将数据打乱重新分配到不同节点上的过程就是shuffle。Shuffle的目的就是将具有共同的特征的数据汇聚在同一个节点上来处理,比如hadoop的reduce还有排序等作用。当然并不是所有的shuffle过程都有排序,甚至为了减少排序带来不必要的开销,spark最初的框架中用的Hash Based Shuffle Write就是这样设计的,没有排序。
Spark集群Shuffle分为2部分:Mapper端和Reducer端。Mapper端:通过Cache不断的把数据写入到文件系统中并汇报给Driver。Reducer端:把相同的Key放在同一个Task中,并进行业务逻辑的操作。Reducer端抓数据的时候也有一个小的缓存区。Mapper端有一个缓存,根据Redcuer端的需要,对数据分成不同的部分,然后在Reducer端抓到属于自己的数据进行reduce操作,把相同Key的数据Pull过来以后进行reduce操作。
1.Hash Based Shuffle Write
其实在很多计算场景中并不需要排序,排序后反而会带来一些不必要的开销。Executor上执行Shuffle Map Task时调用RunTask,从sparkEnv中获取到manager,从manager中获取write,将对RDD计算的中间结果持久化,就是在本地存起来,这样下游的Task直接调用中间结果就可以了,之前也提到过这样也拥有了不错的容错机制,恢复数据的时候不必要重新计算所有的RDD。当然map端也可以对中间的结果进行一些操作,比如聚合等,然后再存入本地,以便之后的Task进行调用。
这里有一个重要的实现也最终成为Hash Bashed Shuffle Write被替换掉默认选项的原因,就是每个Shuffle Map Task对每一个下游的partition都生成一个文件,每个partition对应一个Task。这样就产生了Shuffle Map Task*following_partition个文件(见下图),产生的文件太过庞大,并且文件众多,每个节点会打开多个文件,访问方式是随机的,导致spark的性能很差。

效果差就会进行改进,于是spark官方加入了Shuffle Consolidate Writer。这个组件的加入明显减少了生成的文件,但随机访问多个文件的问题还没有被解决。它的机制是这样的:就是加入了core的概念,core包含很多maptask,同一个core中的shuffle map task在第一个文件建立后,之后的数据追加进去就好了,不会再生成新的文件。这样生成的文件会大大减少。
接下来说说一说现在spark中默认的shuffle。
2.Sort Based Shuffle write
Sort based shuffle已经成为spark的默认选项,而Hash based shuffle已经完全被spark所淘汰。Sort based shuffle中每个shuffle map task不是为每个partition生成一个文件,而是将他们写在同一个文件内,然后生成一个索引文件index来方便访问,这似乎有点像路由表的意思,索引记录不同partition的起始位置。这里要了解的是,正因为不必要的排序带来不必要的开销导致了性能下降使得hadoop中mapreduce组件备受诟病,才提出了Hash based shuffle,又因为Hash产生大量的文件又开发了sort based shuffle。这样一来,又变成了排序。但sort based shuffle 的排序有很好的优化,shuffle map task 对每一个key 按照partition进行排序,同一个partition的key不进行排序,这样就避免了不必要的排序。
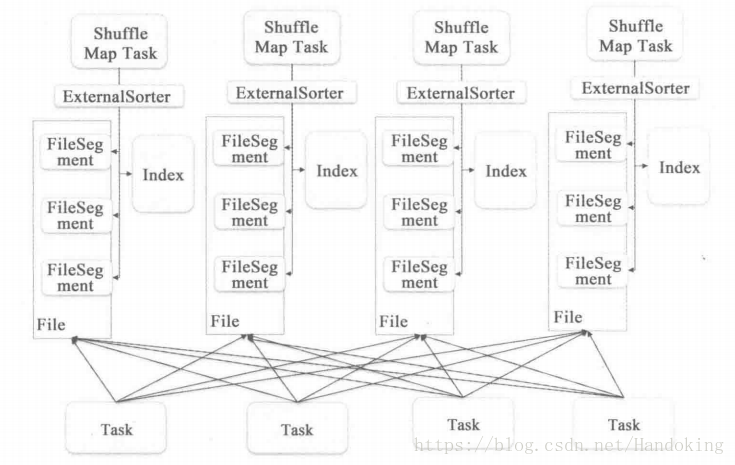
从图上可以看出还有外部排序的部件,这是因为当写入的过程中如果内存不够用了可以把数据进行外部存储,但这一部分数据的partitionID以及文件数目等一些信息会被记录下里放在数据的开头,又有点像计算机网络中的头部信息了,都是为了访问或者收到时进行识别。这些外部存储的文件需要进行归并排序。至于多个文件打开随机读取效率低的问题,其实这里也没有很好的解决,只是推荐了依次打开文件的数目,用户可以设置。