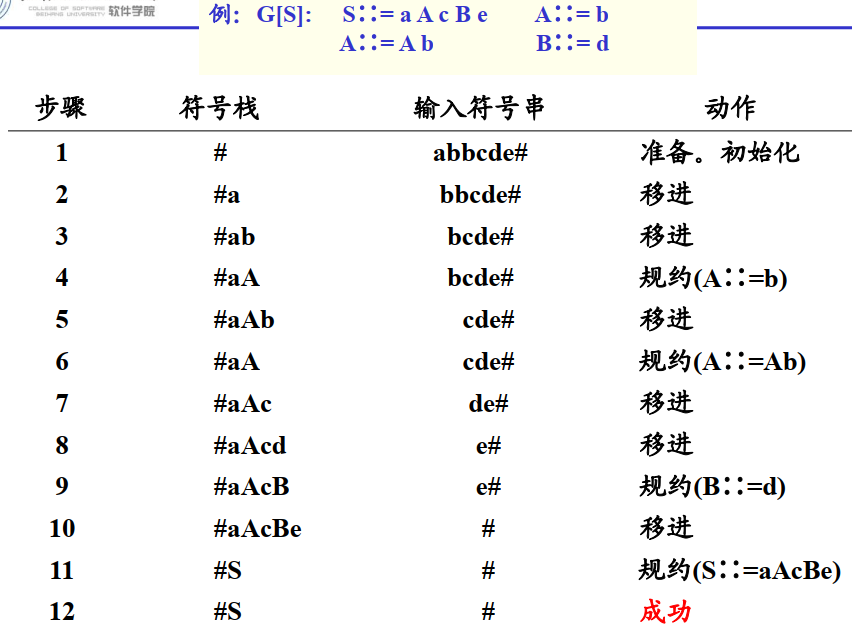
自底向上分析
1.移进-规约分析(自底向上的一般过程,存在缺陷)
准备工作:
一个符号栈、一个待分析的符号串#xxxxx#
要点:
初始状态
仅将最左侧#移进符号栈
之后
每次根据符号栈的情况在两个操作之间二选一:
- 移进
- 规约
如果当前符号栈中没有形成当前句型新的句柄,将符号串的一个字符移进(自左向右依次)
如果当前符号栈中形成了当前句型新的句柄,则规约——弹出句柄并将得到的非终结符入栈
重复这个过程
结束
最终最终符号栈只剩下#和识别符号,则分析成功,否则失败
注意
- 句柄一定位于栈顶。若不在栈顶,该句柄应该在之前就已经被规约才对
栈内符号串+未处理输入符号串=当前句型
上述方法并没有给出识别句柄的有效算法,取而代之的
识别句柄的依据是看栈顶符号串是否形成规则的右部,
但这种方法不一定正确。因为不能认为:对句型 xuy 而言,若有U∷ = u,即
U=>u 就断定u是简单短语, u 就是句柄,而是要同时满足
Z=*> xUy。【导致这种情况的本质原因是,只给一个静态的句型和文法,严格意义上是无法确定短语的,见https://www.cnblogs.com/Ivan-Luo/p/11694447.html。短语的定义是,或者说,有一个规则A::=b,某个句型中恰好有b,但不能保证用A去规约这个b之后得到的仍是该文法的句型。】
算符优先分析
适用于上下文无关文法