代码下载于 github,使用分支是 origin/branch-2.4
Driver 进程被启动时,会实例化 SparkContext 对象,然后 SparkContext 在构建 DAGScheduler 和 TaskScheduler 对象。这句话在 Spark学习笔记之调度 基本上都会被提及,这篇就从源码角度来剖析这个问题。
首先从 SparkContext 源码入手:
-- SparkContext.scala
// 初始化 TaskScheduler
val (sched, ts) = SparkContext.createTaskScheduler(this, master, deployMode)
_schedulerBackend = sched
_taskScheduler = ts
//初始化 DAGScheduler
_dagScheduler = new DAGScheduler(this)
_heartbeatReceiver.ask[Boolean](TaskSchedulerIsSet)
来看看 TaskScheduler 的初始化操作
-- SparkContext.scala
/*
根据跟定的 url 来创建 task scheduler,这里返回 SchedulerBackend, TaskScheduler 两个对象,也就是说 SchedulerBackend 和 TaskScheduler 分别被实例化了。
*/
private def createTaskScheduler(
sc: SparkContext,
master: String,
deployMode: String): (SchedulerBackend, TaskScheduler) = {
import SparkMasterRegex._
// 这个就是常用的 standalone 模式
master match {
case SPARK_REGEX(sparkUrl) =>
val scheduler = new TaskSchedulerImpl(sc)
val masterUrls = sparkUrl.split(",").map("spark://" + _)
val backend = new StandaloneSchedulerBackend(scheduler, sc, masterUrls)
scheduler.initialize(backend)
(backend, scheduler)
}
}
在实例化 SchedulerBackend, TaskScheduler 时,会创建一个 SchedulerPool,SchedulerPool 会判断 FAIR 和 FIFO 方式来创建。
-- TaskSchedulerImpl.scala
def initialize(backend: SchedulerBackend) {
this.backend = backend
schedulableBuilder = {
schedulingMode match {
case SchedulingMode.FIFO =>
new FIFOSchedulableBuilder(rootPool)
case SchedulingMode.FAIR =>
new FairSchedulableBuilder(rootPool, conf)
case _ =>
throw new IllegalArgumentException(s"Unsupported $SCHEDULER_MODE_PROPERTY: " +
s"$schedulingMode")
}
}
schedulableBuilder.buildPools()
}
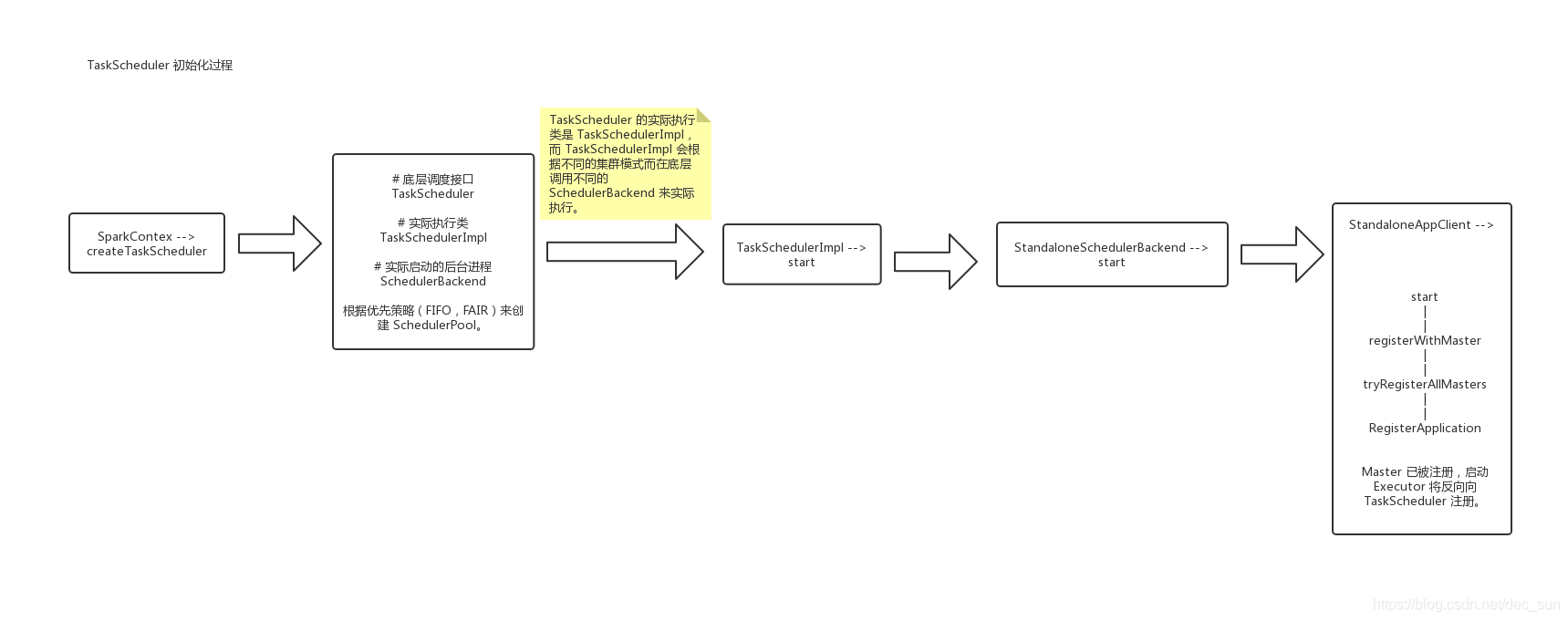
TaskScheduler 是一个底层调度接口,实际执行操作在 org.apache.spark.scheduler.TaskSchedulerImpl。而其底层通过操作一个 SchedulerBackend,针对不同种类的 cluster 调度方式(standalone,yarn,mesos)来调度 task。
客户端可以调用 initialize 和 start 方法,然后通过 runTasks 方法来提交 task sets。
初始化完 SchedulerBackend, TaskScheduler 就会启动 TaskScheduler (_taskScheduler.start()),最终会调用 StandaloneSchedulerBackend.start()
-- StandaloneSchedulerBackend.scala
override def start() {
// 如果是 Clinet 模式, Scheduler backend 应该仅仅视图去连接 luancher;而在 cluster 模式,提交到
// master 节点的应用代码需要连接 luancher。
if (sc.deployMode == "client") {
launcherBackend.connect()
}
// 将 Application 的 name, 请求的 core 和 memory 等信息进行封装
val appDesc = ApplicationDescription(sc.appName, maxCores, sc.executorMemory, command,
webUrl, sc.eventLogDir, sc.eventLogCodec, coresPerExecutor, initialExecutorLimit)
// 将封装信息,conf 等构造一个 StandaloneAppClient 实例
client = new StandaloneAppClient(sc.env.rpcEnv, masters, appDesc, this, conf)
// StandaloneAppClient 启动
client.start()
launcherBackend.setState(SparkAppHandle.State.SUBMITTED)
waitForRegistration()
launcherBackend.setState(SparkAppHandle.State.RUNNING)
}
StandaloneAppClient 是一个接口,允许 Application 应用 与 spark 集群进行通信,并且其会接收 spark master 的 url 和 ApplicationDescription 的应用描述,以及集群事件的监听器和各种发生时监听器的回调。
-- StandaloneAppClient.scala
def start() {
// 启动一个 rpcEndpoint; 将回调进入监听状态。
endpoint.set(rpcEnv.setupEndpoint("AppClient", new ClientEndpoint(rpcEnv)))
}
/**
* 注册到 所有的 master 上,返回一个 Array[Future].
*/
private def tryRegisterAllMasters(): Array[JFuture[_]] = {
for (masterAddress <- masterRpcAddresses) yield {
registerMasterThreadPool.submit(new Runnable {
override def run(): Unit = try {
if (registered.get) {
return
}
logInfo("Connecting to master " + masterAddress.toSparkURL + "...")
val masterRef = rpcEnv.setupEndpointRef(masterAddress, Master.ENDPOINT_NAME)
// 发送 RegisterApplication 到远程节点就 master 节点上。这样就表示注册成功了。
masterRef.send(RegisterApplication(appDescription, self))
} catch {
case ie: InterruptedException => // Cancelled
case NonFatal(e) => logWarning(s"Failed to connect to master $masterAddress", e)
}
})
}
}
所以,上述流程就表示 driver 向 master 注册的流程。上述流程主要是 Driver -> SparkContext -> TaskScheduler -> StandaloneSchedulerBackend -> StandaloneAppClient,一个TaskScheduler 向 Master 的注册过程。
再来看看 DAGScheduler 的流程。
DAGScheduler 是实现了 面向 stage 的调度的 高层次的调度层,它可以为每个 job 计算出一个 DAG,追踪 RDD和 stage 的输出是否被持久化,并且寻找到一个最优调度机制来运行 job,它会将 stage 作为 taskset 提交到底层的 TaskScheduler 来发送到集群上运行这些 task。此外它还决定了运行每个 task 的最佳位置,基于当前的缓存状态,将这些最佳位置提交给 底层的 TaskScheduler。兵器,它会处理由于 shuffle 输出文件丢失导致的失败,在这种情况下,旧的 stage 可能会被重新提交。一个 stage 内部的失败,如果不是由于 shuffle文件丢失导致的,会被 TaskScheduler 处理,它会被多次重试每一个 task,直到最后一个。实在不行,才会被取消整个 stage。
可以发现,DAGScheduler 底层是基于调用 DAGSchedulerEventProcessLoop
private[spark] val eventProcessLoop = new DAGSchedulerEventProcessLoop(this)
SparkUI 是通过实例化 SparkUI 来实现的
-- SparkContext.scala
_ui =
if (conf.getBoolean("spark.ui.enabled", true)) {
Some(SparkUI.create(Some(this), _statusStore, _conf, _env.securityManager, appName, "",
startTime))
} else {
// For tests, do not enable the UI
None
}
// 在开始执行 task 任务时,绑定通信端端口
_ui.foreach(_.bind())
-- SparkUI.scala
/**
* 根据存储的应用状态来创建 SparkUI
*/
def create(
sc: Option[SparkContext],
store: AppStatusStore,
conf: SparkConf,
securityManager: SecurityManager,
appName: String,
basePath: String,
startTime: Long,
appSparkVersion: String = org.apache.spark.SPARK_VERSION): SparkUI = {
new SparkUI(store, sc, conf, securityManager, appName, basePath, startTime, appSparkVersion)
}
如图: