Spark Shuffle
1、概述
Shuffle,翻译成中文就是洗牌。之所以需要Shuffle,还是因为具有某种共同特征的一类数据需要最终汇聚(aggregate)到一个计算节点上进行计算。这些数据分布在各个存储节点上并且由不同节点的计算单元处理。以最简单的Word Count为例,其中数据保存在Node1、Node2和Node3;
经过处理后,这些数据最终会汇聚到Nodea、Nodeb处理,如下图所示:
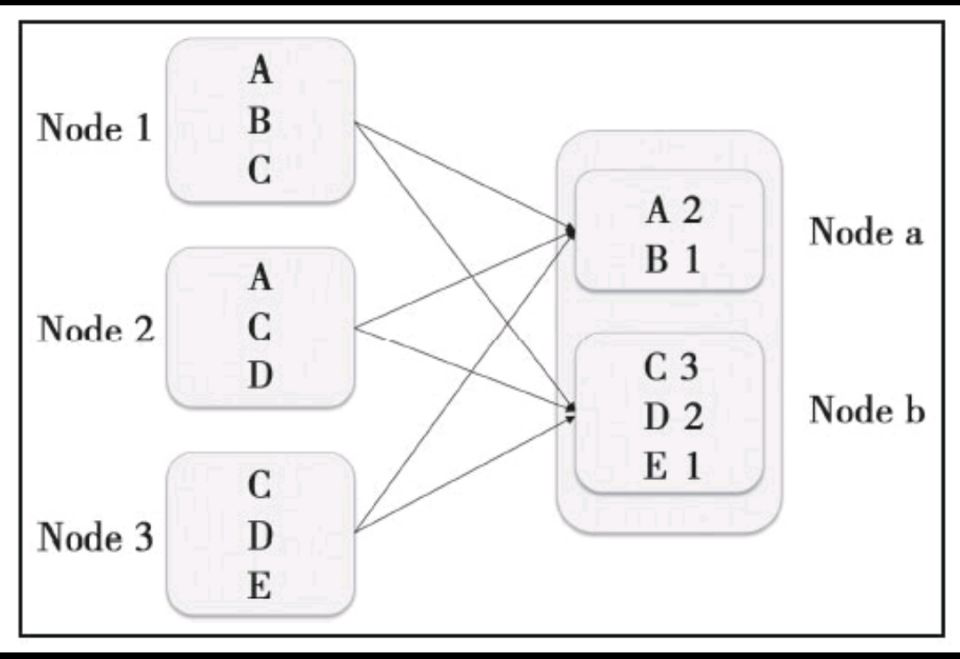
这个数据重新打乱然后汇聚到不同节点的过程就是Shuffle。但是实际上,Shuffle过程可能会非常复杂,有以下几个问题:
1)数据量会很大,比如单位为TB或PB的数据分散到几百甚至数千、数万台机器上。
2)为了将这个数据汇聚到正确的节点,需要将这些数据放入正确的Partition,因为数据大小已经大于节点的内存,因此这个过程中可能会发生多次硬盘续写。
3)为了节省带宽,这个数据可能需要压缩,如何在压缩率和压缩解压时间中间做一个比较好的选择?
4)数据需要通过网络传输,因此数据的序列化和反序列化也变得相对复杂。
一般来说,每个Task处理的数据可以完全载入内存(如果不能,可以减小每个Partition的大小),因此Task可以做到在内存中计算。但是对于Shuffle来说,如果不持久化这个中间结果,一旦数据丢失,就需要重新计算依赖的全部RDD,因此有必要持久化这个中间结果。所以这就是为什么Shuffle过程会产生文件的原因。
2、Shuffle Write
Shuffle Write数据是如何持久化到文件中,以使得下游的Task可以获取到其需要处理的数据的(即Shuffle Read)。在Spark 0.8之前,Shuffle Write是持久化到缓存的,但后来发现实际应用中,shuffle过程带来的数据通常是巨量的,所以经常会发生内存溢出的情况,所以在Spark 0.8以后,Shuffle Write会将数据持久化到硬盘,再之后Shuffle Write不断进行演进优化,但是数据落地到本地文件系统的实现并没有改变。
1.Hash Based Shuffle Write
在Spark1.0以前,Spark只支持Hash Based Shuffle。因为在很多运算场景中并不需要排序,因此多余的排序只能使性能变差,比如Hadoop的Map Reduce就是这么实现的,也就是Reducer拿到的数据都是已经排好序的。
实际上Spark的实现很简单:每个Shuffle Map Task根据key的哈希值,计算出每个key需要写入的Partition然后将数据单独写入一个文件,这个Partition实际上就对应了下游的一个Shuffle Map Task或者Result Task。因此下游的Task在计算时会通过网络(如果该Task与上游的Shuffle Map Task运行在同一个节点上,那么此时就是一个本地的硬盘读写)读取这个文件并进行计算。
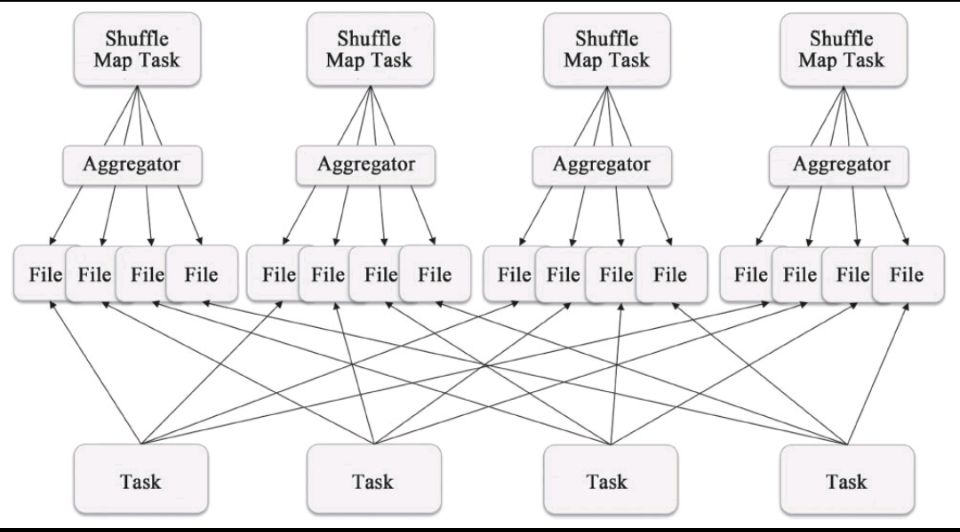
Hash Based Shuffle Write存在的问题:
由于每个Shuffle Map Task需要为每个下游的Task创建一个单独的文件,因此文件的数量就是:number(shuffle_map_task)*number(following_task)。
如果Shuffle Map Task是1000,下游的Task是500,那么理论上会产生500000个文件(对于size为0的文件Spark有特殊的处理)。生产环境中Task的数量实际上会更多,因此这个简单的实现会带来以下问题:
1)每个节点可能会同时打开多个文件,每次打开文件都会占用一定内存。假设每个Write Handler的默认需要100KB的内存,那么同时打开这些文件需要50GB的内存,对于一个集群来说,还是有一定的压力的。尤其是如果Shuffle Map Task和下游的Task同时增大10倍,那么整体的内存就增长到5TB。
2)从整体的角度来看,打开多个文件对于系统来说意味着随机读,尤其是每个文件比较小但是数量非常多的情况。而现在机械硬盘在随机读方面的性能特别差,非常容易成为性能的瓶颈。如果集群依赖的是固态硬盘,也许情况会改善很多,但是随机写的性能肯定不如顺序写的。
2.Sort Based Shuffle Write
在Spark1.2.0中,Spark Core的一个重要的升级就是将默认的Hash Based Shuffle换成了Sort Based Shuffle,即spark.shuffle.manager从Hash换成了Sort,对应的实现类分别是如下两个类:
org.apache.spark.shuffle.hash.HashShuffleManager
org.apache.spark.shuffle.sort.SortShuffleManager
那么Sort Based Shuffle“取代”Hash Based Shuffle作为默认选项的原因是什么?
正如前面提到的,Hash Based Shuffle的每个Mapper都需要为每个Reducer写一个文件,供Reducer读取,即需要产生M*R个数量的文件,如果Mapper和Reducer的数量比较大,产生的文件数会非常多。
而Sort Based Shuffle的模式是:每个Shuffle Map Task不会为每个Reducer生成一个单独的文件;相反,它会将所有的结果写到一个文件里,同时会生成一个Index文件,
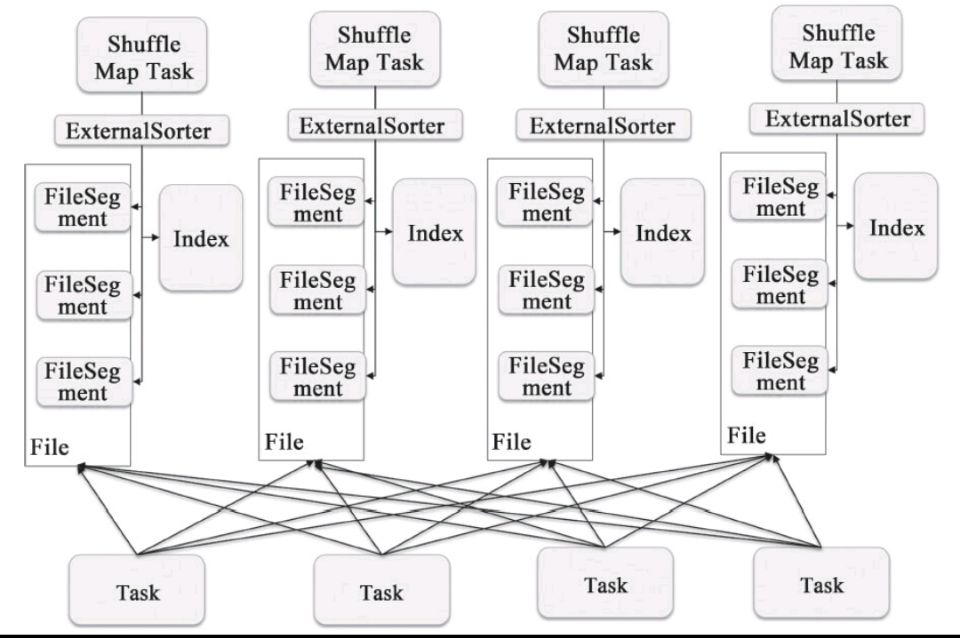
Reducer可以通过这个Index文件取得它需要处理的数据。避免产生大量文件的直接收益就是节省了内存的使用和顺序Disk IO带来的低延时。节省内存的使用可以减少GC的风险和频率。而减少文件的数量可以避免同时写多个文件给系统带来的压力。
Sort Based Write实现详解:
Shuffle Map Task会按照key相对应的Partition ID进行Sort,其中属于同一个Partition的key不会Sort。因为对于不需要Sort的操作来说,这个Sort是负收益的;要知道之前Spark刚开始使用Hash Based的Shuffle而不是Sort Based就是为了避免Hadoop Map Reduce对于所有计算都会Sort的性能损耗。对于那些需要Sort的运算,比如sortByKey,这个Sort在Spark 1.2.0里还是由Reducer完成的。
3、Shuffle相关参数配置
Shuffle是Spark Core比较复杂的模块,它也是非常影响性能的操作之一。因此,在这里整理了会影响Shuffle性能的各项配置。
1.spark.shuffle.manager
Spark 1.2.0官方版本支持两种方式的Shuffle,即Hash Based Shuffle和Sort Based Shuffle。其中在Spark 1.0之前仅支持Hash Based Shuffle。Spark 1.1引入了Sort Based Shuffle。Spark 1.2的默认Shuffle机制从Hash变成了Sort。如果需要Hash Based Shuffle,只需将spark.shuffle.manager设置成“hash”即可。
1>配置方式
①进入spark安装目录的conf目录
②cp spark-defaults.conf.template spark-defaults.conf
③spark.shuffle.manager=hash
2>应用场景
当产生的临时文件不是很多时,性能可能会比sort shuffle要好。
如果对性能有比较苛刻的要求,那么就要理解这两种不同的Shuffle机制的原理,结合具体的应用场景进行选择。
对于不需要进行排序且Shuffle产生的文件数量不是特别多时,Hash Based Shuffle可能是更好的选择;因为Sort Based Shuffle会按照Reducer的Partition进行排序。
而Sort Based Shuffle的优势就在于可扩展性,它的出现实际上很大程度上是解决Hash Based Shuffle的可扩展性的问题。由于Sort Based Shuffle还在不断地演进中,因此它的性能会得到不断改善。
对于选择哪种Shuffle,如果性能要求苛刻,最好还是通过实际测试后再做决定。不过选择默认的Sort,可以满足大部分的场景需要。
2.spark.shuffle.spill
这个参数的默认值是true,用于指定Shuffle过程中如果内存中的数据超过阈值(参考spark.shuffle.memoryFraction的设置)时是否需要将部分数据临时写入外部存储。如果设置为false,那么这个过程就会一直使用内存,会有内存溢出的风险。因此只有在确定内存足够使用时,才可以将这个选项设置为false。
3.spark.shuffle.memoryFraction
在启用spark.shuffle.spill的情况下,spark.shuffle.memoryFraction决定了当Shuffle过程中使用的内存达到总内存多少比例的时候开始spill。在Spark 1.2.0里,这个值是0.2。通过这个参数可以设置Shuffle过程占用内存的大小,它直接影响了写入到外部存储的频率和垃圾回收的频率。可以适当调大此值,可以减少磁盘I/O次数。
4.spark.shuffle.sort.bypassMergeThreshold
这个配置的默认值是200,用于设置在Reducer的Partition数目少于多少的时候,Sort Based Shuffle内部不使用归并排序的方式处理数据,而是直接将每个Partition写入单独的文件。这个方式和Hash Based的方式类似,区别就是在最后这些文件还是会合并成一个单独的文件,并通过一个Index索引文件来标记不同Partition的位置信息。
这个可以看作Sort Based Shuffle在Shuffle量比较小的时候对于Hash Based Shuffle的一种折中。当然了它和Hash Based Shuffle一样,也存在同时打开文件过多导致内存占用增加的问题。因此如果GC比较严重或者内存比较紧张,可以适当降低这个值。
5.spark.shuffle.blockTransferService
在Spark 1.2.0中这个配置的默认值是netty,而在之前的版本中是nio。它主要是用于在各个Executor之间传输Shuffle数据。netty的实现更加简洁,但实际上用户不用太关心这个选项。除非有特殊需求,否则采用默认配置即可。
6.spark.shuffle.consolidateFiles
这个配置的默认值是false。主要是为了解决在Hash Based Shuffle过程中产生过多文件的问题。如果配置选项为true,那么对于同一个Core上运行的Shuffle Map Task不会产生一个新的Shuffle文件而是重用原来的。
但是consolidateFiles的机制在Spark 0.8.1就引入了,到Spark 1.2.0还是没有稳定下来。从源码实现的角度看,实现源码是非常简单的,但是由于涉及本地文件系统等限制,这个策略可能会带来各种各样的问题。一般不建议开启。
7.spark.shuffle.compress和spark.shuffle.spill.compress
这两个参数的默认配置都是true。spark.shuffle.compress和spark.shuffle.spill.compress都是用来设置Shuffle过程中是否对Shuffle数据进行压缩。其中,前者针对最终写入本地文件系统的输出文件;后者针对在处理过程需要写入到外部存储的中间数据,即针对最终的shuffle输出文件。
1>设置spark.shuffle.compress
需要评估压缩解压时间带来的时间消耗和因为数据压缩带来的时间节省。如果网络成为瓶颈,比如集群普遍使用的是千兆网络,那么将这个选项设置为true可能更合理;如果计算是CPU密集型的,那么将这个选项设置为false可能更好。
2>设置spark.shuffle.spill.compress
如果设置为true,代表处理的中间结果在spill到本地硬盘时都会进行压缩,在将中间结果取回进行merge的时候,要进行解压。因此要综合考虑CPU由于引入压缩、解压的消耗时间和Disk IO因为压缩带来的节省时间的比较。在Disk IO成为瓶颈的场景下,设置为true可能比较合适;如果本地硬盘是SSD,那么设置为false可能比较合适。
8.spark.reducer.maxMbInFlight
这个参数用于限制一个Reducer Task向其他的Executor请求Shuffle数据时所占用的最大内存数,尤其是如果网卡是千兆和千兆以下的网卡时。默认值是 设置这个值需要综合考虑网卡带宽和内存。
上一篇:Spark的架构
下一篇: