参考:xf_mao 雷隐隐
介绍:
从直观上看,卷积的过程相当于将图片“浓缩了”,当然在浓缩的过程中,厚度是可以变的。

上图中,黑色的板子就是输入的图片,橙色的板子就是卷积“浓缩”后的图片,绿色的小色块就是卷积核,也就是“抹布”。当然,如果抹布能做到一步一停并且采用“SAME”模式的话,那么浓缩后的大小就不会变。值得注意的是,卷积之后的结果厚度是用户自己指定的,至于说这个厚度有什么意义,理解:厚度的每一层都类似于某一频率和振幅的正弦波,而多个不同的正弦波理论上讲是可以拟合任意复杂的波形,所以多种不同的卷积结果,理论上也能够拟合比较复杂的特征提取方案的。
————————————————————————————————————————————————————
函数:
conv2d(input,
filter,
strides,
padding,
use_cudnn_on_gpu=True,
data_format="NHWC",
dilations=[1, 1, 1, 1],
name=None)
除去name参数用以指定该操作的name,与方法有关的一共七个参数:
input:
指需要做卷积的输入图像,它要求是一个Tensor,具有[batch, in_height, in_width, in_channels]这样的shape,具体含义是[训练时一个batch的图片数量, 图片高度, 图片宽度, 图像通道数],注意这是一个4维的Tensor,要求类型为float32和float64其中之一filter:
相当于CNN中的卷积核,它要求是一个Tensor,具有[filter_height, filter_width, in_channels, out_channels]这样的shape,具体含义是[卷积核的高度,卷积核的宽度,图像通道数,卷积核个数],要求类型与参数input相同,有一个地方需要注意,第三维in_channels,就是参数input的第四维strides:卷积时在图像每一维的步长,这是一个一维的向量,长度4
padding:
string类型的量,只能是”SAME”,”VALID”其中之一,这个值决定了不同的卷积方式。是卷积核在边缘处的处理方法,描述起来比较复杂,一张图比较直观,直接上图: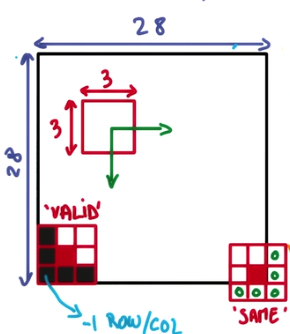 可以看到,VALID模式在边缘采取的是“不及(即不考虑)”的方法,而SAME则是“过”的策略,两者效果孰优孰略取决于你的数据在边缘有没有什么重要信息。
可以看到,VALID模式在边缘采取的是“不及(即不考虑)”的方法,而SAME则是“过”的策略,两者效果孰优孰略取决于你的数据在边缘有没有什么重要信息。use_cudnn_on_gpu:
bool类型,是否使用cudnn加速,默认为truedata_format:
string类型,只能是"NHWC","NCHW"。默认为"NHWC"。指定输入和输出数据的数据格式。根据默认格式"NHWC",数据按以下顺序存储: [批次,高度,宽度,通道]。或者,格式是“NCHW”,数据存储顺序为:[批次,渠道,高度,宽度]。(翻译自函数声明注释)dilations:
一个可选的`ints`列表。 默认为[1,1,1,1]。一维长度张量4.每个`input`维度的膨胀系数。 如果设置为k> 1,则每个该维度上的过滤器元素之间会有k-1个跳过的单元格。 维度顺序由`data_format`的值决定,详见上文。 在Dilations中批次和深度尺寸必须为1(原文为:"Dilations in the batch and depth dimensions must be 1"此句没看懂)。(翻译自函数声明注释)
结果返回一个Tensor,这个输出,就是我们常说的feature map