什么是冒泡排序?
1 前言
从本篇开始,开始一系列排序算法的博客,经常看到面经中会手写什么排序算法,学起来!今天首先开始学习的是冒泡排序!
2 什么是冒泡排序?
2.1 名称理解
- 从名称理解一波:冒泡排序,冒泡?相信大家喝汽水饮料的时候会发现这种冒泡的现象,见下图:为什么会冒泡?因为组成小气泡的二氧化碳比水轻,所以小气泡可以一点一点向上浮动!那冒泡如何排序呢?这么想,如果每次将list中最大值的都冒泡到最右边,这样是不是就可以实现升序了?这就是冒泡排序朴素的思想!

2.2 动图理解
- 有个动图解释冒泡排序特别好:
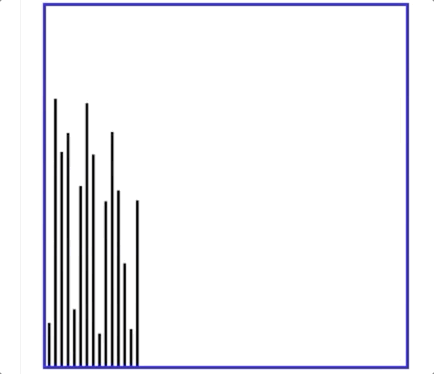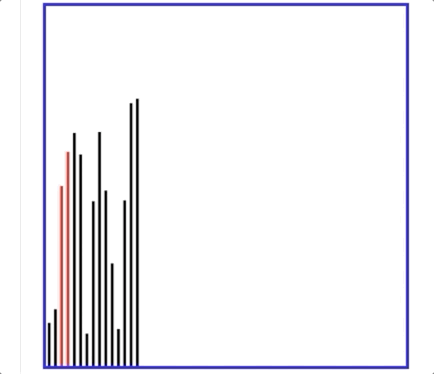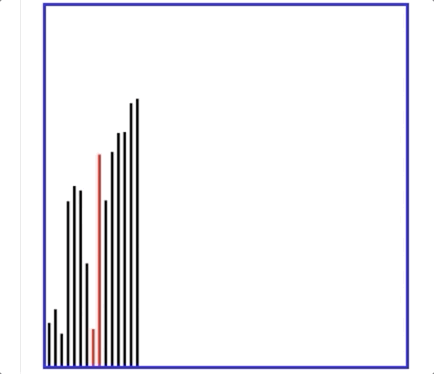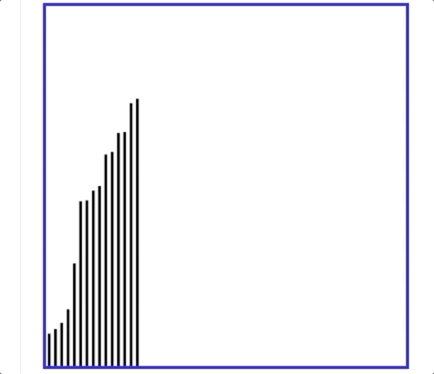
即每次都是最大的元素冒泡到最右边,然后下一次是最大的,直至全都排序ok!
(顺便安利一下mac做gif动图的免费神器:GIPHY CAPTURE)
2.3 单次循环遍历图片理解
- 另外下图可以解释冒泡排序一次遍历的过程:即最大值冒泡到最右边!然后剩下的过程就是不断重复这个操作,会把第二大的移动到最右边,再依次,其中具体的做法是相邻两两元素进行对比,大的数往右移动就好!

3 代码实现
3.1 递归
- 一层循环 两两元素之间的对比 如果a>b 则两个元素位置对换!
- 用一个计数变量count 判断是否要提前终止循环!
- 如果排序不变了就不需要再重新遍历 直接返回排序后的list!
- 如果排序变化了继续运用递归处理!
def bubble_sort_old(alist):
# 顺序表实现
count = 0 # 计数用来判断排序是否发生了变化
for i in range(len(alist)-1):
if alist[i] > alist[i+1]:
count += 1
# 变换位置
alist[i], alist[i+1] = alist[i+1], alist[i]
if count != 0:
# 如果变化了 递归处理
return bubble_sort_old(alist)
else:
# 没有变化 则返回该list
return alist
a = [3,2,6,4,7,9,1]
bubble_sort_old(a)
[1, 2, 3, 4, 6, 7, 9]
3.2 双层循环
- 一层循环 两两元素之间的对比 如果a>b 则两个元素位置对换!
- 外层加一个循环,即什么时候终止呢?根据冒泡排序每一次都是最大的值转移到了最右边,所以每次其实遍历都可以少走一步!
- 同时用一个计数变量count 判断是否要提前终止循环!不用每次都双层循环!
def bubble_sort(alist):
# 顺序表实现
n = len(alist)
# 到底走多少次 再加一层循环 n-1次
for j in range(n-1): # 产生n-1个数 即进行n-1次循环
# 这时候可以i不用每次全部走完 每次少走一步!因为最大的数在最外边了!
count = 0
for i in range(0, n-j-1):
# 班长从头走到尾
if alist[i] > alist[i+1]:
count += 1
alist[i], alist[i+1] = alist[i+1], alist[i]
if count == 0:
break
return alist
# i 0~n-2 range(0,n-1) j=0
# i 0~n-3 range(0,n-1-1) j=1
# i 0~n-4 range(0,n-1-2) j=2
li = [54,26,93,17,77,31,44,55,20]
# 老师的方法
%time
import time
t0 = time.time()
print(bubble_sort(li)[:10])
t1 = time.time()
print('所需时间为: %.2f s' % (t1-t0))
CPU times: user 3 µs, sys: 1e+03 ns, total: 4 µs
Wall time: 6.91 µs
[17, 20, 26, 31, 44, 54, 55, 77, 93]
所需时间为: 0.00 s
# 自己的方法
%time
t0 = time.time()
print(bubble_sort_old(li))
t1 = time.time()
print('所需时间为: %.2f s' % (t1-t0))
CPU times: user 4 µs, sys: 0 ns, total: 4 µs
Wall time: 7.87 µs
[17, 20, 26, 31, 44, 54, 55, 77, 93]
所需时间为: 0.00 s
3.3 增大数据量看是否会有差异
li2 = []
for i in range(10000):
li2.append(np.random.randint(10000))
li2[:10]
[3124, 3583, 4114, 5732, 4735, 5489, 7070, 4578, 2352, 155]
# 老师的方法
%time
import time
t0 = time.time()
bubble_sort(li2)[:10]
t1 = time.time()
print('所需时间为: %.2f s' % (t1-t0))
CPU times: user 3 µs, sys: 1e+03 ns, total: 4 µs
Wall time: 5.72 µs
所需时间为: 10.59 s
# 自己的方法
%time
t0 = time.time()
bubble_sort_old(li2)[:10]
t1 = time.time()
print('所需时间为: %.2f s' % (t1-t0))
CPU times: user 2 µs, sys: 0 ns, total: 2 µs
Wall time: 6.2 µs
所需时间为: 0.00 s
感觉还是递归会更快一些!
参考
- b站视频:https://www.bilibili.com/video/av53583801/?p=35
- 书籍:漫画算法