K近邻算法(k-nearest neighbor, k-NN)在各种算法中算是比较简单的算法,理解起来也比较轻松。
1.描述
在一个已知特征标签的数据集(训练集)中,数据集的各个元素在坐标空间中都是有距离的,而距离最近的数据子集一般具有相对优势的特征标签数量。新数据(测试数据,没有特征标签)输入后,观测与其相临近的K个数据组成的数据子集的特征标签,其中数量最多的即是该新数据的特征标签。
其中,有两个比较重要的概念:1.距离,一般采用欧氏距离度量,是欧几里得空间里两点间“普通”(即直线)距离。此外还有曼哈顿距离、切比雪夫距离、闵可夫斯基距离等。2.K,是自定义参数,K选取的大小对预测准确度有很大的影响,一般在2~10之间。
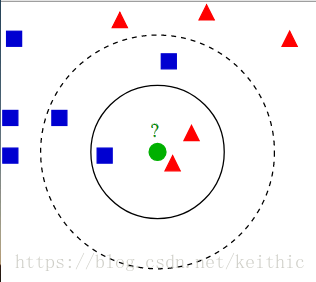
如图所示,数据集有两个特征标签(蓝色方块、红色三角),测试样本(绿色圆形)要么是蓝色方块类,要么是红色三角类。如果 k=3(实线圆圈)它会被分配给红色三角类,因为内圆内红色数量居多;如果k=5(虚线圆圈)它会被分配到蓝色方块类(3个正方形与2个三角形在外侧圆圈之内)。
2.算法
输入:训练集
其中,为实例的特征向量,
为实例的类别,i = 1,2,...,N;实例特征向量x;
输出:实例x所属的类y。
(1)根据给定的距离度量,在训练集T中找出与x最近邻的k个点,涵盖这k个点的x的邻域记作;
(2)在中根据分类决策规则(如多数投票)决定x的类别y:

式中,I 为指示函数,即当时 I 为1,否则 I 为0。
3.代码实现
(注释来自Python3《机器学习实战》学习笔记(一):k-近邻算法(史诗级干货长文))
# -*- coding: UTF-8 -*-
import numpy as np
import operator
"""
函数说明:创建数据集
Parameters:
无
Returns:
group - 数据集
labels - 分类标签
"""
def createDataSet():
#四组二维特征
group = np.array([[1,101],[5,89],[108,5],[115,8]])
#四组特征的标签
labels = ['爱情片','爱情片','动作片','动作片']
return group, labels
"""
函数说明:kNN算法,分类器
Parameters:
inX - 用于分类的数据(测试集)
dataSet - 用于训练的数据(训练集)
labes - 分类标签
k - kNN算法参数,选择距离最小的k个点
Returns:
sortedClassCount[0][0] - 分类结果
"""
def classify0(inX, dataSet, labels, k):
#numpy函数shape[0]返回dataSet的行数
dataSetSize = dataSet.shape[0]
#在列向量方向上重复inX共1次(横向),行向量方向上重复inX共dataSetSize次(纵向)
diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet
#二维特征相减后平方
sqDiffMat = diffMat**2
#sum()所有元素相加,sum(0)列相加,sum(1)行相加
sqDistances = sqDiffMat.sum(axis=1)
#开方,计算出距离
distances = sqDistances**0.5
#返回distances中元素从小到大排序后的索引值
sortedDistIndices = distances.argsort()
#定一个记录类别次数的字典
classCount = {}
for i in range(k):
#取出前k个元素的类别
voteIlabel = labels[sortedDistIndices[i]]
#dict.get(key,default=None),字典的get()方法,返回指定键的值,如果值不在字典中返回默认值。
#计算类别次数
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
#python3中用items()替换python2中的iteritems()
#key=operator.itemgetter(1)根据字典的值进行排序
#key=operator.itemgetter(0)根据字典的键进行排序
#reverse降序排序字典
sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
#返回次数最多的类别,即所要分类的类别
return sortedClassCount[0][0]
if __name__ == '__main__':
#创建数据集
group, labels = createDataSet()
#测试集
test = [101,20]
#kNN分类
test_class = classify0(test, group, labels, 3)
#打印分类结果
print(test_class)欧氏距离概念:
在欧几里得空间中,点x =(x1,...,xn)和 y =(y1,...,yn)之间的欧氏距离为
向量
的自然长度,即该点到原点的距离为
它是一个纯数值。在欧几里得度量下,两点之间线段最短。


https://blog.csdn.net/c406495762/article/details/75172850
https://zh.wikipedia.org/wiki/%E6%AC%A7%E5%87%A0%E9%87%8C%E5%BE%97%E8%B7%9D%E7%A6%BB
https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
李航《统计学习方法》