原文链接:https://arxiv.org/abs/1901.10444
发表在:ICLR 2019
--------------------------------------------------------------------------------------------------------------------------------------------------------------------
介绍了3中sentence嵌入的结构(RANDOM SENTENCE ENCODERS),
- Bag of random embedding projections
- Random LSTMs
- Echo State Networks
思路:利用预训练的word embedding作为输入,然后句子的encoder不进行训练(i.e., 预先随机初始化),接着加一层线性层,利用logistic regression classifier即可。
BAG OF RANDOM EMBEDDING PROJECTIONS (BOREP)
随机初始化bag-of-embeddings的权重W,
![]()
每个元素随机初始化,

我们可以得到句子的表示
![]()
fpool 为pooling函数, 可以是max pooling 或者 mean pooling. 然后再接一个非线性函数,比如 Relu(h)=max(0, h).
RANDOM LSTMS
同样的,LSTM的权重矩阵随机初始化为,
d为LSTM的hidden size. 所以可以得到句子的表示,
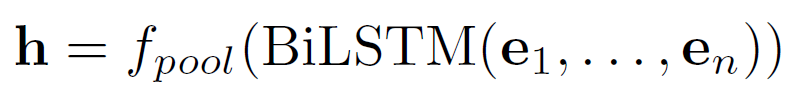
ECHO STATE NETWORKS
ESN可以表示为下面的形式,
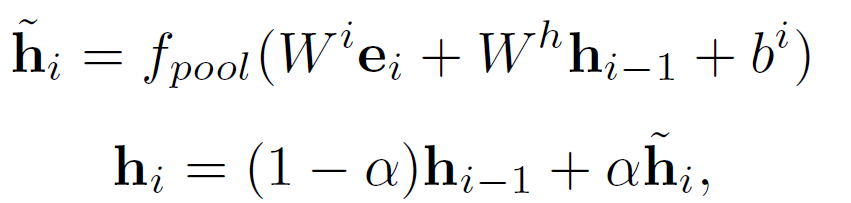
这里,同样使用了双向的ESN,最后可以得到句子的表示,
![]()
直接看作者的结论
