DAGSchedular 将划分的一系列 stage,按照 Stage 的先后顺序依次提交给底层的 TaskSchedular 去执行。现在就来探究下 TaskScheduler 的原理。
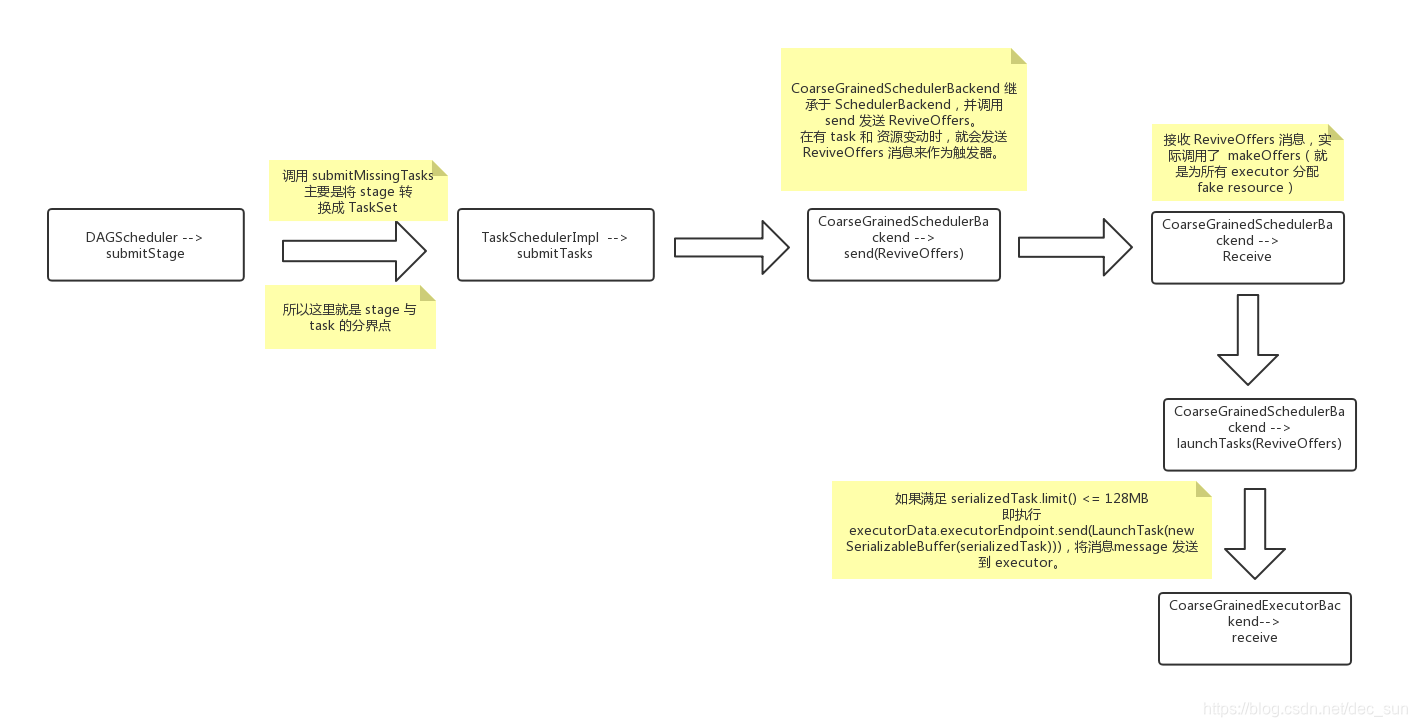
DAGScheduler 创建 Stage 时,已经跟踪到了 submitStage,当创建 stage 完成后,就会调用 submitMissingTasks。
submitMissingTasks 主要是将 stage 转换成 TaskSet,然后 taskScheduler.submitTasks(new TaskSet( tasks.toArray, stage.id, stage.latestInfo.attemptNumber, jobId, properties))。
-- DAGScheduler.scala
/** Called when stage's parents are available and we can now do its task. */
private def submitMissingTasks(stage: Stage, jobId: Int) {
// 根据 ShuffleMapStage 和 ResultStage 分别创建 TaskSet,然后调用 submitTasks 操作。
if (tasks.nonEmpty) {
logInfo(s"Submitting ${tasks.size} missing tasks from $stage (${stage.rdd}) (first 15 " +
s"tasks are for partitions ${tasks.take(15).map(_.partitionId)})")
/* *调用 submitTasks 将 task 提交给 TaskScheduler,这里使用了 TaskSet 进行封装
* TaskSet 的第一个参数:tasks,
* 第二个参数:task对应所属的 stage id,
* 第三个参数:尝试的 id
* 第四个参数:优先级
* 第五个参数:与此阶段关联的ActiveJob中的计划池、作业组、说明
*/
taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptNumber, jobId, properties))
} else {
// Because we posted SparkListenerStageSubmitted earlier, we should mark
// the stage as completed here in case there are no tasks to run
markStageAsFinished(stage, None)
}
}
TaskScheduler 的实现是在 TaskSchedulerImpl 中,所以
-- TaskSchedulerImpl.scala
override def submitTasks(taskSet: TaskSet) {
val tasks = taskSet.tasks
logInfo("Adding task set " + taskSet.id + " with " + tasks.length + " tasks")
this.synchronized { // 同步代码块
/**
* 创建一个 TaskSetManager 来封装 TaskSet 和最大失败次数 maxTaskFailures。
*/
val manager = createTaskSetManager(taskSet, maxTaskFailures)
val stage = taskSet.stageId
val stageTaskSets =
taskSetsByStageIdAndAttempt.getOrElseUpdate(stage, new HashMap[Int, TaskSetManager])
// 保证所有 TaskManager 处于非启动状态。
stageTaskSets.foreach { case (_, ts) =>
ts.isZombie = true
}
stageTaskSets(taskSet.stageAttemptId) = manager
/**
* schedulableBuilder 有两种方式: FIFOSchedulableBuilder,FairSchedulableBuilder,
* 默认为 FIFOSchedulableBuilder。SchedulableBuilder 其实就是一个Scheduler pool。
*/
schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties)
hasReceivedTask = true
}
backend.reviveOffers()
}
最后就到了 backend.reviveOffers(),这里又是 SchedulerBackend,就进入到到了 CoarseGrainedSchedulerBackend,
一个等待粗粒度执行器连接的调度的后端程序。这个后端程序在 spark 作业期间将会持有每个执行器,而且也不会在任务完成时放弃执行器, 并要求调度程序为每个新任务启动一个新的执行器。
-- CoarseGrainedSchedulerBackend.scala
override def reviveOffers() {
driverEndpoint.send(ReviveOffers)
}
Message 发送成功后,接下来就执行…
-- CoarseGrainedSchedulerBackend.scala
override def receive: PartialFunction[Any, Unit] = {
case ReviveOffers =>
makeOffers()
}
就是为所有 executor 分配 fake resource。
-- CoarseGrainedSchedulerBackend.scala
private def makeOffers() {
// 确保在 task 被启动时,没有 executor 被 kill。
val taskDescs = withLock {
val activeExecutors = executorDataMap.filterKeys(executorIsAlive)
val workOffers = activeExecutors.map {
case (id, executorData) =>
// workerOffer 代表着有可以资源的 executor
new WorkerOffer(id, executorData.executorHost, executorData.freeCores,
Some(executorData.executorAddress.hostPort),
executorData.resourcesInfo.map { case (rName, rInfo) =>
(rName, rInfo.availableAddrs.toBuffer)
})
}.toIndexedSeq
// cluster manager 分配资源给 slave。
scheduler.resourceOffers(workOffers)
}
if (taskDescs.nonEmpty) {
launchTasks(taskDescs)
}
}
先来看看 scheduler.resourceOffers(workOffers),来分析是如何分配资源给 slaves。
-- TaskSchedulerImpl.scala
def resourceOffers(offers: IndexedSeq[WorkerOffer]): Seq[Seq[TaskDescription]] = synchronized {
// 标记每个存活的 slave,记下其 hostname,
var newExecAvail = false
for (o <- offers) {
// 遍历所有的 hostToExecutor,这是一个 hashMap。如果是新增加的 executor,那么就将其添加进来。
if (!hostToExecutors.contains(o.host)) {
hostToExecutors(o.host) = new HashSet[String]()
}
// 如果 task 没有在 Executor上运行,那么就添加 task id 到 executorIdToRunningTaskIds
// 同时激活 newExecAvail 标志位,这样就可以后续进行添加了。
if (!executorIdToRunningTaskIds.contains(o.executorId)) {
hostToExecutors(o.host) += o.executorId
executorAdded(o.executorId, o.host)
executorIdToHost(o.executorId) = o.host
executorIdToRunningTaskIds(o.executorId) = HashSet[Long]()
newExecAvail = true
}
}
val hosts = offers.map(_.host).toSet.toSeq
for ((host, Some(rack)) <- hosts.zip(getRacksForHosts(hosts))) {
hostsByRack.getOrElseUpdate(rack, new HashSet[String]()) += host
}
// 过滤掉黑名单中的节点。
blacklistTrackerOpt.foreach(_.applyBlacklistTimeout())
val filteredOffers = blacklistTrackerOpt.map { blacklistTracker =>
offers.filter { offer =>
!blacklistTracker.isNodeBlacklisted(offer.host) &&
!blacklistTracker.isExecutorBlacklisted(offer.executorId)
}
}.getOrElse(offers)
// 将过滤后的 Node 节点 进行洗牌操作,防止将 task 总是放在一个 worker node 上。
val shuffledOffers = shuffleOffers(filteredOffers)
// 建立要分配给每个 worker 的任务列表。
// CPUS_PER_TASK 默认为 1,意味着:每个 task 分配一个 CPU。
val tasks = shuffledOffers.map(o => new ArrayBuffer[TaskDescription](o.cores / CPUS_PER_TASK))
val availableResources = shuffledOffers.map(_.resources).toArray
val availableCpus = shuffledOffers.map(o => o.cores).toArray
val availableSlots = shuffledOffers.map(o => o.cores / CPUS_PER_TASK).sum
val sortedTaskSets = rootPool.getSortedTaskSetQueue
for (taskSet <- sortedTaskSets) {
logDebug("parentName: %s, name: %s, runningTasks: %s".format(
taskSet.parent.name, taskSet.name, taskSet.runningTasks))
if (newExecAvail) {
taskSet.executorAdded()
}
}
// 把每个 taskSet 放在调度顺序最后那个,然后提供它的每个节点本地性的级别的递增顺序,
// 以便它有机会启动所有任务的本地任务
// 数据本地性的优先级别顺序:PROCESS_LOCAL, NODE_LOCAL, NO_PREF, RACK_LOCAL, ANY
for (taskSet <- sortedTaskSets) {
// 如果可用插槽少于挂起任务的数量,则跳过 barrier 任务集。
if (taskSet.isBarrier && availableSlots < taskSet.numTasks) {
// 跳过启动过程
} else {
var launchedAnyTask = false
// Record all the executor IDs assigned barrier tasks on.
val addressesWithDescs = ArrayBuffer[(String, TaskDescription)]()
/**
* 循环遍历 sortedTaskSet, 对其中的每个 taskSet,首先考虑 myLocalityLevels。
* myLocalityLevels 计算数据本定型的 level,
* 将 PROCESS_LOCAL, NODE_LOCAL, NO_PREF, RACK_LOCAL, ANY 都循环一遍。
*/
for (currentMaxLocality <- taskSet.myLocalityLevels) {
var launchedTaskAtCurrentMaxLocality = false
do {
launchedTaskAtCurrentMaxLocality = resourceOfferSingleTaskSet(taskSet,
currentMaxLocality, shuffledOffers, availableCpus,
availableResources, tasks, addressesWithDescs)
launchedAnyTask |= launchedTaskAtCurrentMaxLocality
} while (launchedTaskAtCurrentMaxLocality)
}
...
}
}
return tasks
}
再从 makeOffers 看最后一条代码 launchTasks(taskDescs)
-- CoarseGrainedSchedulerBackend.scala
if (taskDescs.nonEmpty) {
launchTasks(taskDescs)
}
private def launchTasks(tasks: Seq[Seq[TaskDescription]]) {
for (task <- tasks.flatten) {
// 对 task 进行序列化
val serializedTask = TaskDescription.encode(task)
// 序列化的大小进行比较,必须必与设定的值要小才可以,maxRpcMessageSize 默认为 128.
if (serializedTask.limit() >= maxRpcMessageSize) {
Option(scheduler.taskIdToTaskSetManager.get(task.taskId)).foreach { taskSetMgr =>
try {
var msg = "Serialized task %s:%d was %d bytes, which exceeds max allowed: " +
s"${RPC_MESSAGE_MAX_SIZE.key} (%d bytes). Consider increasing " +
s"${RPC_MESSAGE_MAX_SIZE.key} or using broadcast variables for large values."
msg = msg.format(task.taskId, task.index, serializedTask.limit(), maxRpcMessageSize)
taskSetMgr.abort(msg)
} catch {
case e: Exception => logError("Exception in error callback", e)
}
}
}
else { // 满足限定条件。
val executorData = executorDataMap(task.executorId)
// 资源分配,在 task 完成以后,分配的资源将被释放。
executorData.freeCores -= scheduler.CPUS_PER_TASK
task.resources.foreach { case (rName, rInfo) =>
assert(executorData.resourcesInfo.contains(rName))
executorData.resourcesInfo(rName).acquire(rInfo.addresses)
}
// 将 task 发送到 worker 的 executor。
executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask)))
}
}
}
executor 接收到 data,就开始 decode 出来。从这里其实看出 driver 到 executor, 都有XXXXBackend 在后台进行处理。
-- CoarseGrainedExecutorBackend.scala
override def receive: PartialFunction[Any, Unit] = {
case LaunchTask(data) =>
if (executor == null) {
exitExecutor(1, "Received LaunchTask command but executor was null")
} else {
val taskDesc = TaskDescription.decode(data.value)
logInfo("Got assigned task " + taskDesc.taskId)
taskResources(taskDesc.taskId) = taskDesc.resources
executor.launchTask(this, taskDesc)
}
}