前言
之前的记忆网络BAM模型是取每个实体的two-hop以内的范围作为关系的候选区,因为WebQA数据集里问题基本能在two-hop以内解决,但是这样只是针对具体情况而缺乏泛华性,最近看到一些论文可以解决KBQA中的多跳问题具有一定参考性,并且这些年做多跳的还是比较少的,SimpleQA数据集精度都差不多登顶了(数据及本身有限制),隔壁用GNN系列在Multi-hop阅读理解上做的也是风生水起,KBQA也可以考虑一下多跳的问题了。
多跳问题就是问句中包含多个关系甚至多个实体,个人认为一方面可能是用到多个三元组推理,另一方面也可能只是要用到多个三元组来解决问题比如 徐峥和黄渤共演的电影有哪些? 这种就是推理,六小龄童在西游记中扮演了那个角色? 这种就是需要用到多个三元组去回答。这里我看到的相关论文是解决后者的。
当时刚看完记忆网络第一反应是用这种形式的网络结构去不断做回馈和再匹配来得到下一步答案,就跟端到端那篇做阅读QA的可视化效果那种解释来用到KBQA同样适用(如下图),但是有个很大的问题就是KBQA没有上下文只有一句问句,用关系表示去做映射效果不一定会很好,更不用说在open-domain里做了。

Enhancing Key-Value Memory Neural Networks for Knowledge Based Question Answering
这是NAACL2019的一篇论文,之前也看到了但是没有细看,这里的方法就是看完记忆网络系列的文章后水到渠成而来的结果,论文的贡献点是解决KBQA中的三种问题:
- 多跳问题怎么去做匹配
- 搜索多个候选三元组时为了效率怎么及时停下搜寻
- 不需要semanic parsing那样大量的人工标注但也能借鉴其中的灵活度
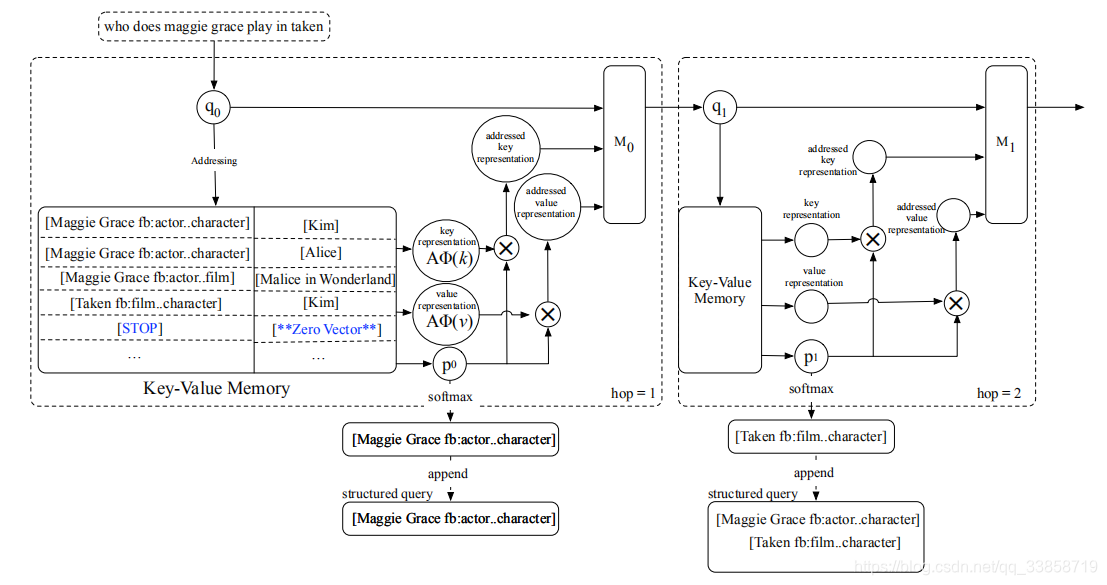
1、多跳推理:
关于KV-MemNN之前的博客已经讲过了,这里与BAM不同的是它将问题的表示向量
做了更新重新放回网络再做二次reasoning:
其中
是对于问题
和每个
的相似度计算,这里用的点积和softmax归一化,
是对于Value的寻址也就是答案的加权和,
是一个第
个hop更新
的参数矩阵,。
传统做法中可能会把最后一个hop的
作为最后的选择answer的排序依据,但是会有一个题多答、最后hop可能无法表征全局的推理过程这些问题,因此需要之前hop的
的信息来做综合考虑,所以就用了一个答案表示
来计算:
,然后就都是之前IR那种方法得到最后的Answer Representation,命名为AR;另外文中也提出在每一个hop把
高的对应
取出来组成一个key序列
,命名为SQ(Strucured Query)这个就是为了解决一题多答的情况,因为一题多答的三元组中答案是在变化的,只有关系是一样的,这里SQ就能保留所有高票得到的关系,但是要取到哪里结束也是要考虑的这是下面要讲的。文中也对比了AR和SQ这两种做法的性能,理所应当是SQ效果更好,因为它解决了一题多答的问题并且相较于AR的最后输出,SQ更关注全局信息。但是SQ使用起来最大的问题就是并没有标注,这里文中采用了在训练时使用AR,测试时加入SQ的做法,loss函数如下,其中
是target,
是prediction vector
2、STOP 策略
上文中令人在意的是提前停止读取记忆
的做法,文中命名为 STOP key ,是一个全零向量。为了在搜寻有用的key时能避免重复、无用时及时停下,具体效果如下:
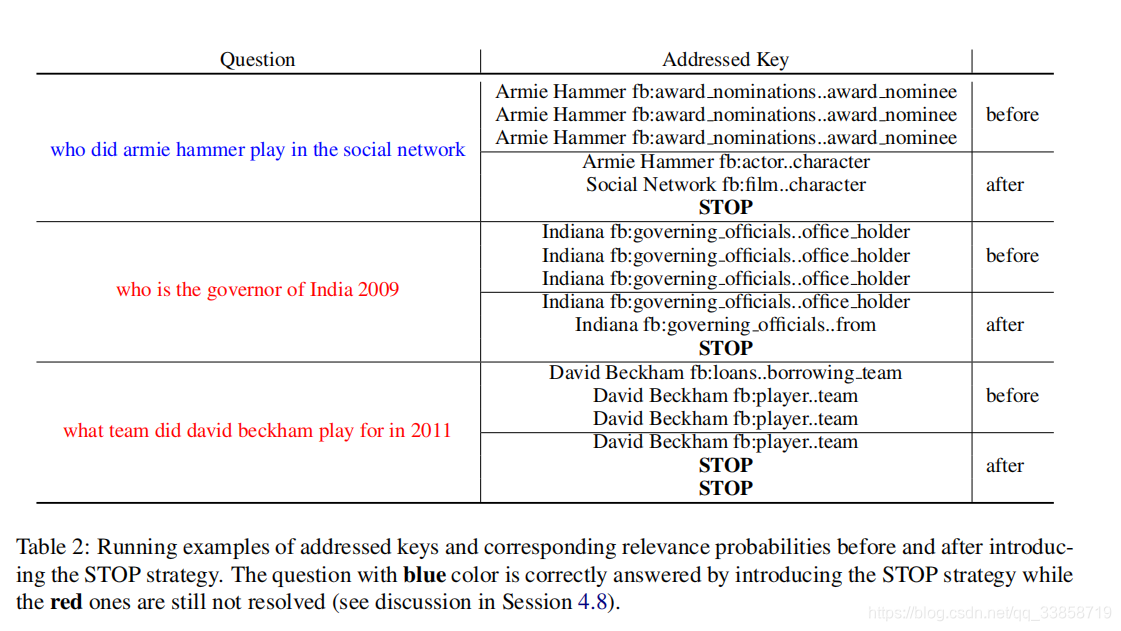
但是文中没有详细说明这个STOP key是怎么训练的,只是强调只用了原始QA对来得到并没有加入人工标注,这一点可以参考文中提到的2017一篇做MRC的Reasonet,在多伦推理中加入强化学习来动态得到推理的轮数,具体实现还要看作者后期开源代码的情况,这里只能暂时搁置了。
3、对比实验
文中进行了大量消融对比实验如下图:

表明KV-MemNN和STOP、SQ组合的模型表现最好。

表明hop值取3是基本就能完成大多数问答,再叠加无意义。
总结:KV-MemNN的正确使用方式以及SQ、STOP key这两种trick都是值得深入研究的,希望作者能早点开源好多细节地方论文讲的不是很明白,私信给北大的冯岩松老师回复说下半年可能会开源,期待。另外就是令人在意的error analysis部分,实体链指由于是使用别人的结果但是现在这部分的表现依然不够出色,还有就是问题的语境不丰富导致问题在关系检测的时候出错率很高,最后就是STOP key在对于需要推理判断的问题会有问题,比如who is the governor of India 2009不能考虑到2009这个信息、who is the mother of prince michael jackson在只有“parents”这个信息时无法推断女性parent的问题,这个可能就需要数据库本身的完善了。