github:https://github.com/makeplanetoheaven/NlpModel/tree/master/DependencyParser
前言
由于最近在研究并尝试编写一个基于知识图谱问答的系统,并调研了一些其他类型的问答系统,如FAQ,任务型问答等,在这个过程中需要完成对所给问题进行解析,生成能够带入到知识图谱中进行查询的结构,因此,提出并编写了一个基于图的依存解析,并采用修改后Seq2Seq2模型实现的一个语义依存解析模型。对于该系统,目前主要完成了整个系统框架的构建,能够提供一定程度的问答,但是后面各个模块间的优化,算法的更新,知识图谱内容的更新仍然有很长的一段路要走。另外,如果需要,可开源相应模型代码。
1.背景知识
按我的理解,一个完整的问答系统,主要分为三个部分:1.解析;2.匹配;3.生成。其中,解析指的是对输入的句子(问题)进行处理,转换成计算机能够理解的格式;匹配指的是根据解析模块所得到的句子格式,对已有的知识(数据)进行检索或匹配,最终得到格式化的输出数据;生成指的是根据匹配模块得到的格式化输入数据,转换成人能够理解的数据格式,即句子。这三个部分又可继续进行细分,几乎包含了自然语言处理中所用到的所有知识。由于这篇文章主要关注的是第一个部分,因此主要讲解我在这一部分的相关调研及实现。
自然语言的解析过程,主要分为两个部分:浅层语义解析和深层语义解析。浅层语义解析,主要是对句子的中的单词以及句子的语法进行解析。其中,对单词的解析,主要是句子的分词,单词的词性标注(POS)。句子的分词,最早使用的是隐马尔可夫模型(HMM)对句子进行处理,随着循环神经网络(RNN)的发展,通过使用LSTM+CRF的方法对自然语言进行处理,具有较高的准确率,其中,分词,词性标注(POS),命名实体识别(NER)等一系列序列标注[1]的任务也都包含其中。近几年Seq2Seq模型的发展,对自然语言各个领域具有很大的贡献。
当把句子中的每个单词及词性区别开以后,后续就需要对句子进行解析,包括语法结构的解析以及依存句法分析。

1.1 语法结构的解析
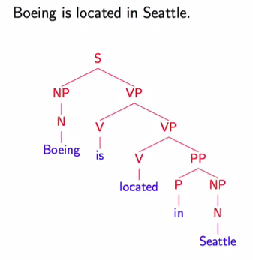
语法结构的解析,指的是对句子中的语法成分类型进行解析,最终得到一棵语法解析树,如下图所示,用于表示每个单词所属的节点类型(名词性节点NN,形容词节点ADJ,动词节点VN等),以及与其他单词所组成的成分类型(名词性短语NP,动词短语VP等)。
在语法结构的解析中,常用的方法主要有:1.上下文无关语法(Context-Free Grammer),通过定义一系列规则,规定任意两个类型节点所属的语法类型,详解[2];2.基于概率分布的上下文无关语法(Probabilistic Context-Free Grammar,PCFG),由于通过规则可生成多种类型的语法解析树,即对句子的解析存在二义性,因此,通过在常规的每条语法规则后面赋予一个概率值,对于每一棵生成的语法解析树,将其中所用规则的概率的乘积作为该语法解析树的出现概率,最终选取概率最大语法解析树即可,其中每一个语法规则的概率,需要通过训练得到,详解[2];3.考虑词汇的上下文无关语法(Lexicalized PCFG),由于PCFG中并没有考虑同一语法成分中不同词汇的先后关系(重要性),因此,在Lexicalized PCFG中引入首要词的概念,详解[3]。
1.2 依存句法分析
语法结构的解析,最终得到是一棵语法解析树,用于表示句子中各单词所属的句子成分及成分类型,而依存句法分析是对句子中各成分的依存类型进行解析,标识出句子中具有相互关联的两个单词的依存类型(主谓、动宾、间宾等)以及从属关系。通过依存句法分析,最终得到该句子的一个依存树,或依存图,介绍[4]。常用的依存分析方法,后面会进行介绍。
由语法结构解析所得到得语法解析树,以及由依存句法分析所得到依存树,在某种程度上可以进行相互转换,介绍见[5]。
2.语义依存解析
在前面一节,主要对解析中的浅层语义解析进行了介绍,接下来,会对深层语义解析,尤其是其中的语义依存分析进行讲解。
深层语义解析,主要是对句子中每个单词的语义以及句子的语义进行解析,包含了两个内容:语义角色标注和语义依存解析。
在知识图谱的架构中,一个完整的知识图谱主要由实体、每个实体所属的类型,实体所包含的属性、属性值,实体间关系构成(如果需要,可额外写一篇文章来专门介绍知识图谱及其相关算法)。因此,在基于知识图谱的问答系统中,我将语义语义角色标注理解为,通过将句子带入到知识图谱中,标注出句子中每一个单词是属于实体,类型,关系,还是属性、属性值。从而将原有的输入问题,转换成带有相应角色标注的问题,例如,
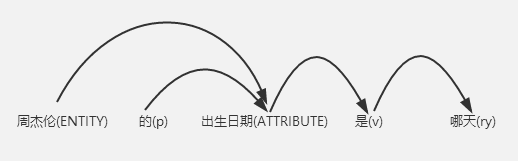
角色标注完后,我们需要做的,就是根据其标注结果,对其进行语义依存解析,得到如下的结构,并带入到知识图谱中进行匹配查找。
从上图中我们可以看到,通过解析出来的结构,从一个实体出发,带入到知识图谱中即可得到该实体所需要查找的数据。

2.1 语义依存分析详解
语义依存分析,同样是对句子中各单词的依赖关系进解析,但是与依存句法分析的主要区别在于:依存句法分析,主要是对句子中个成分间的依存关系进行解析,其更多的是关注句子中各单词之间的成分关系(如主谓关系,动宾关系等),而语义依存分析,直接跳过了对句子的成分进行分析这一步骤,直接分析句子间各单词的语义关系,换句话中,对于表达同一意思的不同结构的句子来说,其依存句法分析的结果是不一样的,但是其语义依存分析的结果是一样的,有关这两种依存分析的区别,间[6]。
无论是依存句法分析,还是语义依存分析,其所使用的依存分析算法框架都是一样的。目前用于实现依存分析主要有两种方法:1.基于转移的依存分析(Transition-Based)[7];2.基于图的依存分析(Graph-Based)[8]。
基于转移的依存分析算法,主要包含三种数据结构:1.用于缓存句子中还未进行处理的单词序列的队列buffer;2.存储转移过程中的单词序列栈stack;3.处理完毕的一系列依存弧(及依存类型)。整个转移过程包含三个动作:进栈,左移存,右依存,其具体处理过程可参考论文[7]。但是,传统的基于转移的依存分析算法,其最终得到得是一个依存树,这对依存分析存在一定限制,因此,最近几年提出的基于转移的语义依存图的解析,对依存分析进行了扩展,其详细方法,可参见论文[9]。
基于图的依存分析算法,通过使用一个Bi-LSTM来提取出句子每个单词的上下文信息,将每一个单词的上下文信息依次与其他单词的上下文信息带入到一个全连接神经网络中,来进行打分,分类其依存类型。这样的一个模型,通过考虑了整个句子的上下文信息,并对所有可能进行解析,从而得出最终的解析结果。该算法最终得到得是一个矩阵,表明每个单词与其他单词是否存在依存关系及依存类型。
与基于转移依存分析方法相比,基于图的依存分析方法能更多地区考虑句子的全局信息,得到更优的结果,但是其处理速度与基于转移相比较慢。


3.基于知识图谱的语义依存分析
到目前为止,整个自然语言解析流程基本介绍完毕,在我自己构建知识图谱问答系统中,受基于图的依存分析算法的启发,再结合Seq2Seq模型在自然语言处理中的广泛应用,提出了一种新的基于知识图谱语义依存分析模型架构,该模型在我自己的系统中测试时,具有良好的性能,且具有较快的处理速度。处理知识图谱的问答中,该模型还可应用去其他依存分析领域。
3.1 Seq2Seq
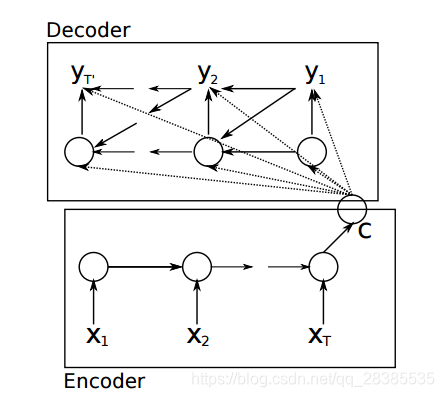
Seq2Seq模型最初的提出和应用是在机器翻译领域[10],通过将循环神经网络(RNN)应用到自编码器中,构建RNN Encoder-Decoder,从而实现处理可变长度输入输出的功能。整个模型中,Encoder通过对输入序列进行编码,输出输入序列的向量信息,再将该向量信息输入到Decoder中进行解码,得到目标输出。
通过使用使用Encoder对输入进行编码,来提高了模型的对上下文的理解能力。
3.2 基于知识图谱DependencyGraph模型实现
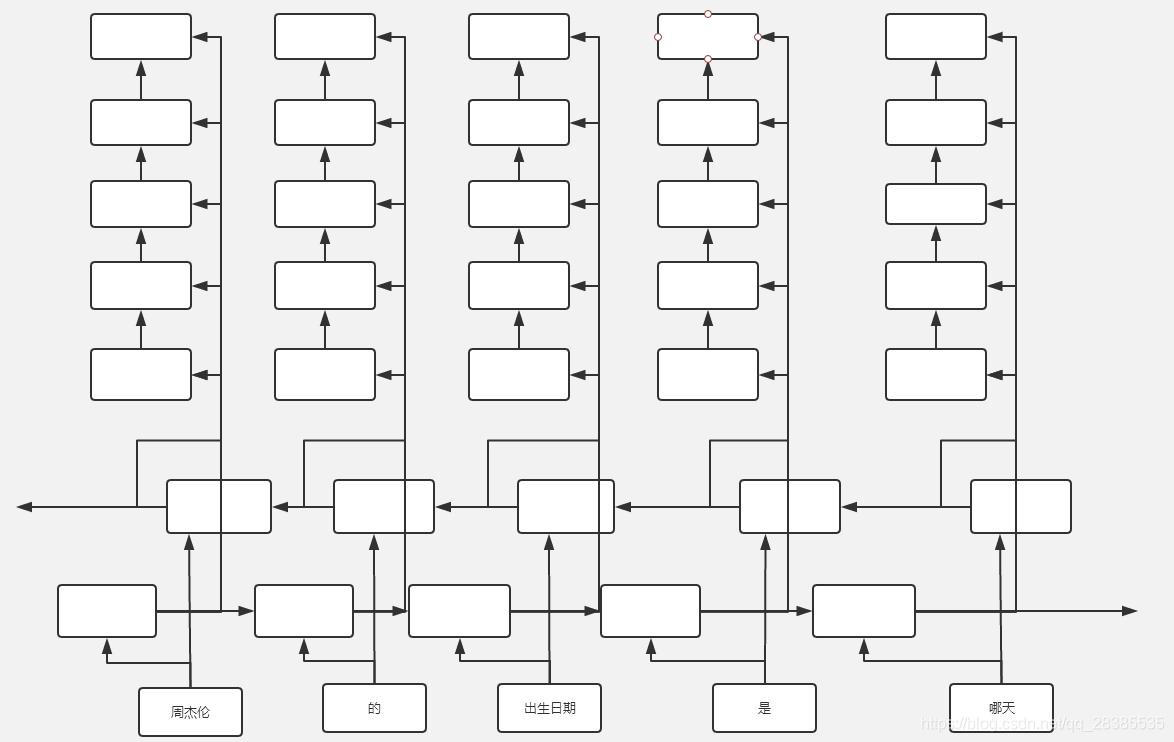
在该模型中,受基于图的依存分析的启发,并引入Seq2Seq来提高模型对输入问题语义依存的理解能力,该模型最终输出是一个依存矩阵。以第二节中所用句子为例(周杰伦的出生日期是哪天),讲解整个模型的构建及处理过程。
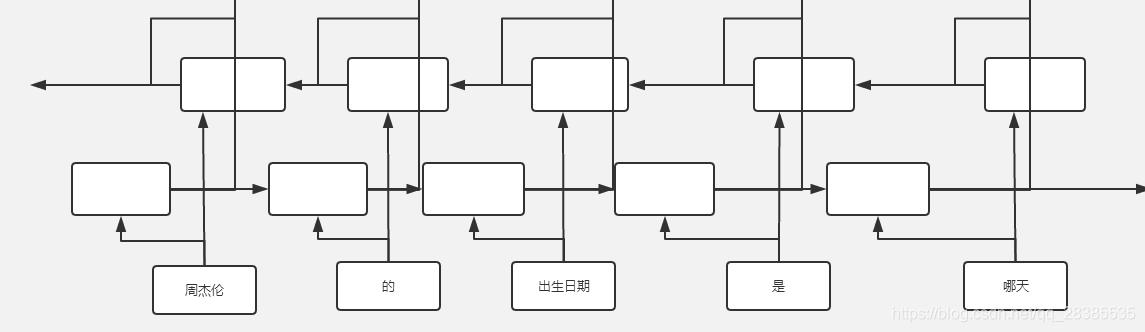
首先,在编码器(Encoder)中,通过使用一个双向LSTM来对输入信息进行编码,从而得到句子中每个单词的上下文信息。如下图所示。这个过程和基于图的依存解析一样,也使用了Bi-LSTM对输入句子中的每个单词进行建模。
然后,对于每一个单词的上下文信息,为其构建一个单向的LSTM神经网络作为其解码器Decoder,以该单词的上下文信息作为该解码器每一时刻的输入,该Decoder的初始状态,由该句子前向隐藏状态和反向隐藏状态拼接作为输入。解码器在每一时刻的输出,接一个全连接层,作为依存类型的判断,全连接层神经元的数目,即为依存类型的数目。
因此,对于一个长度为5的句子来说,需要5个单向LSTM来为每个单词构建其依存解码器。而且,对于解码器中的每个RNN来说,其长度为输入句子的长度。最终,整个模型返回一个
的矩阵,用以表明整个句子中各单词间的依存关系及其依存类型。模型的整体结构如下图所示。在知识图谱中,我只需模型去判断两个词之间是否具有依存关系,不考虑依存类型,因此,全连接层神经元数目为2。
以图中所示例句作为输入,其最终的输出结果为
[[0,0,1,0,0],
[0,0,1,0,0],
[0,0,0,1,0],
[0,0,0,0,1],
[0,0,0,0,0]]
到这里,整个模型的结构就讲解完毕了。如果需要,我可以开源该模型的代码。
参考
[1] Neural Architectures for Named Entity Recognition
[2] 自然语言处理 - 语法解析(Parsing, and Context-Free Grammars)
[3] 考虑词汇的语法解析(Lexicalized PCFG)
[4] 中文依存句法分析简介
[5] 依存语法:从短语结构树转换为依存树
[6] 依存句法分析与语义依存分析的区别
[7] Transition-Based Dependency Parsing with Stack Long Short-Term Memory
[8] Simple and Accurate Dependency Parsing Using Bidirectional LSTM Feature Representations
[9] 基于转移的语义依存图分析
[10] Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation