先解释一下tf.nn.conv2d函数:
tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, data_format=None, name=None):
给定一个input的张量[batch, in_height, in_width, in_channels]和一个过滤器 / 内核张量 [filter_height, filter_width, in_channels, out_channels]后,执行以下操作:
1.展平filter为一个形状为[filter_height * filter_width * in_channels, output_channels]的二维矩阵。
2.从input中按照filter大小提取图片子集形成一个大小为[batch, out_height, out_width, filter_height * filter_width * in_channels]的虚拟张量。3.循环每个图片子集,右乘filter矩阵。
除去name参数用以指定该操作的name,与方法有关的一共五个参数:
第一个参数input:指需要做卷积的输入图像,它要求是一个Tensor,具有[batch, in_height, in_width, in_channels]这样的shape,具体含义是[训练时一个batch的图片数量, 图片高度, 图片宽度, 图像通道数],注意这是一个4维的Tensor,要求类型为float32和float64其中之一
第二个参数filter:相当于CNN中的卷积核,它要求是一个Tensor,具有[filter_height, filter_width, in_channels, out_channels]这样的shape,具体含义是[卷积核的高度,卷积核的宽度,图像通道数,卷积核个数],要求类型与参数input相同,有一个地方需要注意,第三维in_channels,就是参数input的第四维
第三个参数strides:卷积时在图像每一维的步长,这是一个一维的向量,长度4
第四个参数padding:string类型的量,只能是"SAME","VALID"其中之一,这个值决定了不同的卷积方式(后面会介绍)
第五个参数:use_cudnn_on_gpu:bool类型,是否使用cudnn加速,默认为true
结果返回一个Tensor,这个输出,就是我们常说的feature map,shape仍然是[batch, height, width, channels]这种形式。
但是,我想说的并不是这些,而是:
Implementing convolution as a matrix multiplication
也就是上面红色字体的实现:

CNN中的卷积操作

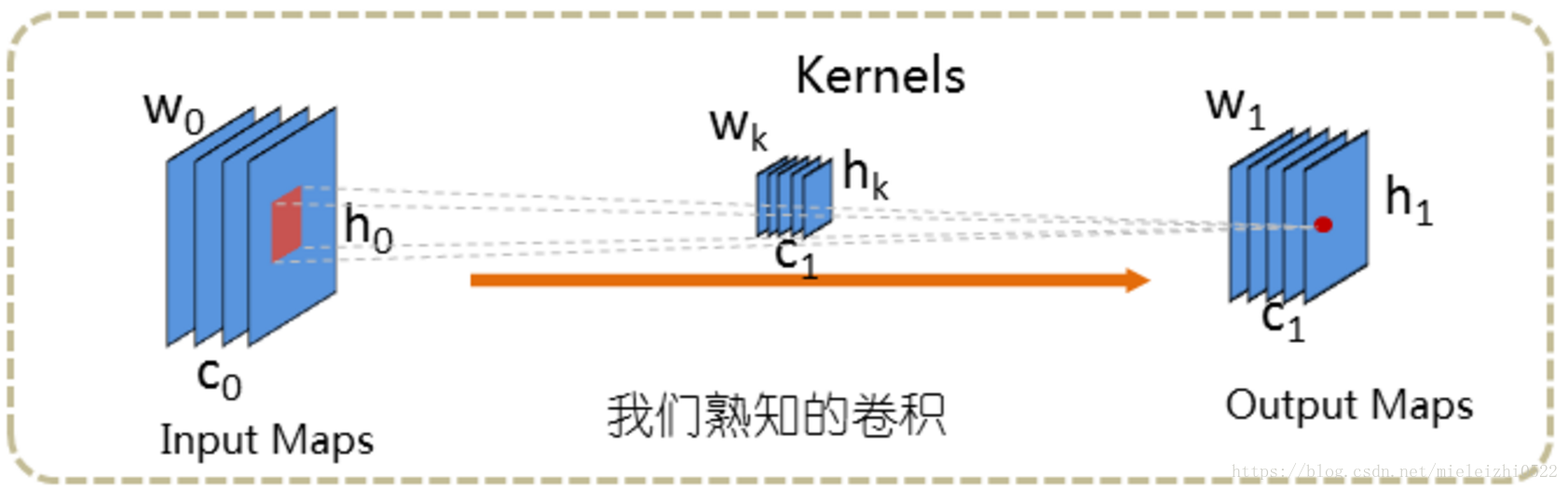
而:
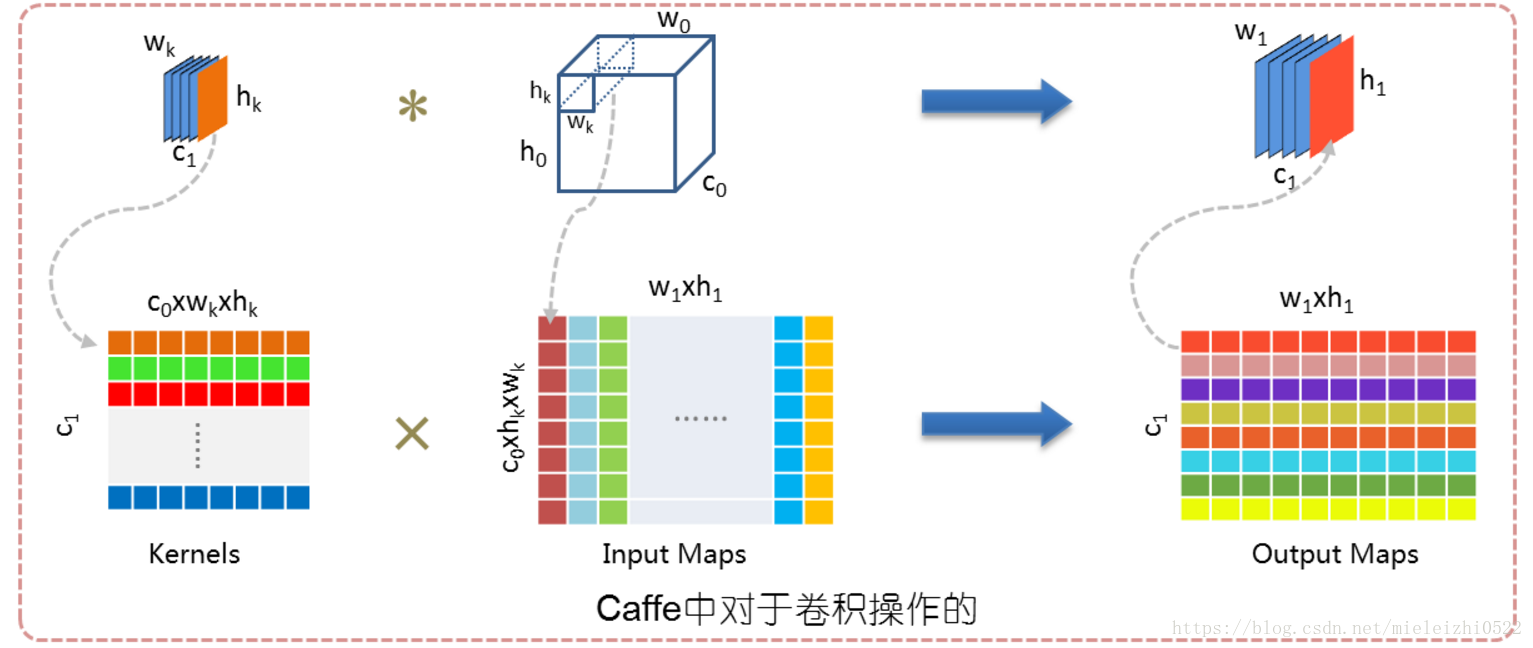
下图为一个具体的例子,看懂下面这个图应该就会清楚上面的做法。

而,刚才介绍的tf.nn.conv2d()里的卷积操作个这个是类似的,只是旋转了一下。
参考文献: