0. Shuffle概述
要理解什么是Shuffle,首先介绍大数据与分布式。我们知道大数据的存储是分布式存储,大数据的计算框架是分布式的计算框架。分布式必然存在数据的交互传输,简言之Shuffle就是分布式中数据交互传输的过程。
如下图所示,Stage 0的输出数据需要经过shuffle Writer写出到Block中,Stage 1的输入数据需要从Block中读入,这一中间结果的写出读入过程就是一次Shuffle。
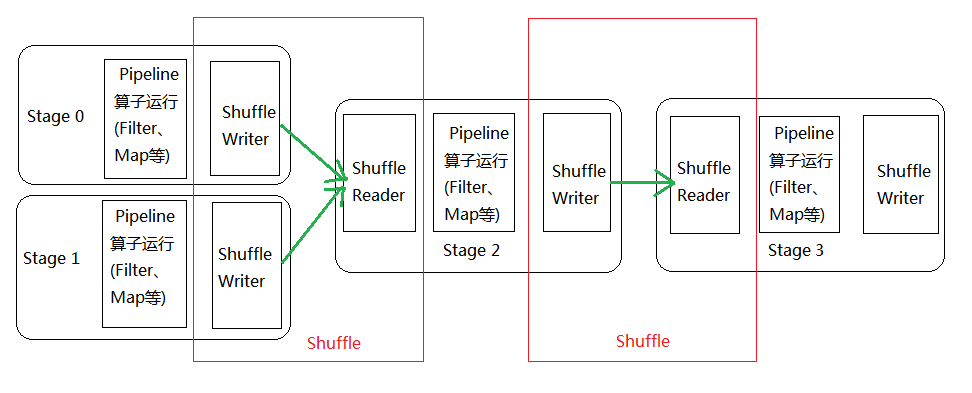
图1
那么问题来了,为什么Stage 0的数据不能直接交给Stage 1处理,非要经过Shuffle过程呢?
这里我们从Stage的划分开始说起,Stage划分的依据是RDD的宽窄依赖,宽窄依赖的划分依据参考此文:https://www.cnblogs.com/beichenroot/p/11414173.html
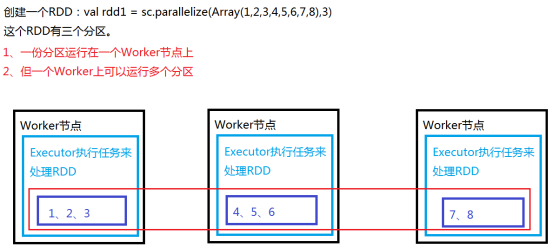
RDD之所以会存在宽窄依赖,与Spark天生的属性有关,Spark是分布式计算引擎,RDD是弹性分布式数据集,是Spark中处理数据的逻辑单位。RDD的数据存储方式如下图所示:图中RDD数据分别存储在三个节点不同的Executor的分区(Partition)中,分区可以理解为Block的不同表述,一个分区对应一个Block,这三个不同节点上的分区一起构成一个RDD。
回到正题,由于RDD的数据存在不同的节点上,分布式计算在不同节点上并行进行,如果是窄依赖,即分区间的数据不需要交互,则数据在本分区内操作;如果是宽依赖,数据需要往其他分区传送,则必然产生数据的读写,则存在Shuffle。
1. Shuffle的重要性
由图1Shuffle的过程可知,Shuffle过程包含三部分:
1. Shuffle的Wiiter
2. 网络传输
3. Shuffle的Read
这三部分操作包含内存操作、磁盘I/O、网络I/O以及JVM管理,影响了Spark应用程序的绝大部分效率。对于好的程序代码,大部分的性能(95%)都消耗在Shuffle阶段的本地写磁盘文件、网络传输数据及抓取数据中。所以Spark针对Shuffle过程做了大量优化。
2. Spark Shuffle的发展过程
Spark Shuffle早期采用的是HashShuffle,HashShuffle最大的问题是产生的文件数量(Mapper分片数量 * Reducer的分片数量)太多,导致大量的IO内存消耗以及沉重的GC负担;
Spark采用SortedBasedShuffle根据Map Task的数量来生成文件,如下图所示,每个Map任务会生成两个文件,一个是数据文件分片写入,一个是偏移量文件,记录了每个分片的相关信息。Reduce任务读取数据时首先从偏移量文件中获取数据的位置,再到数据文件中读取数据。SortedBasedShuffle将Shuffle中的文件数量降低到了2 * Map任务个数,带来的优化如下:
1. Mapper端占用内存变少
2. 增加了Spark处理大规模数据的能力(可并行的任务数增加)
3. Reducer端抓取数据的次数变少
4. 网络通道的句柄变少
5. 减少了数据本身对内存的消耗

Spark Shuffle详细内容可参考此文:https://www.cnblogs.com/itboys/p/9226479.html
3. Shuffle与Storage模块间的交互
Spark中存储模块被抽象成Storage,Storage代表着Spark中的数据存储系统,负责管理数据块(Block),Block是存取数据的最小单元,等价于RDD中的Partition。
Storage抽象模块分为两个层次:
1. 通信层:通信层是典型的主从结构,Master和Slave之间传输控制和状态信息。通信层主要由BlockManager、BlockManagerMaster、BlockManagerMasterEndPoint、BlockManagerSlaverEndPoint等类实现。
2. 存储层:负责把数据存储到内存、磁盘或者堆外内存中,有时还需要为数据在远程节点上生成副本。Spark存储层的实现类有DiskStore和MemoryStore。
Shuffle过程中进行的数据读写实质是通过操作BlockManager接口来实现的。
3.1 BlockManager架构
1. Application启动时会在SparkEnv中注册BlockManagerMaster以及MapOutputTracker
a. BlockManagerMaster:对整个集群的Block数据进行管理
b. MapOutputTracker:跟踪所有的Mapper输出
2. 构建BlockManagerMaster时会创建BlockManagerMasterEndPoint,BlockManagerMasterEndPoint本身是一个消息体,负责通过远程通信的方式管理所有节点的BlockManager。
3. 没启动一个ExecutorBackend,都会实例化BlockManager,并通过远程通信的方式注册给BlockManagerMaster;实质上是Executor中的BlockManager在启动时注册给了Driver上的BlockManagerMasterEndPoint。
4. MemoryStore是BlockManager中负责内存数据存储和读写的类。
5. DiskStore是BlockManager中负责磁盘数据存储和读写的类。
6. DiskBlockManager:管理Logical Block与Disk上的Physical Block之间映射关系并负责磁盘文件的创建、读写等。
3.2 Shuffle与BlockManager交互
3.2.1 Shuffle写数据
基于Sort的Shuffle实现的ShuffleHandle包含BypassMergeSortShuffleHandle和BaseShuffleHandle,两种ShuffleHandle对应的数据写入类为BypassMergeSortShuffleWriter和SortShuffleWriter,这里以SortShuffleWriter为例进行梳理。
SortShuffleWriter写数据由下面的write方法实现,首先需要通过ShuffleBlockResolver获取到数据文件。
/** Write a bunch of records to this task's output */
override def write(records: Iterator[Product2[K, V]]): Unit = {
...
// Don't bother including the time to open the merged output file in the shuffle write time,
// because it just opens a single file, so is typically too fast to measure accurately
// (see SPARK-3570).
val output = shuffleBlockResolver.getDataFile(dep.shuffleId, mapId)
...
val tmp = Utils.tempFileWith(output)
try {
val blockId = ShuffleBlockId(dep.shuffleId, mapId, IndexShuffleBlockResolver.NOOP_REDUCE_ID)
val partitionLengths = sorter.writePartitionedFile(blockId, tmp)
shuffleBlockResolver.writeIndexFileAndCommit(dep.shuffleId, mapId, partitionLengths, tmp)
具体调用ShuffleBlockResolver子类IndexShuffleBlockResolver中的getDataFile方法,此处可以看到实际是通过blockManager获取的数据。
def getDataFile(shuffleId: Int, mapId: Int): File = {
blockManager.diskBlockManager.getFile(ShuffleDataBlockId(shuffleId, mapId, NOOP_REDUCE_ID))
}
然后生成ShuffleBlockId,通过ExternalSorter的writePartitionedFile方法最终写出数据。writePartitionedFile实质调用的仍是blockManager中的写方法。所以Shffle写数据底层是由blockManager实现。
def writePartitionedFile(
blockId: BlockId,
outputFile: File): Array[Long] = {
// Track location of each range in the output file
val lengths = new Array[Long](numPartitions)
val writer = blockManager.getDiskWriter(blockId, outputFile, serInstance, fileBufferSize,
context.taskMetrics().shuffleWriteMetrics)
3.2. Shuffle读数据
Shuffle读数据是从SortShuffleManager的getReader获取一个数据阅读器,getReader方法中创建了BlockStoreShuffleReader实例。、
BlockStoreShuffleReader的read方法首先实例化ShuffleBlockFetcherIterator。ShuffleBlockFetcherIterator中的成员blockManager管理内存和磁盘数据上的读写。
* ShuffleBlockFetcherIterator中splitLocalRemoteBlocks划分本地和远程的blocks,Utils.randomize(remoteRequests)把远程请求通过随机的方式添加到队列中,fetchUpToMaxBytes发送远程请求获取blocks,fetchLocalBlocks获取本地的blocks。