版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
何为拓扑排序
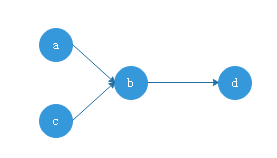
如图所示,在图中顶点a指向顶点b,表示a先于b执行,b依赖于a,而d依赖于b,所以想要正常执行输出顺序必须是a->c->b->d或者c->a->b->d.这就是拓扑排序。拓扑排序的图必须是有向无环图,而不能出现循环依赖的情况。
拓扑排序的实现
拓扑排序有两种实现方式分别是kahn算法和DFS深度优先遍历算法
Kahn算法
kahn算法在定义图的时候,如果s需要先于t执行,那就添加一条s指向t的边,因此如果某个顶点的入度为0,即没有任何顶点必须先于这个顶点执行,这顶点就可以执行。先从图中找出一个入度为0的顶点,并输出出来,然后删除这个顶点,对应到代码就是这个顶点指向的顶点入度都减1.重复这个步骤,直到所有顶点都被输出,最后的序列就是满足局部依赖关系的拓扑排序。
代码:
package com.study.algorithm.graph;
import java.util.LinkedList;
import java.util.Queue;
/**
* @Auther: JeffSheng
* @Date: 2019/9/30 13:52
* @Description: 无向图
*/
public class Graph {
/**
* 顶点的个数
*/
private int v;
/**
* 邻接表
*/
private LinkedList<Integer> adj[];
public Graph(int v){
this.v = v;
adj = new LinkedList[v];
for (int i = 0; i < v; i++) {
adj[i] = new LinkedList<>();
}
}
public LinkedList<Integer>[] getAdj() {
return adj;
}
/**
* 有向图,s指向t
* @param s 起始顶点
* @param t 终止顶点
*/
public void addEdgeByKahn(int s,int t){
// s先于t,边s->t
adj[s].add(t);
}
private void print(int[] prev, int s, int t) { // 递归打印 s->t 的路径
if (prev[t] != -1 && t != s) {
print(prev, s, prev[t]);
}
System.out.print(t + " ");
}
}
package com.study.algorithm.sort;
import com.study.algorithm.graph.Graph;
import java.util.LinkedList;
/**
* @Auther: JeffSheng
* @Date: 2019/10/22 15:08
* @Description:
* 拓扑排序
*/
public class TopoSort {
/**
* 利用kahn算法实现拓扑排序
*/
public void topoSortByKahn(int v,Graph graph) {
LinkedList<Integer>[] adj = graph.getAdj();
// 统计每个顶点的入度
int[] inDegree = new int[v];
for (int i = 0; i < v; ++i) {
for (int j = 0; j < adj[i].size(); ++j) {
// i->w 获取顶点i指向的顶点w并统计w的入度
int w = adj[i].get(j);
inDegree[w]++;
}
}
//遍历所有顶点,如果入度为0放入队列
LinkedList<Integer> queue = new LinkedList<>();
for (int i = 0; i < v; ++i) {
if (inDegree[i] == 0){
queue.add(i);
}
}
while (!queue.isEmpty()) {
int i = queue.remove();
System.out.print("->" + i);
/**
* 重新遍历所有顶点,获取集合中在队列中已被移出的顶点i的出度k,
* 因为顶点i被删除,所以k入度减一,判断为0放入队列
*/
for (int j = 0; j < adj[i].size(); ++j) {
int k = adj[i].get(j);
inDegree[k]--;
if (inDegree[k] == 0){
queue.add(k);
}
}
}
}
public static void main(String[] args) {
TopoSort topoSort = new TopoSort();
Graph graph = new Graph(4);
graph.addEdgeByKahn(0,2);
graph.addEdgeByKahn(1,2);
graph.addEdgeByKahn(2,3);
topoSort.topoSortByKahn(4,graph);
}
}
DFS深度优先遍历

算法的核心是构造逆邻接表,比如s->t表示s依赖于t,s后于t执行。递归处理每个顶点,对于顶点v,我们先输出它可达的所有顶点再输出自己。
代码:
public void topoSortByDFS(int v,Graph graph) {
LinkedList<Integer>[] adj = graph.getAdj();
// 先构建逆邻接表,边s->t表示,s依赖于t,t先于s
LinkedList<Integer> inverseAdj[] = new LinkedList[v];
// 申请空间
for (int i = 0; i < v; ++i) {
inverseAdj[i] = new LinkedList<>();
}
// 通过邻接表生成逆邻接表
for (int i = 0; i < v; ++i) {
for (int j = 0; j < adj[i].size(); ++j) {
// i->w
int w = adj[i].get(j);
// w->i
inverseAdj[w].add(i);
}
}
boolean[] visited = new boolean[v];
// 深度优先遍历图
for (int i = 0; i < v; ++i) {
if (visited[i] == false) {
visited[i] = true;
dfs(i, inverseAdj, visited);
}
}
}
private void dfs(int vertex, LinkedList<Integer>[] inverseAdj, boolean[] visited) {
for (int i = 0; i < inverseAdj[vertex].size(); ++i) {
int w = inverseAdj[vertex].get(i);
if (visited[w] == true){
continue;
}
visited[w] = true;
dfs(w, inverseAdj, visited);
}
// 先把vertex这个顶点可达的所有顶点都打印出来之后,再打印它自己
System.out.print("->" + vertex);
}
时间复杂度分析
kahn算法的是时间复杂度为O(V+E)
DFS的时间复杂度是O(V+E)
V表示顶点个数,E表示边的个数