shuffle:
算子:groupByKey、reduceByKey、countByKey、join(不是所有的join)
遇到宽依赖就会有shuffle的产生
遇到shuffle 就会切出新的stage
数据倾斜:相同key的数据会分发到同一个task中去执行
找源码 要到 SparkEnv里面找
Spark发展到现在经过几种类型的shufle
1. hash : HashShuffleManager 现在源码里已经没有了 这个shuffle 存在一些弊端 所以不用了 1.2版本之前 默认是它
2. sort : SortShuffleManager >1.2版本 底层默认是它
3.tungsten-sort : SortShuffleManager
调优:代码、资源、数据倾斜(Skew)、Shuffle(这个影响面 不是太大的 )
HashShuffleManager
为了看源码 idea里pom使用老点的版本
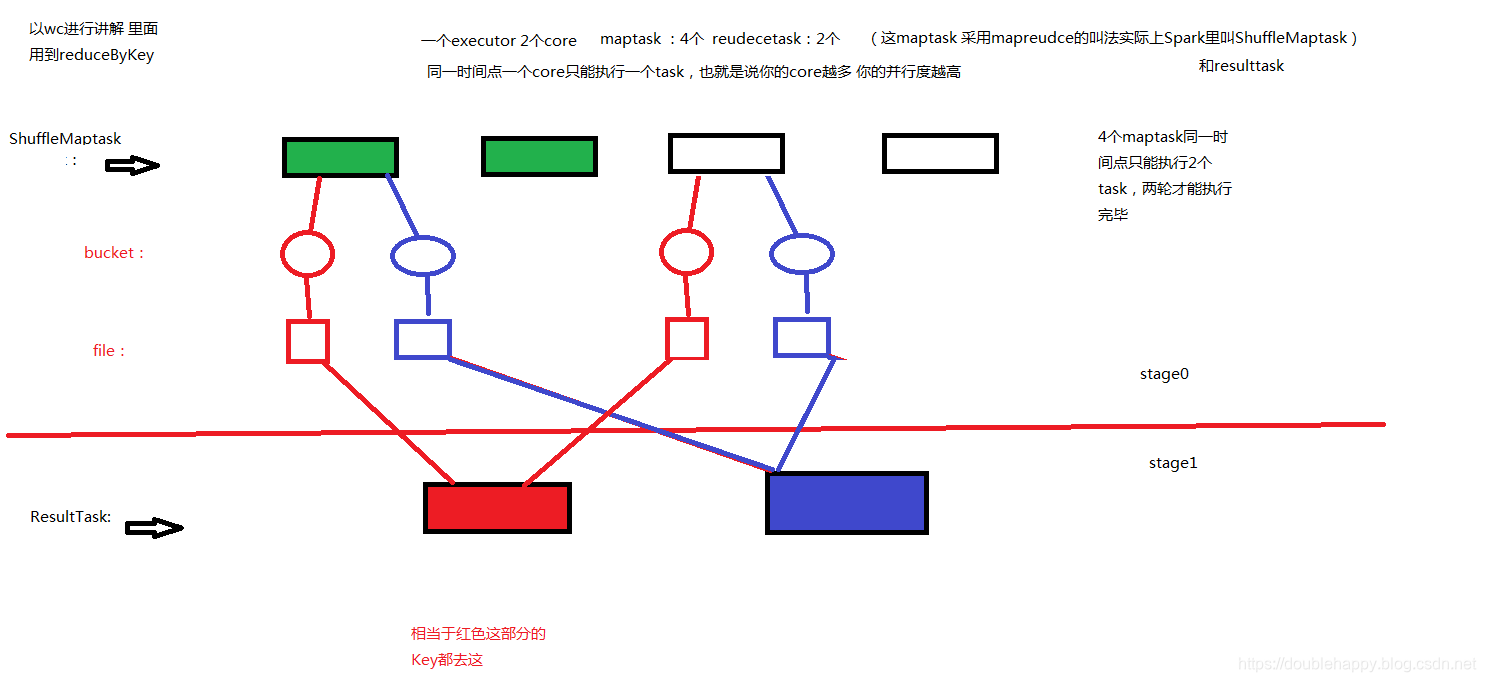
HashShuffleManager :
每一个maptask 要为每个reduceTask 创建“东西”
东西:内存(bucket) + 落地的文件file(就是 bucket内存满了 会文件落地)
产生的问题:
1.产生过多的file maptask数 * reducetask数
一般情况下 maptask 和reducetask数 都是比较大的 所以中间产生的磁盘文件数量惊人
那么bucket产生多少个呢?
bucket用完是可以释放的
2.耗费过多的内存空间
每个maptask需要开启 reduce个数的 bucket 会开启 M*R 的bucket数量 虽然是可以释放
但是同一时间点 同时存在的bucket的数量 reducetask个数 * core的数量
3.bucket多大?
官网
spark.shuffle.file.buffer 默认32k
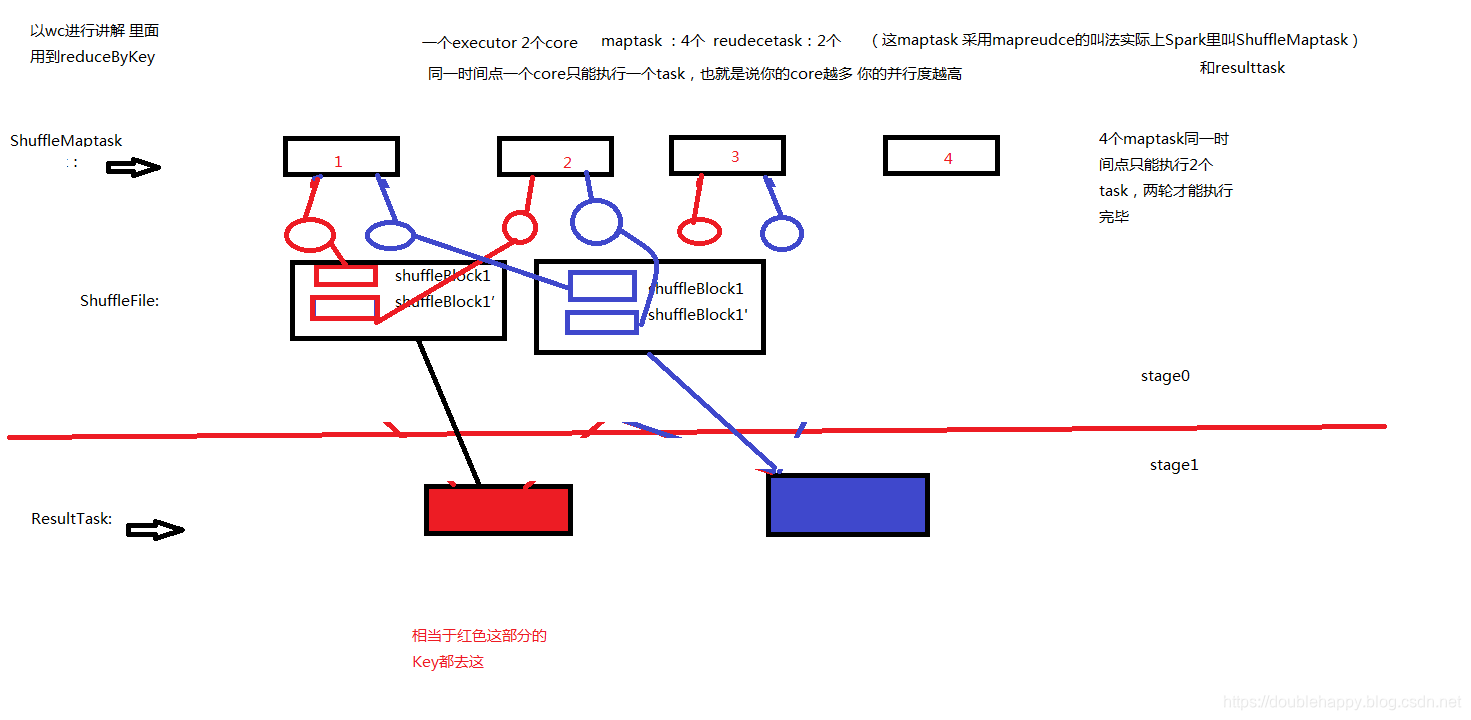
HashShuffleManager 优化:
优化后:
一个core上连续执行的shufflemaptask可以共用一个输出文件
core第一次的生成的文件 会形成 reduce个数 的shuffleFile文件
core第二次 就是运行下一个shufflemaptask 的时候 生成的文件会追加到第一次生成的shuffleBlock文件
文件数 : core数 *reduce task数
优化后的文件数减少了好多
怎么开启这个优化呢?
配置一个参数即可 spark.shuffle.consolidateFiles 为true
这个shuffle 了解和面试即可 不作为重点
1.自己梳理下SortShuffleManner
2.为什么说调优的时候 Shuffle不作为重点 因为 新版底层就两个 sort(默认) 和 tungsten-sort
3.hash 、 sort 要观察shuffle产生的文件数到底是多少个? 使用spark-shell就可以测试 eg :wc为例 设置maptask的数量 和reducetask的数量
( textFile算子可以设置 maptask数量 reduceByKey可以设置 reducetask数量)
shuffle的数据是落地的 落地到哪里呢?spark.local.dir 参数 控制的落到那个文件夹
测试:
1.普通的HashShuffleMannager
2.consolidateFiles的HashShuffleManager
3.sort
shuffle生成的文件数
参数的设置会吧 !!!
优化
你首先要知道spark哪些地方需要优化?
Tuning Spark
Because of the in-memory nature of most Spark computations, Spark programs can be bottlenecked by any resource in the cluster: CPU, network bandwidth, or memory. Most often, if the data fits in memory, the bottleneck is network bandwidth, but sometimes, you also need to do some tuning, such as storing RDDs in serialized form, to decrease memory usage. This guide will cover two main topics: data serialization, which is crucial for good network performance and can also reduce memory use, and memory tuning. We also sketch several smaller topics.
bottlenecked :瓶颈
1.CPU, network bandwidth, or memory
也就是说你公司集群资源不够就别搞spark了 -->cpu+mem
带宽 现在一般都是万兆的 千兆的就有点扯
官方从两个方面:
1.data serialization
2.memory tuning
1.数据序列化 可以内存的使用 就是数据体积变小了 占的内存少
2.内存调优
Data Serialization
看官网 写的很清楚
Serialization plays an important role in the performance of any distributed application.
因为算子里用到的东西 都是要经过序列化才可以
Tuning Spark
Java serialization:
Java serialization is flexible but often quite slow, and leads to large serialized formats for many classes.
Kryo serialization:
Spark can also use the Kryo library (version 4) to serialize objects more quickly.
Kryo is significantly faster and more compact than Java serialization (often as much as 10x),
but does not support all Serializable types and requires you to register the classes
you’ll use in the program in advance for best performance.
java:slow、large
Kryo:
1. requires you to register the classes
quickly、compact
2.not register the classes
也能运行 性能刚好相反
使用
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer") 来更换序列化的方式 因为默认是java的
conf.registerKryoClasses(Array(classOf[MyClass1], classOf[MyClass2]))
把你自己定义的类 MyClass1 有几个就写进去几个
1.代码里是这样写的 但是建议代码里别写死 最好别写 我说的是 序列化的方式 而不是注册
2,。最好 配置在 spark-default.conf 下面 ***
或者
3. spark-submit --conf k=v 也可以 ***
[double_happy@hadoop101 conf]$ cat spark-defaults.conf
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# Default system properties included when running spark-submit.
# This is useful for setting default environmental settings.
# Example:
spark.master local[2]
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop101:8020/spark_directory
# spark.serializer org.apache.spark.serializer.KryoSerializer
# spark.driver.memory 5g
# spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
[double_happy@hadoop101 conf]$
测试 通过cache 看看页面 data 大小就ok了
看看ui cache的data大小:
1.data=>rdd==>rdd.cache ==>action 这种 默认 cache 存储级别是 内存
2.data=>rdd==>rdd.persisit(mem_only_ser)==>action 默认java序列化
3.data=>rdd==>rdd.persisit(mem_only_ser)==>action 把这个参数 spark.serializer 打开 设置 kryo 这种就是没有注册
4.data=>rdd==>rdd.persisit(mem_only_ser)==>action 把这个参数 spark.serializer设置 kryo +register 注册
Determining Memory Consumption
你怎么知道一个数据集或者对象的内存占用了多少了呢?
两种方法:
1.The best way to size the amount of memory consumption a dataset will require is to create an RDD,
put it into cache, and look at the “Storage” page in the web UI.
The page will tell you how much memory the RDD is occupying.
2.To estimate the memory consumption of a particular object, use SizeEstimator’s estimate method.
第二种就是使用 SizeEstimator类
-r-xr-xr-x 1 double_happy double_happy 14M Sep 21 12:33 ip.txt
scala> import org.apache.spark.util.SizeEstimator
import org.apache.spark.util.SizeEstimator
scala> SizeEstimator.estimate("file:///home/double_happy/data/ip.txt")
res0: Long = 120
scala>
我的文件是14m 预估占用内存是 120m
测试第一种方法
scala> import org.apache.spark.util.SizeEstimator
import org.apache.spark.util.SizeEstimator
scala> SizeEstimator.estimate("file:///home/double_happy/data/ip.txt")
res0: Long = 120
scala> val rdd = sc.textFile("file:///home/double_happy/data/ip.txt")
rdd: org.apache.spark.rdd.RDD[String] = file:///home/double_happy/data/ip.txt MapPartitionsRDD[1] at textFile at <console>:25
scala> rdd.cache
res1: rdd.type = file:///home/double_happy/data/ip.txt MapPartitionsRDD[1] at textFile at <console>:25
scala> rdd.count
[Stage 0:> (0 + 2) / 2[Stage 0:=============================> (1 + 1) / 2 res2: Long = 115395
scala>

为什么第二种方法多这么多?
页面上的肯定是膨胀的变大是必然的 为什么 第二种多这么多?可以去看源码 查查资料
If you have less than 32 GB of RAM, set the JVM flag -XX:+UseCompressedOops to make pointers be four bytes instead of eight. You can add these options in spark-env.sh.
如果你的内存小于32G 设置JVM -XX:+UseCompressedOops 会好一些
Garbage Collection Tuning
需要先了解内存管理 和 jvm 才能 gc调优
gc我没有复习 所以这块之后补上。

Data Locality
数据本地化 了解即可 很难实现
If data and the code that operates on it are together then computation tends to be fast.
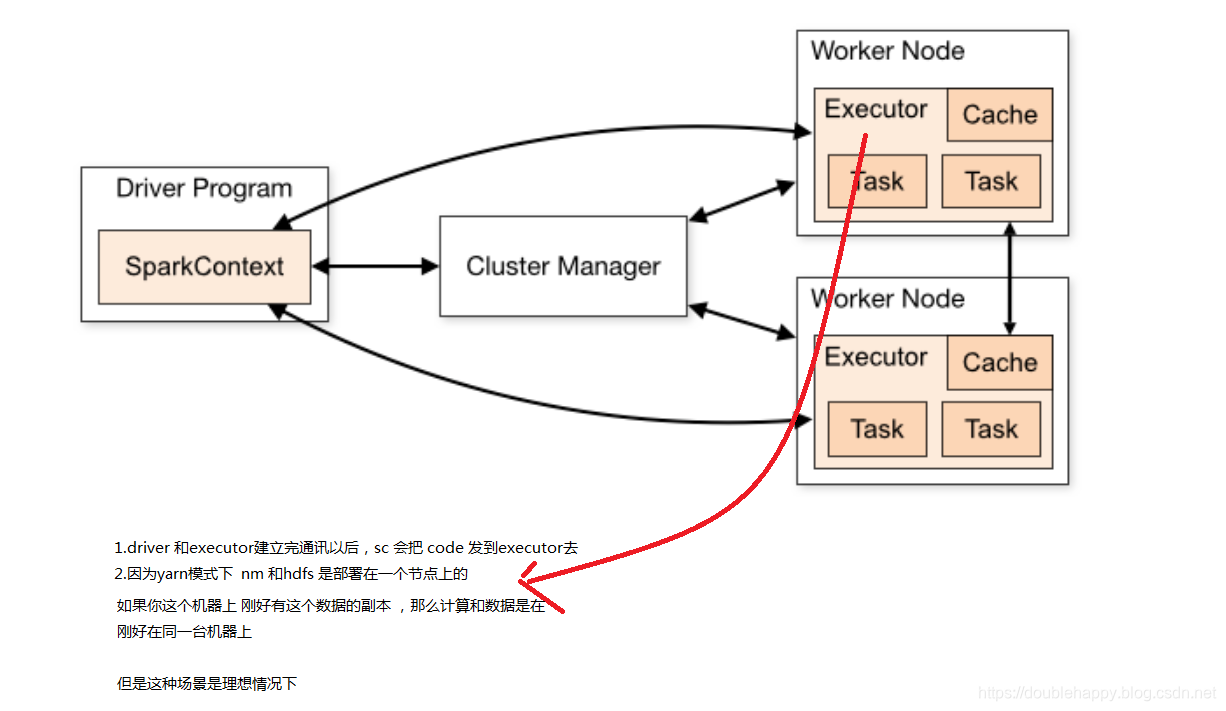
But if code and data are separated, one must move to the other. Typically it is faster to ship serialized code from place to place than a chunk of data because code size is much smaller than data. Spark builds its scheduling around this general principle of data locality.
one must move to the other 就是这两个总有一个要移动的
1.代码是 driver端发过去的 , 首先代码移动是没有难度的 ,但是
你的作业申请到资源后 就把作业定到申请的executor上去了 所以 正常情况下 是数据的移动 不存在代码的移动
Data locality is how close data is to the code processing it. There are several levels of locality based on the data’s current location. In order from closest to farthest:
levels of locality:
PROCESS_LOCAL
NODE_LOCAL
NO_PREF
RACK_LOCAL
ANY
这个等级spark默认从近-->远 选取 知道可以运行 毕竟越近越好嘛 生产上 达到NO_PREF 就挺好的
可以把这个理解成 妹子找对象 富二代 -->高富帅-->xxx--->屌丝--->男的 最后30岁了 依旧单身
总结shuffle参数:
1.spark.shuffle.consolidateFiles hashshuffle优化开启参数
2.spark.shuffle.file.buffer.kb 提高buffer 默认32k 可以调64 再128 相当于map端的
reduce端的也有 实际上 reduce 是 拉去file 到一个缓存区的
3.spark.reducer.maxMbInFlight reduce的缓冲区大小 默认48m 稍微调大一点 96m
既然有map端的和reduce端的 那么中间 应该也有的
4.spark.shuffle.io.maxRetries 最大次数是默认是3 就是shuffle 或者reduce端失败了 中间这块要去map端再去做一遍
5.spark.shuffle.io.retryWait 这是上面 要等待多久去retry一次呢 默认5s
6.spark.shuffle.sort.bypassMergeThreshold 这是 sort shuffle 阈值是200 合并数据 就是sort需要排序的 但是在有些场景不需要排序 由这参数控制的
7.spark.shuffle.spill.compress shuffle的时候需不需压缩
8.spark.io.compression.codec 需要压缩 你得配置一个 codec吧
9.spark.shuffle.compress 和 7 有什么区别呀 ?map output files 和 compress data spilled during shuffles的区别
10.spark.shuffle.manager 官网上没有 源码里的 默认走的是sortshuffle
这些参数就是 shuffle过程中我们要用到的调优参数