无论是MapReduce还是Spark,Shuffle无疑是性能调优的重点。Spark的Shuffle和MapReduce的Shuffle思想相同,在实现细节和优化方式上不同。本文重点介绍Spark的Shuffle机制。
Shuffle Overview
为什么要Shuffle
数据分布在不同的存储结点和计算单元上,为了将某种共同特征的数据聚集在一个结点上计算,这个过程就涉及到数据的shuffle。
Shuffle的难点
- 数据量大;2. 合适的partition;3. 网络带宽,是否考虑压缩;4. 序列化
Spark Shuffle
Spark中,整个Job转化为RDD DAG来执行,由DAGScheduler转化为Stage DAG,每个Stage中产生相应的Task集合,每个Stage中是通过执行ShuffleMapTask或者ResultTask来进行运算的。Spark Shuffle分为两个阶段:Shuffle Write和Shuffle Fetch阶段,如下图所示:
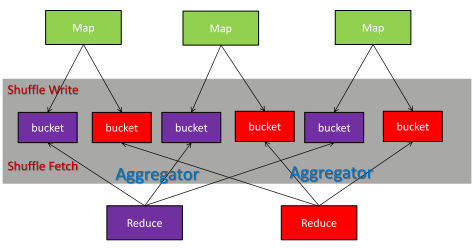
对于MapReduce,Reduce拿到的数据是已经排好序的,但是在实际的很多场景不需要排序,而排序只能是系统性能变差。为了避免排序,Spark设计了Hash Based Shuffle Writer。
Hash Based Shuffle Writer
在stage结束计算之后,为了下一个stage可以执行shuffle计算,而将每个task处理的数据按key进行hash,将相同key都写入同一个磁盘文件中,而每一个磁盘文件都只属于下游stage的一个task。在将数据写入磁盘之前,会先将数据写入内存缓冲中,当内存缓冲填满之后,才会溢写到磁盘文件中去。
存在的问题:
1、打开的文件过多:上游的每个Shuffle Map Task为每个下游的Task创建一个bucket文件,文件数量:#(shuffle_map_task) * #(following_task),打开如此多的文件会占用大量的内存,对整个集群造成压力。
2、同时打开大量的文件,意味着增加了随机读的次数。
为了解决Hash Based Shuffle Writer产生的文件过多,Spark 0.8.1引入了Shuffle Consolidate机制,旨在减少shuffle过程中产生的大量文件。
对于运行在一个core上的Shuffle Map Task,第一个Shuffle Map Task会创建一个文件,之后的Shuffle Map Task会将文件追加到这个文件上,因此,文件数量减少到#(cores) * #(following_task)
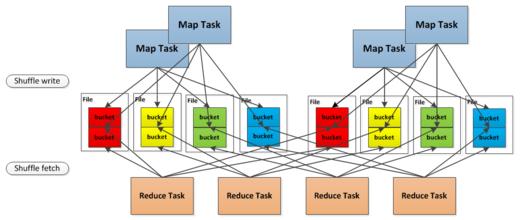
Sort Based Shuffle Writer
Hash Based Shuffle Writer的Shuffle Consolidate机制将文件数量减少到#(cores) * #(following_task),不过文件数量还是较多。为了更好的解决这个问题,Spark 1.1引入了Sort Based Shuffle Writer。
首先,每个Shuffle Map Task将所有的结果写入到一个文件里,同时生成一个Index文件,下游的Task通过Index文件获取它要处理的文件。这样避免了大量文件的产生,节省了内存和随机I/O的产生。
Sort Based Shuffle Writer按照key对应的Partition ID进行排序,属于同一个Partition的key不会排序。
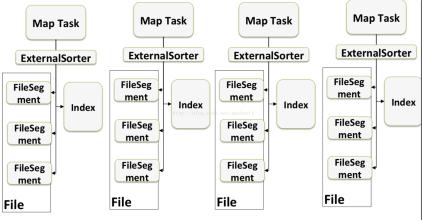
实现过程:
(1)对于每个Partition,将key/value 插入到内存缓存中(scala.Array);
(2)当内存缓存中的key/value超过阈值,将内存中的数据写到磁盘文件,这个文件会记录partition ID和key/value的数目;
(3)最后将所有的磁盘文件进行归并排序;
(4)生成最终文件以及Index文件;
Shuffle Fetch
每个stage刚开始时,该stage每一个task就需要将上一个stage的计算结果中的所有相同key,从各个节点上通过网络都拉取到自己所在的节点上,然后进行key的聚合操作。对于Hash Based Shuffle Writer,task给下游stage的每个task都创建了一个磁盘文件,因此Shuffle Fetch的过程中,每个task只要从上游stage的所有task所在节点上,拉取属于自己的那一个磁盘文件即可。
Fetch到的数据形成分区,所有分区形成ShuffledRDD。通过聚集函数将ShuffledRDD每个分区中的每条数据存储到AppandOnlyMap中,边Fetch数据边做聚集处理,最后将形成的结果形成分区,所有分区形成MapPartitionsRDD。
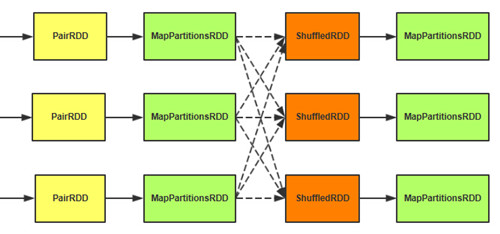
Spark的 Aggregator分为两种:不需要外排和需要外排的。不需要外排的聚集,在内存中的AppendOnlyMap中对数据进行聚集,而需要外排的聚集,先在内存做聚集,当内存数据达到阈值时,将数据排序后写入磁盘,由于磁盘的每部分数据只是整体的部分数据,最后再将磁盘数据全部进行合并和聚集。
参考资料:
Spark性能调优:Shuffle调优