
GoogleNet是Google在2014年提出来的网络,这种网络大幅度减少了模型的参数数量,降低了计算资源,虽然整个网络只有22层,但是ILSVRC 2014年比赛中分类任务的TOP-1。GoogleNet有22层深,比AlexNet的8层或者VGGNet的19层还要更深。但其计算量只有15亿次浮点运算,同时只有500万的参数量,仅为AlexNet参数量(6000万)的1/12,却可以达到远胜于AlexNet的准确率。
【简介】
现有深度学习方面取得的成果,不光在高性能的计算机资源、大的数据和庞大模型上取得了发展,同时也产生了很多新的算法模型和网络的实现方法。但是随着移动设备等发展对于计算资源开销越来越重视,GoogleNet不光可以在生成环境中使用,同时在大型数据集中的资源消耗都有很好表现。
【Motivation and High Level Considerations】
提高网络的表现,可以通过增加网络的深度和宽度实现,但是这种方式也存在两个重大的缺陷:
1、网络的增大意味着有更多的参数,可能导致过拟合。
2、需要更多计算资源
解决方法:

1、稀疏的连接结构(卷积层其实就是一个稀疏连接)
人脑的神经元的连接是稀疏的, 因此研究者认为大型神经网络的合理的连接方式应该也是稀疏的。稀疏结构是非常适合神经网络的一种结构,因为可以减轻网络的过拟合现象降低计算量,特别是随着数据集的增大和非常大、非常深的神经网络。
Hebbian原理说明“突触前神经元向突触后神经元的持续重复的刺激可以导致突触传递效能的增加,当两个神经元细胞A和B距离很近,并且A参与了对B重复、持续的兴奋,那么某些代谢变化会导致A将作为能使B兴奋的细胞”,即是“一起发射的神经元会连在一起”(Cells that fire together, wire together),好比摇铃铛后给动物喂食,久而久之动物听见铃铛声就会分泌口水,产生进食的欲望,这就是“听见铃铛”的神经元和控制“口水”的神经元之间的链接被加强了,这是自然而然在大脑内部发生的。
受Hebbian原理启发,文章《Provable Bounds for Learning Some Deep Representations》提出,当某个数据集的分布可以用一个稀疏网络表达的时候就可以通过分析某些激活值的相关性,将相关度高的神经元聚合,来获得一个稀疏的表示,那么构筑这个网络的最佳方法是逐层构筑网络:将上一层高度相关(correlated)的节点聚类,并将聚类出来的每一个小簇(cluster)连接到一起。

卷积层其实就是一个稀疏连接,在图片数据中,因为相邻的像素点其相关性最高,因此把相邻的像素点通过卷积操作连接在一起,这是符合Hebbian原理的,Inception Net的主要目标就是找到最优的稀疏结构单元(即Inception Module)。
2、1*1卷积核
1*1的卷积核在计算过程中,能够将位于同一空间位置但在不同通道的特征连接在一起,其连接的节点的相关性最高,因为我们知道在同一空间位置的不同通道的卷积核的输出结果在某种程度上是非常相关的,因此1*1卷积核在Inception Module运用频繁。相比较其3*3或5*5的卷积核稍大一点尺寸卷积核,它们所连接的节点相关性也高,所以适当使用可以增加多样性(diversity)。
【网络结构】
【不同规格卷积核】

整个网络Inception Net含有22层,中间主要结构单元是Inception module,在Inception module中存在三类卷积核,其中1*1的卷积核最多,其次是3*3和5*5卷积核。整个网络除了最后一层的输出结果,中间节点也使用辅助分类节点(auxiliary classifiers),就是在训练过程中,将中间某层的输出结果用作分类,并按照一个比较小的权重(0.3)加到最终的分类结果中,一般在深度加深的情况下,在BP算法执行时可能会使得某些梯度为0,这会使得网络的收敛变慢。Inception Net使用两个输出层(Auxiliary Classifiers),这样一些权值更新的梯度就会来自于多个部分的叠加,加速了网络的收敛。预测时时会把AC层去掉。
在整个网络中,会有多个堆叠的Inception Module,靠后的Inception Module可以捕捉更高阶的抽象特征,因此靠后的Inception Module的卷积的空间集中度应该逐渐降低,这样可以捕获更大面积的特征。因此,越靠后的Inception Module中,3´3和5´5这两个大面积的卷积核的占比(输出通道数)应该更多。

1×1卷积这用来进行降维,对于每一个Inception module(如上图),右图中通过加入若干的1×1卷积能有效降低卷积核的参数,
比如:输入的feature map是28×28×192,1×1卷积通道为64,3×3卷积通道为128,5×5卷积通道为32
左图:1×1×192×64+3×3×192×128+5×5×192×32 = 387072
右图:1×1×192×64+(1×1×192×96+3×3×96×128)+(1×1×192×16+5×5×16×32)=157184(3×3和5×5卷积层前分别加入了通道数为96和16的1×1卷积层)
同时右图在池化层后面加入了一个1×1卷积层,这样也可以降低输出的feature map数量,,左图pooling后feature map是不变的,再加卷积层得到的feature map,会使输出的feature map扩大到416,如果每个模块都这样,网络的输出会越来越大。而右图在pooling后面加了通道为32的1×1卷积,使得输出的feature map数降到了256。

【全局平均池化GAP】
M. Lin, Q. Chen, and S. Yan. Network in network. Interna-tional Conference on Learning Representations, 2014.
with global pooling reduces the dimensionality from 3D to 1D. Therefore Global pooling outputs 1 response for every feature map. This can be the maximum or the average or whatever othere pooling operation you use.
It is often used at the end of the backend of a convolutional neural network to get a shape that works with dense layers. Therefore no flatten has to be applied.
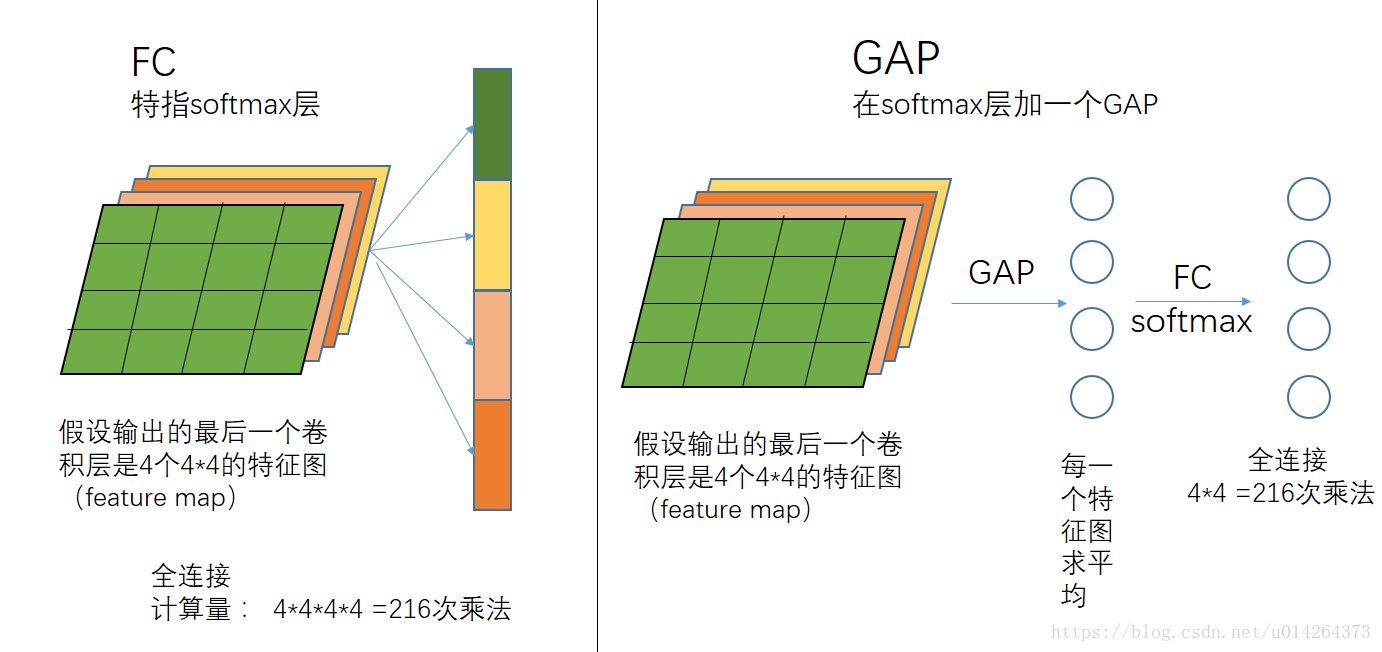
用全局平均池GAP化来代替FC,由于FC层参数多,训练速度慢,并且会将一定的特征存储在这些参数内。用一个GAP将N个feature map降维成1*N大小的feature map,再用class个1*1卷积核将1*N的feature map卷成1*class的向量。因此,整个过程在维度上来看相当于一层FC,但是需要注意的是,在使用GAP后,网络收敛速度将会变慢。
更多经典文献阅读,欢迎关注公众号“武汉AI算法研习”
【主要参考文献】