版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/weixin_39478115/article/details/79301150
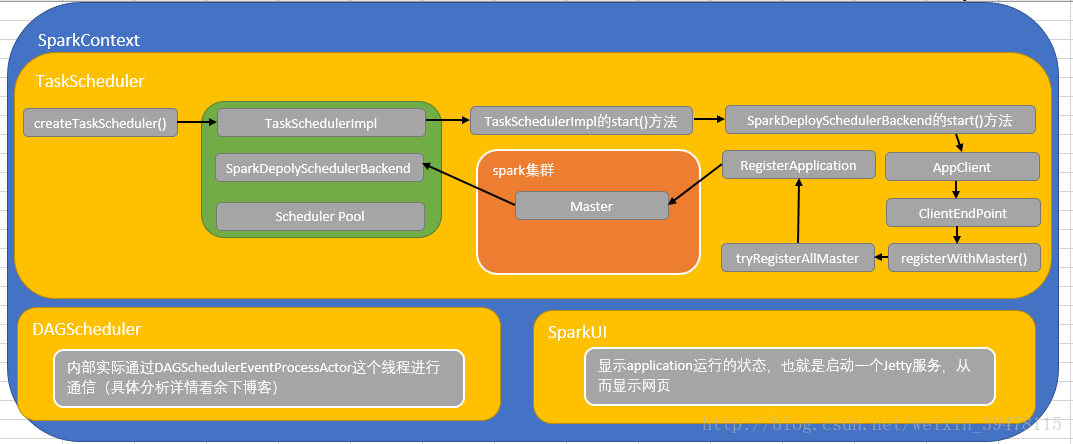
- 首先通过SparkContext方法,进行TaskScheduler的初始化机制,通过createTaskScheduler方法,通过创建TaskSchedulerImpl类(实际就是我们所说的taskScheduler)和SparkDeploySchedulerBackend,然后TaskSchedulerImpl的initialize方法,创建SchedulerPool(资源调度池,比如FIFO、Fair)
- TaskSchedulerImpl通过调用它的init()方法,它的init方法调用SparkDeployScheduler的start方法,用于启动一个AppClient,AppClient创建一个ClientEndPoint,内部方法先实现registerWithMaster,然后实现tryRegisterWithAllMaster(),里边有RegisterApplication(它是以case class,里边封装了Application的信息),向Spark集群中的Master进行注册,然后反向注册到SparkDeploySchedulerBackend上面去
- DAGScheduler实际是使用DAGSchedulerEventProcessActor这个组件进行通信(线程)
- SparkUI,显示application运行的状态,也就是启动一个Jetty服务,从而显示网页
SparkDeploySchedulerBackend解释:
SparkDeploySchedulerBackend它在底层会接受TaskSchedulerImpl的控制,实际上负责和Master的注册、Executor的反注册,task发送到executor等操作。
源码分析
第一步:进入SparkContext类
// 创建sparkUI,也就是web页面显示的
_ui =
if (conf.getBoolean("spark.ui.enabled", true)) {
Some(SparkUI.createLiveUI(this, _conf, listenerBus, _jobProgressListener,
_env.securityManager, appName, startTime = startTime))
} else {
// For tests, do not enable the UI
None
}
// Bind the UI before starting the task scheduler to communicate
// the bound port to the cluster manager properly
_ui.foreach(_.bind())
......
// Create and start the scheduler
// 主构造方法,SparkContext调用时默认就调用此方法
val (sched, ts) = SparkContext.createTaskScheduler(this, master)
_schedulerBackend = sched
_taskScheduler = ts
// 创建DAGScheduler
_dagScheduler = new DAGScheduler(this)
_heartbeatReceiver.ask[Boolean](TaskSchedulerIsSet)
// start TaskScheduler after taskScheduler sets DAGScheduler reference in DAGScheduler's
// constructor
// 启动taskScheduler,也就是对应的TaskSchedulerImpl的start方法
_taskScheduler.start()第二步:点击createTaskScheduler
// 这是spark提交方式中的standalone方式
case SPARK_REGEX(sparkUrl) =>
val scheduler = new TaskSchedulerImpl(sc)
val masterUrls = sparkUrl.split(",").map("spark://" + _)
val backend = new SparkDeploySchedulerBackend(scheduler, sc, masterUrls)
scheduler.initialize(backend)
(backend, scheduler)第三步:点击TaskSchedulerImpl
/**
* 1、底层通过操作一个SchedulerBackend,针对不同的种类的cluster(standalone,yarn,mesos),进行调度task
* 2、它也可以使用一个LocalBackend,并将isLocal设置为true,来进行本地模式下进行工作
* 3、它负责处理一些通用的逻辑,比如说多个job的调度顺序(例如FIFO),启动推测任务执行(比如某些任务执行的速度慢,剔除掉,从其他地方执行)
* 4、客户端首先会调用他的initialize()和start()方法,然后通过runTasks()方法来提交task
*/
private[spark] class TaskSchedulerImpl(
val sc: SparkContext,
val maxTaskFailures: Int,
isLocal: Boolean = false)
extends TaskScheduler with Logging
{
def this(sc: SparkContext) = this(sc, sc.conf.getInt("spark.task.maxFailures", 4))
......
override def start() {
// 最核心的在于把SparkDeploySchedulerBacked的方法调用
backend.start()
if (!isLocal && conf.getBoolean("spark.speculation", false)) {
logInfo("Starting speculative execution thread")
speculationScheduler.scheduleAtFixedRate(new Runnable {
override def run(): Unit = Utils.tryOrStopSparkContext(sc) {
checkSpeculatableTasks()
}
}, SPECULATION_INTERVAL_MS, SPECULATION_INTERVAL_MS, TimeUnit.MILLISECONDS)
}
}第四步:点击第二步中的SparkDeploySchedulerBackend
override def start() {
super.start()
launcherBackend.connect()
......
// === 描述了当前应用程序的配置信息,包括此application需要多大的cpu core,每个slave上需要多少内存
val appDesc = new ApplicationDescription(sc.appName, maxCores, sc.executorMemory,
command, appUIAddress, sc.eventLogDir, sc.eventLogCodec, coresPerExecutor)
// === 创建AppClient
client = new AppClient(sc.env.rpcEnv, masters, appDesc, this, conf)
// === 启动client
client.start()
launcherBackend.setState(SparkAppHandle.State.SUBMITTED)
waitForRegistration()
launcherBackend.setState(SparkAppHandle.State.RUNNING)
}第五步:点击第四步中的AppClient
/**
* Interface allowing applications to speak with a Spark deploy cluster. Takes a master URL,
* an app description, and a listener for cluster events, and calls back the listener when various
* events occur.
*
* 1、这是一个接口
* 2、它负责为application和spark集群进行通信
* 3、它负责接收一个spark master的url,以及applicationDescription,和一个集群事件的监听器,以及各种事件发生时监听器的回调函数
*/
......
// 是AppClient的内部类
private class ClientEndpoint(override val rpcEnv: RpcEnv) extends ThreadSafeRpcEndpoint
with Logging {
override def onStart(): Unit = {
try {
// === 注册master
registerWithMaster(1)
} catch {
case e: Exception =>
logWarning("Failed to connect to master", e)
markDisconnected()
stop()
}
}
......
private def registerWithMaster(nthRetry: Int) {
// 核心在于tryRegisterAllMasters
registerMasterFutures.set(tryRegisterAllMasters())
registrationRetryTimer.set(registrationRetryThread.scheduleAtFixedRate(new Runnable {
......
/**
* Register with all masters asynchronously and returns an array `Future`s for cancellation.
* master支持两种主备切换机制,一种的hdfs的,另外一种是基于zookeeper的(动态ha,热切换的)
*/
private def tryRegisterAllMasters(): Array[JFuture[_]] = {
for (masterAddress <- masterRpcAddresses) yield {
registerMasterThreadPool.submit(new Runnable {
override def run(): Unit = try {
if (registered.get) {
return
}
logInfo("Connecting to master " + masterAddress.toSparkURL + "...")
val masterRef =
rpcEnv.setupEndpointRef(Master.SYSTEM_NAME, masterAddress, Master.ENDPOINT_NAME)
// === 发送RegisterApplication这个case cass,把appDescription发送给master,进行向master注册
masterRef.send(RegisterApplication(appDescription, self))
} catch {
case ie: InterruptedException => // Cancelled
case NonFatal(e) => logWarning(s"Failed to connect to master $masterAddress", e)
}
})
}
}第六步:查看master类的RegisterApplication类
/**
* 处理Applicaton的注册的请求
*/
case RegisterApplication(description, driver) => {
// TODO Prevent repeated registrations from some driver
// 如果master的状态为standby,也就是当前的这个master,不是active
// 那么applicaiton来请求注册,什么都不会做
if (state == RecoveryState.STANDBY) {
// ignore, don't send response
} else {
logInfo("Registering app " + description.name)
// 用ApplicationDescription信息,创建ApplicationInfo
val app = createApplication(description, driver)
// 注册Application
// 将Application加入缓存,将Application加入等待调度的队列
registerApplication(app)
logInfo("Registered app " + description.name + " with ID " + app.id)
// 用持久化引擎,将ApplicationInfo进行持久化
persistenceEngine.addApplication(app)
// 反向,向SparkDeploySchedulerBackend的AppClient的ClientActor发送消息,也就是registeredApplication,而不是registerApplication
driver.send(RegisteredApplication(app.id, self))
schedule()
}
}第七步:查看第二步中的scheduler.initialize(backend)方法
// 创建调度池,可以是FIFO,也可以是Fair,FIFO是先进先出的调度算法,Fair是公平调度算法
// FIFO:根据任务的个数和分配资源的比值,选择较小的一个
// FAIR:队列中的Job平分资源
def initialize(backend: SchedulerBackend) {
this.backend = backend
// temporarily set rootPool name to empty
rootPool = new Pool("", schedulingMode, 0, 0)
schedulableBuilder = {
schedulingMode match {
case SchedulingMode.FIFO =>
new FIFOSchedulableBuilder(rootPool)
case SchedulingMode.FAIR =>
new FairSchedulableBuilder(rootPool, conf)
}
}
schedulableBuilder.buildPools()
}第八步:点击第一步中的DAGScheduler
/**
* 实现了面向stage的调度机制的高层次的调度层 ,它会为每个job计算一个stage的DAG(有向无环图),
* 追踪RDD和Stage的输出是否被物化了,也就是说写入磁盘或者是内存中,并且寻找一个最小消耗、最优调度机制
* 运行job,它会将stage作为taskset提交到底层的TaskSchedulerImpl中,并在集群中运行他们
*
* 除了处理stage的DAG,它还负责决定运行每一个task的最佳位置,基于当前的缓存状态,并将这些最佳的位置提交
* 给底层的TaskSchedulerImpl,此外,他还会处理由于shuffle输出文件丢失导致的失败,在这种情况下,旧的stage
* 可能就会被重新提交。一个stage内部的失败,如果不是由于shuffle文件丢失所导致的,会被TaskScheduler处理,
* 它会多次重试每一个task,直到最后,实在不行了,才会去取消整个stage,也就是说app挂掉
......
private[spark]
class DAGScheduler(
private[scheduler] val sc: SparkContext,
private[scheduler] val taskScheduler: TaskScheduler,
listenerBus: LiveListenerBus,
mapOutputTracker: MapOutputTrackerMaster,
blockManagerMaster: BlockManagerMaster,
env: SparkEnv,
clock: Clock = new SystemClock())
extends Logging {
......
第八步:点击第一步中的_ ui
private var _ui: Option[SparkUI] = None点击SparkUI
import org.apache.spark.status.api.v1.{ApiRootResource, ApplicationAttemptInfo, ApplicationInfo,UIRoot}
import org.apache.spark.{Logging, SecurityManager, SparkConf, SparkContext}
import org.apache.spark.scheduler._
import org.apache.spark.storage.StorageStatusListener
import org.apache.spark.ui.JettyUtils._