前言
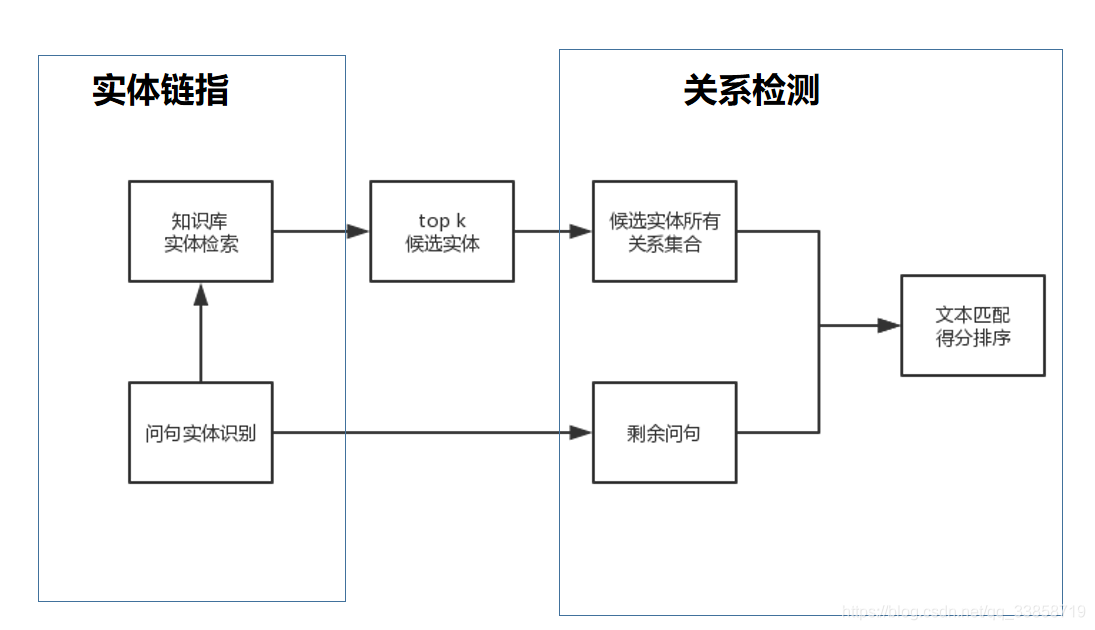
这次主要是针对《Question Answering over Freebase via Attentive RNN with Similarity Matrix based CNN》作为入门。其余文章都是通过这篇baseline的引用及被引用来调研。这些论文对于KBQA的解决方案都是从向量建模入手,把问题和候选答案都映射到一个低维空间,得到它们的分布式表达(Distributed Embedding),通过训练数据对该分布式表达进行训练,使得问题向量和它对应的正确答案向量在低维空间的关联得分(通常以点乘为形式)尽量高。当模型训练完成后,则可根据候选答案的向量表达和问题表达的得分进行筛选,找出得分最高的作为最终答案。他们都使用的SimpleQA这个数据集,总量10w条,都是一些单实体一跳的简单问答。这些框架差不多都是两步走,如下图:
AR-SMCNN
Question Answering over Freebase via Attentive RNN with Similarity Matrix based CNN ACL2018
KBQA业界成熟的做法是先将问题和知识库中的三元组联合编码至统一的向量空间,然后在该向量空间内做问题和候选答案间的相似度计算。该类方法简单有效,可操作性比较强,然而忽视了很多自然语言词面的原始信息。本文的创新点在于AR-SMCNN使用 RNN 的序列建模本质来捕获语义级关联,并使用注意机制同时跟踪实体和关系。同时,文中使用基于 CNN 的相似矩阵和双向池化操作建模数据间空间相关性的强度来计算词语字面的匹配程度。
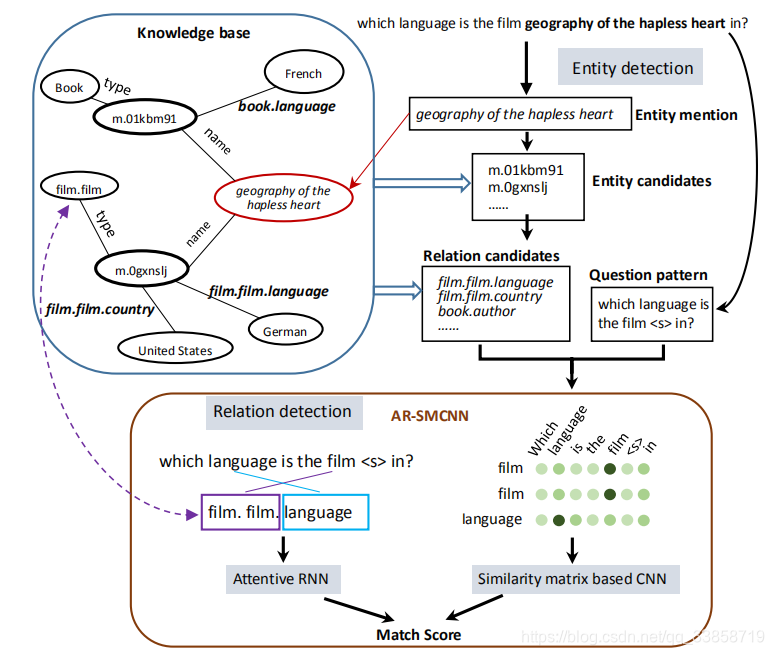
KB三元组(subject, relation, object),简写为(s, r, o)描述了一个fact,而KBQA的任务就是给定一个问题,预测(s,r),只要s,r都预测对了,就可以直接得到answer,即o。根据这些推断,KBQA问题可以分成以下两个步骤:
1、给定问题Q,找出entity mention X,然后在KB中找到所有与X一致的实体,组成实体集合E,则E中所有实体都有相同的实体名。
2、KB中所有与E中实体相连的关系组成关系集合R,先把问题Q中的X用
替换得到question pattern P,然后把P与R中所有关系进行比对并打分,score最高的就视为最终结果。
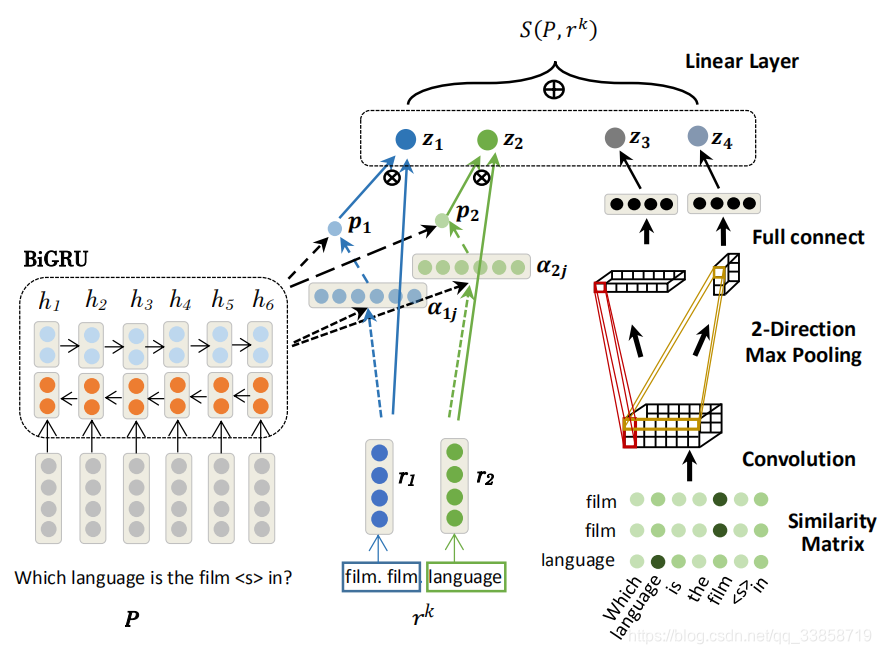
所以问题的关键就在于每个关系与问题的匹配,模型从字面表达、语义两个层面进行建模,输入是经替换 mention 后的问题模版(pattern)P 和候选关系
。模型左边的部分是结合了 attention 机制的 BiGRU,用于从语义层面进行建模,得到P和r的表示之后,就直接相互点乘来得到它们的相似度。右边的部分是CNN上的相似性矩阵M,在这里用的cosine来获取M,用于从字面角度进行建模,最后用一个双向max-pooling层,双向的意思就是分别从feature map的长和宽两个方向进行最大池化。最终将特征
连接在一起并通过线性层得到最终的候选关系分数
。
其中
的计算公式如下:
总结
- 虽然是single-relation问题,但可以用来做multi-relation
- 将relation分成两部分训练embedding,如 , 表示了subject的类型, 则表示了subject和answer的关系。
HR-BiLSTM
上一篇中作为baseline之一且表现最好的模型之一,本文提出了一种基于不同粒度对关系和问题进行文本匹配的关系检测的模型,并将这种关系检测的模型应用到 KBQA 中,通过实体连接和关系检测模块的互补来提高整体的准确率。本篇论文的的主要重点是改进关系检测。在大多数一般的关系检测任务中,目标关系的数量是有限的。相比之下,KBQA关系检测有以下不同之处:包含了更大数量级的关系类型;训练数据中可能存在一些unseen relations;对于多关系的KBQA任务,需要预测一个关系链而不是单一的关系。
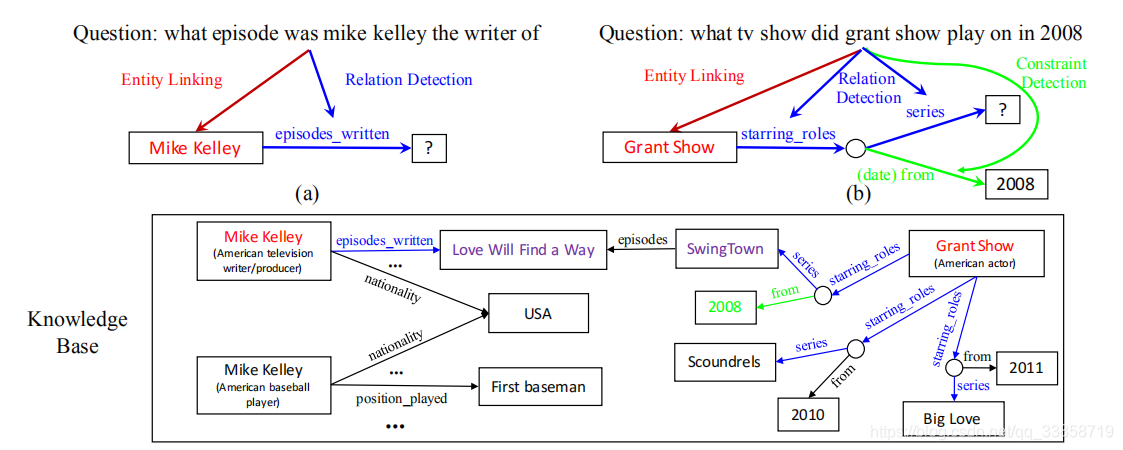

对于KB的关系序列,本文使用了relation-level和word-level两种粒度,前者每个关系名称被视为一个唯一的标记,使用预先训练的关系嵌入。(参考15年的一篇论文《Large-scale Simple Question Answering with Memory Networks》)。这种方法存在的问题是,由于训练数据有限,如果关系名称不在训练数据中,则难以将问题与关系名称进行匹配,存在着低关系覆盖的问题,因此不能很好地推广到大量的开放领域关系。后者将关系名称分解为序列。将关系看作是来自标记的关系名称的一个词序列,将关系检测看作为sequence matching and ranking任务。它有更好的泛化性,但缺乏原始关系名称的全局信息。
关系检测被作为一个文本匹配问题,即计算问题文本和不同关系文本的相似度,然后根据相似度对关系进行排序。本文提出了 HR-BiLSTM 模型来计算问题文本和关系文本的相似度,其结构如下:
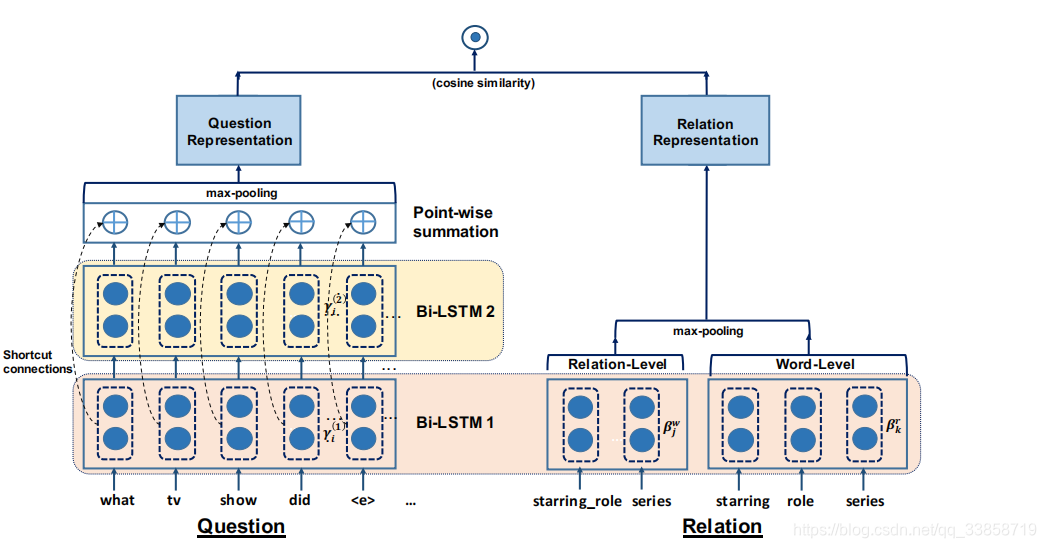
左半部分是问题的向量表示模块,主要的方法是使用 stacked BiLSTM 提取得到问题的不同粒度的表示,然后通过残差连接融合 stacked BiLSTM 中不同层次提取得到的隐藏层表示,最后通过 max pooling 得到定长的问题的向量表示。模型的右半部分是关系的向量表示模块,关系文本对应的 relation-level(整个关系文本作为一个t oken)表示和 word-level(关系文本中的每一个词语作为一个 token)表示分别被两个不同的 BiLSTM 处理,得到对应的隐藏层表示,之后通过 max polling 得到定长的关系表示。问题和关系的相似度可以使用问题向量表示和关系向量表示之间的余弦距离表示,训练的损失函数是 rank loss。
算法主要分为以下四步:

总结
- 关系检测在KBQA中的重要性,本文在多跳的问答上也能表现较好
- BiLSTM加入残差,充分利用各个层次的信息
- 利用实体链接和关系检测的集成相互促进性能
TSHCNN
这篇可以说是这两年做的最好的end2end的方法了,直接用Solr检索200个候选三元组,以BM作为排序评分,再把问题和候选用fasttext做embedding输入Siamese网络,只有后面这一个网络需要训练。另外文中也提到一些有效的负样本生成的方法,对于最终的实验结果也有很好的提升。
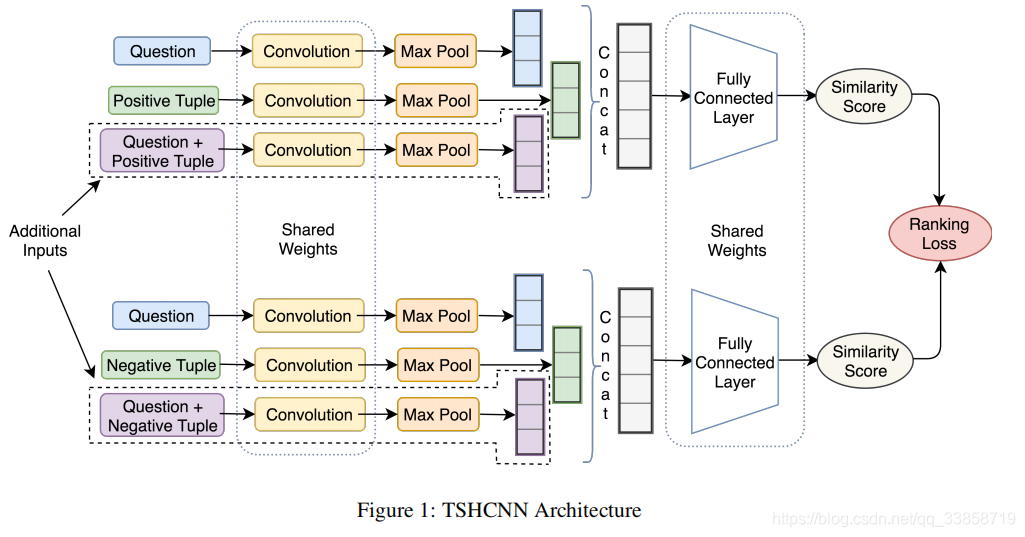
三种输入:问句、候选(正负)以及两者的拼接这个网络只用到了CNN,所有层都共享参数,一方面减少计算复杂度,另一方面也增大类间距缩小类内距。由于问题问法的形式多样化,一种问题可能有多种问法,所以这种网络的优势更明显。这里也借鉴了图像检索的相关算法。loss函数如下:
文中提到他们用了10个很有效的负样本,其中5个是将正样本中三分之二信息替换成负样本的,另外5个是Solr检索出的topk中距离正样本最近的5个负样本。
总结
- 端到端能一定程度上避免两个步骤的错上加错的情况
- 负样本构造手段值得借鉴
- 答案也可以作为模型输入之一,毕竟他和subject、predicate都是有语义关系的