一、源码下载以及安装阅读
这部分可以看我写的第一个源码分析的开始,有说明,比较简单,附上链接http://blog.csdn.net/flyinthesky111/article/details/79379309
二、源码阅读以及分析
老规矩,先看总体注释,看完对sparkcontext就有一个大概印象
第一段注释:Main entry point for Spark functionality. A SparkContext represents the connection to a Spark cluster, and can be used to create RDDs, accumulators and broadcast variables on that cluster.告诉我们它是spark功能的一个主要入口,主要作用:连接集群,创建RDD、accumulators 和广播变量。
第二段注释:Only one SparkContext may be active per JVM. You must stop() the active SparkContext before creating a new one. This limitation may eventually be removed; see SPARK-2243 for more details..告诉我们在每一个JVM中,仅仅只能有一个活跃的sparkcontext,你如果要启动一个新的,就得先关闭之前的。但是这个限制可能会在以后进行移除。
参数解释:config这个对象是描述程序配置的,自己写的config会覆盖默认的config作为系统的配置文件
源码:
private val creationSite: CallSite = Utils.getCallSite()
这个会在sparkcontext在被构造的时候进行,这个方法是在我们调用spark方法时,调用spark包内部的类的时候,返回一个用户自己写的代码类的名字
接着有一个allowMultipleContexts,这个就是说在程序中存在多个活跃的sparkcontext的时候,程序不会因为异常而终止,而是进行一个警告,这个放在sparkcontext构造器的前面。当同一时间有多个的时候,spark内部会进行Mark已经开始的context
spark内部先用一个现在时间定义一个starttime,在定义出一个状态码,给stopped里,然后就会去判断有没有活跃的sparkcontext,有的话就会抛出一个非法异常

接着,就是构造器了

接着就是一大堆的配置变量信息
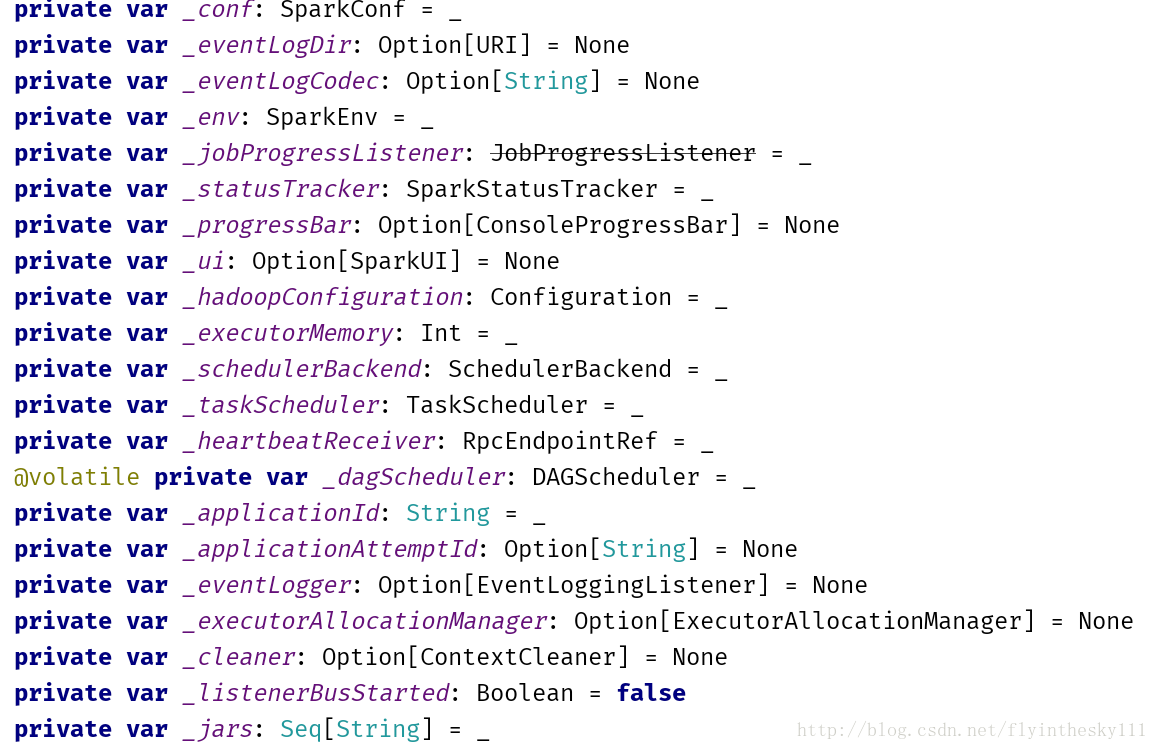
仔细看一下这里面的,你就会发现很多你认识的东西,例如hadoopConfiguration、executorMemory、taskScheduler、heartbeatReceiver、applicationId、dagScheduler等等
然后又定义了一个conf,这个conf是可以进行公告访问的,上面的一大堆变量信息都是在context的内部,并不会让外部接触到,所以,外部要想访问这些信息就必须再来一个conf,这个conf里面的信息是通过复制产生的

然后布拉布拉又从中获取了一大堆配置信息

这里需要注意的是,这些参数里比之前外界无法访问的参数中多出了两个参数
sparkUser和checkpointDir。前者告诉我们谁在运行这个sparkcontext,后者则是指明checkpoint的路径
紧接着,new了一个InheritableThreadLocal即可继承的本地线程来存放配置信息,做完这一步之后,就开始初始化sparkcontext了。
protected[spark] val localProperties = new InheritableThreadLocal[Properties] {内部实现}
对于初始化,作者给出了一段注释: Initialization. This code initializes the context in a manner that is exception-safe. All internal fields holding state are initialized here, and any error prompts the stop() method to be called.
这段解释告诉我们初始化是以一个异常安全的形式进行的。在初始化的时候,stop方法的任何错误提示都会被调用出来
关于异常安全有如下解释:
带有异常安全的函数:
1、不会泄露任何资源
2、不允许数据被破坏
异常安全函数(Exception-safe function)提供以下三个保证之一:
1、基本承诺:如果异常抛出,程序内任何事物仍保持在有效状态。不会有任何数据对象破坏。
2、强烈保证:如果异常招聘,程序状态不改变。调用强烈保证函数后,只有两种可能。即:函数成功则完全成功,否则回到“调用函数”之前的状态。
3、不抛出保证(nothrow):承诺绝不抛出异常。内置类型(如int 、指针等)身上都提供nothrow保证。
接着就是warn机制

接着就是我们常用的日志级别设置的方法

是不是很熟悉
接着就是判断config中包含的各种信息
比如master、APPname等等情况
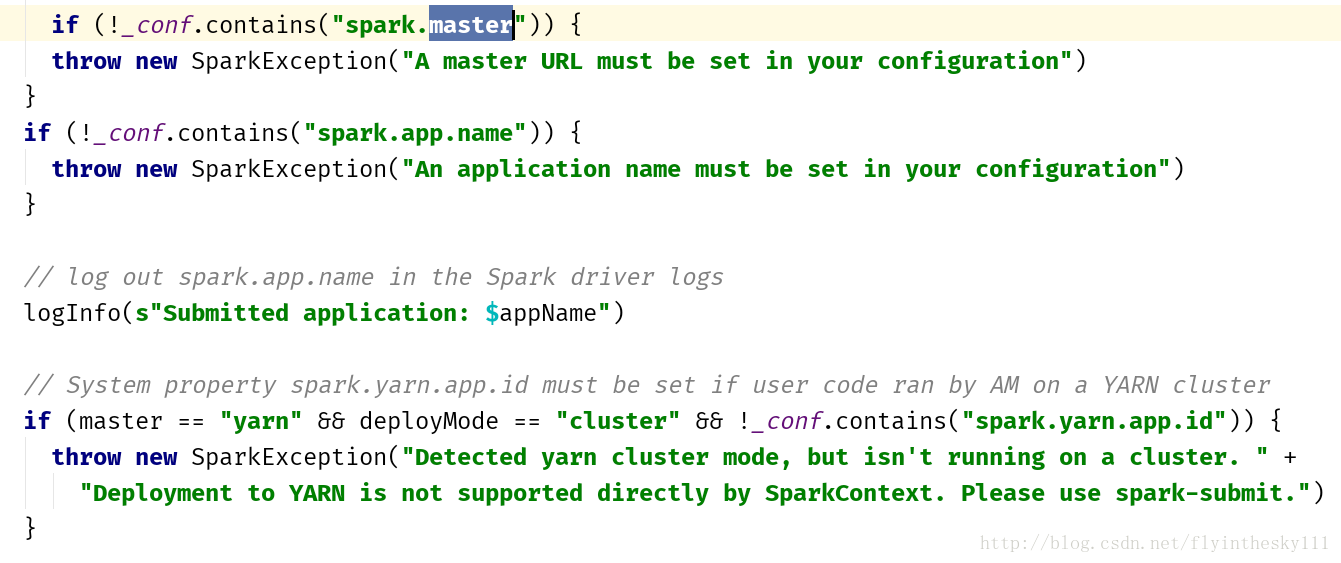
这一步过后,会set spark driver的host 和port信息,然后根据条件判断其他的各种信息。
好了先到这里,个人理解,仅限参考。后边有机会继续分享,大佬们看到不要笑,希望能够指出 不足,我也能及时更改。