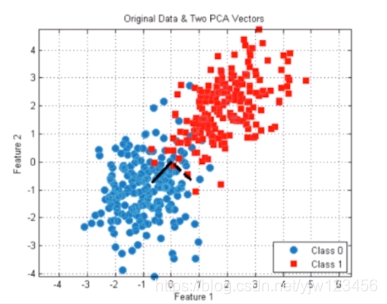
比如把高维数据降维二维就可以在平面上画出来。
非监督学习还可以进行异常检测。
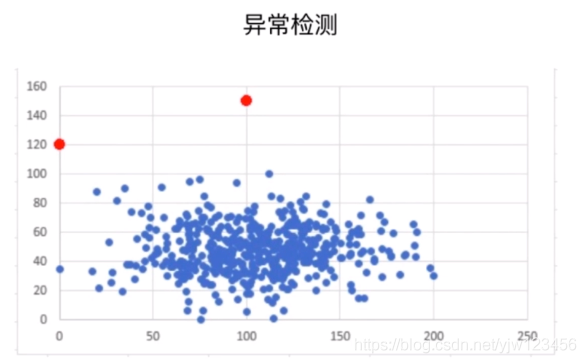
从这个例子可以看出来,这两个红点离蓝点非常的远,如果它们都是一类数据的话,这两个红点可能是异常数据。去除异常数据能让模型的泛化能力更好。
半监督学习
一部分数据有标记,另一部分数据没有。
其实这种情况在生活中很常见,比如对于某种领域,我们可以请领域专家人工标记少部分数据,对于剩下的大量数据都是没有标记的,因为人工标记成本太大;或者是各种原因产生的标记缺失 。
通常都先使用无监督学习手段对数据处理,之后使用监督学习手段做模型的训练和预测。
增强学习
根据周围环境的情况,采取行动,根据采取行动的结果,学习行动的方式叫增强学习。
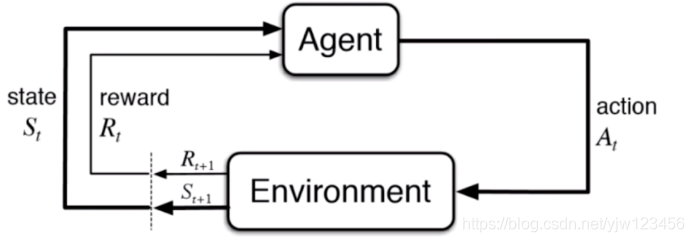
事实上AlphaGo就是通过增强学习来训练的。

像无人驾驶其实也是通过增强学习来实现的。
机器学习的其他分类
批量学习与在线学习
我们先来看下**批量学习(也叫离线学习)**的概念。
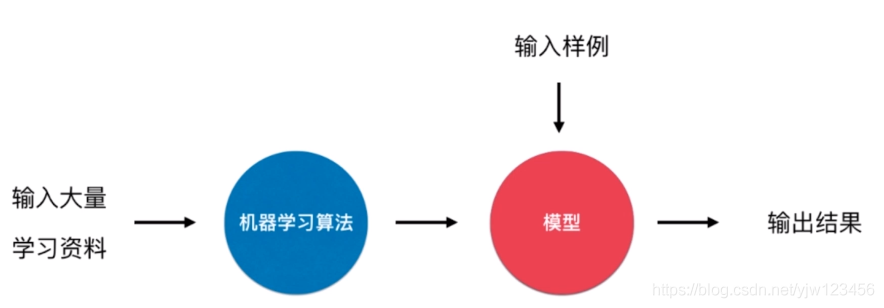
我们之前介绍的那些算法,如果没有特殊处理的话,都可以采用批量学习的方式。
在我们通过大量资料训练好一个模型后,然后就可以开始应用了,现在可以拿新的数据来进行预测,此时模型本身不会发生变化了。
虽然模型上线后可能会遇到大量新的数据,但是这些数据不会用来优化我们的模型了。这种学习方式就叫批量学习。
它的优点是简单。缺点是无法适应环境的变化。
以垃圾邮件为例,随着时间的推移垃圾邮件的形式也是日新月异的,可能仅能训练的垃圾邮件分类模型能很好工作,第二年遇到新的形式,效果就不好了。
对于垃圾邮件这个例子,解决方法可以是定时重新学习。比如每隔三个月重新学习一次。这个方法的缺点是每次重新批量学习,运算量巨大。在某些环境变化非常快的情况下,甚至是不可能的。
接下来看下在线学习。
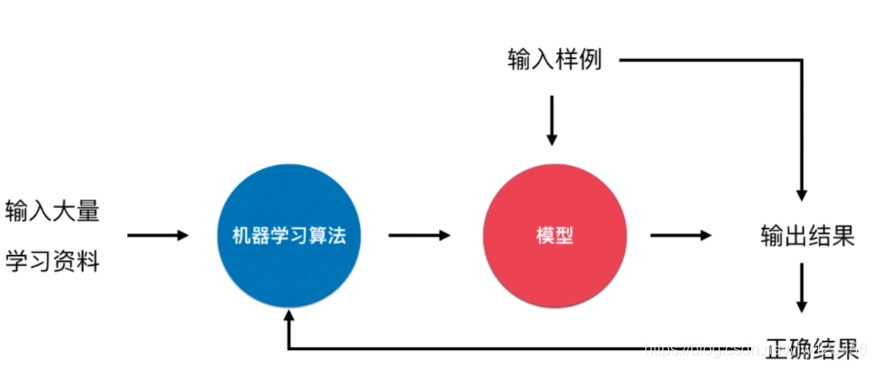
在线学习的流程和离线学习是一样的,区别就在于对于输入样例进入模型得到预期结果后,这个输入样例不会浪费掉,我们拿到这个输入样例的正确结果后就可以迭代进我们的算法,从而改进我们的模型。
比如预测下一分钟的股价,过了一分钟后就可以知道正确结果,我们可以拿这个正确结果来改进我们的模型。
因此整个过程叫在线学习。
在线学习的优点是可以及时反映新的环境变化,但是新的数据(异常数据)可能带来不好的变化,从而使得模型的表现反而降低。对于这个问题的解决方法是加强对数据质量的监控。 比如可以利用非监督学习的异常数据监测来排除异常数据。
在线学习也适用于数据量巨大,完全无法批量学习的环境。
参数学习与非参数学习
从另外一个维度可以将学习算法分为参数学习与非参数学习。
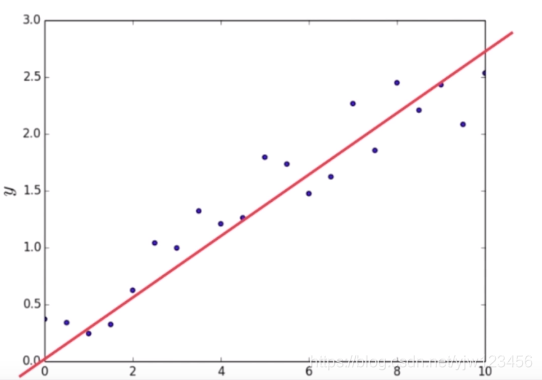
假设横坐标是房屋的面积,纵坐标是房屋的价格,基于这些数据点,我们可以假设房屋的价格是房屋面积的一个线性关系,如
基于这样的参数学习特点,就叫参数学习。一旦学到了参数,就不再需要原有的数据集。
那非参数学习呢,它不对模型进行过多假设。通常训练时的数据集也要参与预测的过程。这里要强调的是非参数学习不等于没有参数。
好了机器学习基础概念就介绍到这里,下篇文章会介绍下常用的工具。
