作者:YJHMITWEB
链接:https://www.zhihu.com/question/265345106/answer/294410307
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
首先我们明确一个定义,当前主流的Object Detection框架分为1 stage和2 stage,而2 stage多出来的这个stage就是Regional Proposal过程,明确这一点后,我们继续讲。
Regional Proposal的输出到底是什么?
我们首先看一下以Faster R-CNN为代表的2 stage目标检测方法
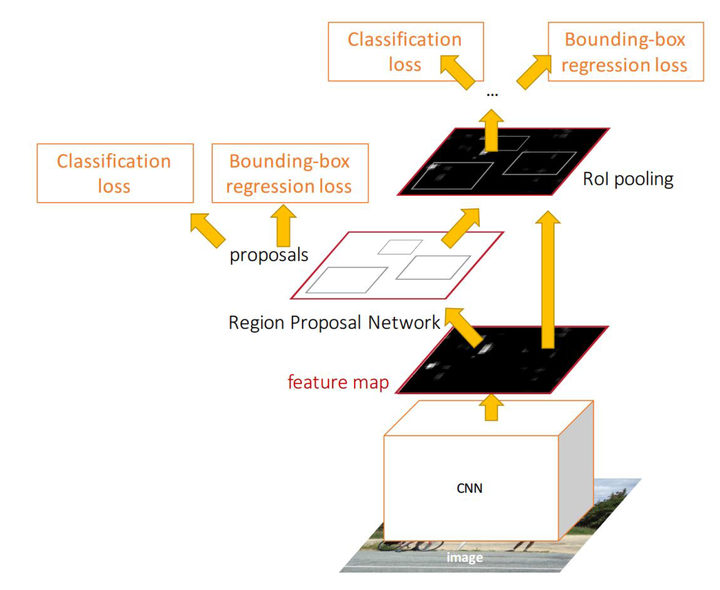
图1
可以看到,图中有两个Classification loss和两个Bounding-box regression loss,有什么区别呢?
1、Input Image经过CNN特征提取,首先来到Region Proposal网络。由Regio Proposal Network输出的Classification,这并不是判定物体在COCO数据集上对应的80类中哪一类,而是输出一个Binary的值p,可以理解为 ,人工设定一个threshold=0.5。
RPN网络做的事情就是,如果一个Region的 ,则认为这个Region中可能是80个类别中的某一类,具体是哪一类现在还不清楚。到此为止,Network只需要把这些可能含有物体的区域选取出来就可以了,这些被选取出来的Region又叫做ROI (Region of Interests),即感兴趣的区域。当然了,RPN同时也会在feature map上框定这些ROI感兴趣区域的大致位置,即输出Bounding-box。
----打个比方----
我上午第四节课饿得不行,我就想着中午要吃什么?附近好多西餐厅和中餐厅,餐厅里菜品有很多。但是我生活费不够了。。gg。。不太想吃(吃不起)西餐,所以无论西餐厅里有什么菜品,我都不会考虑;只有路过中餐厅时,我才会进去看看具体吃什么菜。
----------真是尴尬的栗子----------
So, RPN网络做的事情就是,把一张图片中,我不感兴趣的区域——花花草草、大马路、天空之类的区域忽视掉,只留下一些我可能感兴趣的区域——车辆、行人、水杯、闹钟等等,然后我之后只需要关注这些感兴趣的区域,进一步确定它到底是车辆、还是行人、还是水杯(分类问题)。。。。
你可能会看到另一对通俗易懂的词语,前景(车、人、杯)和背景(大马路、天空)。

图2.天空和草地都属于背景

图3.天空和马路也都是背景
啊 好的,到此为止,RPN网络的工作就完成了,即我们现在得到的有:在输入RPN网络的feature map上,所有可能包含80类物体的Region区域的信息,其他Region(非常多)我们可以直接不考虑了(不用输入后续网络)。
接下来的工作就很简单了,假设输入RPN网络的feature map大小为 ,那么我们提取的ROI的尺寸一定小于
,因为原始图像某一块的物体在feature map上也以同样的比例存在。我们只需要把这些Region从feature map上抠出来,由于每个Region的尺寸可能不一样,因为原始图像上物体大小不一样,所以我们需要将这些抠出来的Region想办法resize到相同的尺寸,这一步方法很多(Pooling或者Interpolation,一般采用Pooling,因为反向传播时求导方便)。
假设这些抠出来的ROI Region被我们resize到了 或者
,那我们接下来将这些Region输入普通的分类网络,即第一张Faster R-CNN的结构图中最上面的部分,即可得到整个网络最终的输出classification,这里的class(车、人、狗。。)才真正对应了COCO数据集80类中的具体类别。
同时,由于我们之前RPN确定的box\region坐标比较粗略,即大概框出了感兴趣的区域,所以这里我们再来一次精确的微调,根据每个box中的具体内容微微调整一下这个box的坐标,即输出第一张图中右上方的Bounding-box regression。
整个Faster R-CNN网络就到此结束了,下面总结一下,同时也回答你的问题:
Region Proposal有什么作用?
1、COCO数据集上总共只有80类物体,如果不进行Region Proposal,即网络最后的classification是对所有anchor框定的Region进行识别分类,会严重拖累网络的分类性能,难以收敛。原因在于,存在过多的不包含任何有用的类别(80类之外的,例如各种各样的天空、草地、水泥墙、玻璃反射等等)的Region输入分类网络,而这些无用的Region占了所有Region的很大比例。换句话说,这些Region数量庞大,却并不能为softmax分类器带来有用的性能提升(因为无论怎么预测,其类别都是背景,对于主体的80类没有贡献)。
2、大量无用的Region都需要单独进入分类网络,而分类网络由几层卷积层和最后一层全连接层组成,参数众多,十分耗费计算时间,Faster R-CNN本来就不能做到实时,这下更慢了。
最后有个小小的说明,针对不了解Anchor的同学们,我在文中始终在说对于感兴趣的区域“框定一个坐标”,这是为了便于理解,其实这样说是不准确的。
具体就是:我们整张图像上,所有的框,一开始就由Anchor和网络结构确定了,这些框都有各自初始的坐标(锚点)。所有后续的工作,RPN提取前景和背景,其实就是保留包含前景的框,丢掉包含背景的;包括后续的NMS,也都是丢掉多余的,并非重新新建一个框。
我们网络输出的两个Bounding-box regression,都是输出的坐标偏移量,也就是在初始锚点的基础上做的偏移修正和缩放,并非输出一个原图上的绝对坐标。
yolo有类似rpn的机制,那就是最后输出时的confidence值,这个值决定了前景和背景。
ssd是将anchor机制融合在了1 stage模型中,原理与本文所述基本一致。

图4.这张更能体现object detection的state-of-the-art
引用:
图1.https://arxiv.org/abs/1506.01497
图2、3、4均为在Google Image中找到原始图像,我自己做的Object Detection并标注